En primer lugar, instale el requisito previo
avance Cluster instalado hadoop, colmena.
SCP paquetes de instalación de colmenas necesitan ser instalado en todos los nodos impala, debido a la necesidad de impala referencia dependencias de la colmena.
Hadoop necesidades marco interfaz de acceso a programa de apoyo C, ver la siguiente figura, hay tan archivo si el camino para demostrar que soporta la interfaz C.

En segundo lugar, descargar el paquete de instalación, dependencias
Dado que el impala no proporcionar el paquete de alquitrán está instalado, sólo el paquete rpm. Por lo tanto, cuando el impala de montaje, paquetes rpm necesitan ser instalados. paquete rpm sólo ofrece la compañía Cloudera, así que ve el sitio web de la empresa cloudera para descargar el paquete rpm.
Pero otra pregunta, impala otro paquete paquete rpm rpm depende mucho, uno puede encontrar a cabo dependerá, sino también todo el paquete rpm puede ser descargado, hecho en nuestra fuente local para instalar yum. Aquí elegimos para crear fuente de yum local para instalar.
Así que en primer lugar es necesario descargar el paquete rpm, descarga la siguiente dirección
http://archive.cloudera.com/cdh5/repo-as-tarball/5.14.0/cdh5.14.0-centos6.tar.gz
## Debido a cdh5.14.0-centos6.tar.gz paquete de descarga es muy grande, aproximadamente 5 g, después de la descompresión también requiere un mínimo de espacio para cinco G. Y nuestro disco máquina virtual está limitado, puede no ser suficiente, es posible montar un nuevo disco de la máquina virtual dedicada al almacenamiento paquete cdh5.14.0-centos6.tar.gz.
En tercer lugar, configurar el yum local de la fuente
1. Descomprimir el paquete Subir
tar -zxvf cdh5.14.0-centos6.tar.gz
rz sólo puede cargar datos en un plazo máximo de 4G, es necesario decirlo de otra manera, por ejemplo, cargar SSLClient.
2, para configurar el yum local de información de la fuente
Instalar el servidor Apache servidor
yum -y install httpd
service httpd start
chkconfig httpd on
3, configurar el archivo de origen local, yum
cd /etc/yum.repos.d
vim cdh.repo

Crear un enlace para leer el Apache httpd
ln -s /export/servers/cdh/5.14.0 / var / www / html / CDH
Asegúrese de que el linux selinux cerrada
临时关闭:
[root@localhost ~]# getenforce
Enforcing
[root@localhost ~]# setenforce 0
[root@localhost ~]# getenforce
Permissive
永久关闭:
[root@localhost ~]# vim /etc/sysconfig/selinux
SELINUX=enforcing 改为 SELINUX=disabled
重启服务rebootel acceso del navegador a través de una fuente de yum local, si hay éxito la página siguiente.
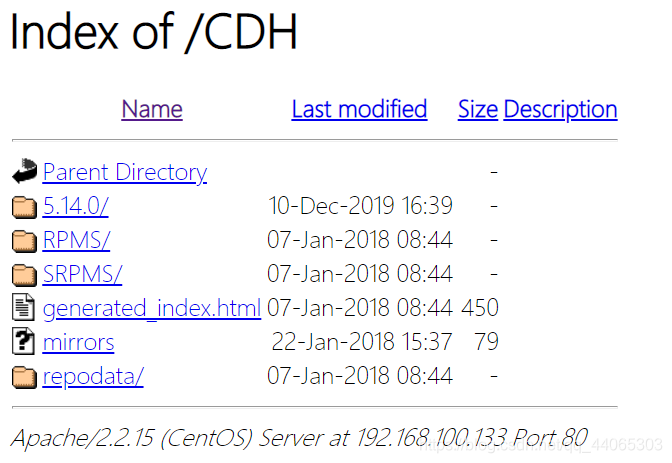
El perfil de origen local, yum distribuye localimp.repo a todos los nodos en la necesidad de instalar impala.
cd /etc/yum.repos.d/
SCP cdh.repo nodo 0 2: $ PWD
SCP cdh.repo Node0 3: $ PWD
En cuarto lugar, la instalación del impala
1, el plan de clúster
| Nombre del servicio |
desde el nodo |
desde el nodo |
El nodo maestro |
| impala-catálogo |
|
|
Nodo-3 |
| impala-estado-tienda |
|
|
Nodo-3 |
| impala-servidor (impalad) |
Nodo-1 |
Nodo-2 |
Nodo-3 |
En la planificación del nodo principal del nodo-3 instalado ejecutar los siguientes comandos:
yum install -y impala impala-server impala-state-store impala-catalog impala-shellEn la planificación de los ganglios linfáticos-1 , Nodo-2 instalar el siguiente orden:
yum install -y impala-serverEn quinto lugar, modificar Hadoop, la configuración de la colmena
3 máquinas necesitan para operar en todo el clúster , necesitan ser modificados. hadoop, si el servicio normal de la colmena y configurado, se decide si impala exitoso lanzamiento y uso de la premisa
1, la configuración de la modificación colmena
vim /export/servers/hive/conf/hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!-- 绑定运行hiveServer2的主机host,默认localhost -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node01</value>
</property>
<!-- 指定hive metastore服务请求的uri地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node01:9083</value>
<!-- 启动impala使用hive的时候要在这里指定的节点开启hive服务 -->
</property>
<property>
<name>hive.metastore.client.socket.timeout</name>
<value>3600</value>
</property>
</configuration>Cp configurar la colmena para las otras dos máquinas.
cd $ HIVE_HOME / conf
node02 SCP-colmena site.xml: $ PWD
node03 SCP-colmena site.xml: $ PWD
2, hadoop Modificar configuración
Todos los nodos crean la siguiente carpeta
mkdir -p / var / run / HDFS de enchufe
Modificar hdfs-site.xml todos los nodos añade la siguiente configuración cambios tengan efecto reinicie la agrupación después de completar hdfs
vim etc / hadoop / hdfs-site.xml
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/run/hdfs-sockets/dn</value>
</property>
<property>
<name>dfs.client.file-block-storage-locations.timeout.millis</name>
<value>10000</value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>dfs.domain.socket.path es un camino de comunicación entre DFSClient local y DataNode el zócalo. datos de control de lectura abierta locales dfs.client.read.shortcircuit DFSClient,
El archivo de configuración de actualización hadoop, SCP a otras máquinas.
cd $ HADOOP_HOME / etc / hadoop
scp -r hdfs-site.xml node02: $ PWD
scp -r hdfs-site.xml node03: $ PWD
Nota: el usuario root no tiene que operar por debajo, los usuarios normales necesitan este paso.
Conceder permisos a esta carpeta, si se utiliza un hadoop usuario normal, que da directamente privilegios de usuario normales, tales como:
chown -R hadoop: hadoop / var / run / HDFS de enchufe /
3, hadoop reinicio, Colmena
Realice el siguiente comando en node01 se iniciaron los servicios MetaStore colmena y Hadoop.
cd / $ COLMENA
nohup bin / colmena --service meta almacén y
nohup bin / colmena - hiveserver2 servicio y
cd / $ HADOOP_HOME
sbin / stop-dfs.sh | sbin / start-dfs.sh
4. Copiar el hadoop, el perfil de la colmena
directorio de configuración impala / etc / impala / conf, este camino necesidad de núcleo-site.xml, hdfs-site.xml y colmena-site.xml continuación.
Todos los nodos ejecutan el siguiente comando
cp -r /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/core-site.xml /etc/impala/conf/core-site.xml
cp -r /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/hdfs-site.xml /etc/impala/conf/hdfs-site.xml
cp -r /export/servers/hive-1.1.0-cdh5.14.0/conf/hive-site.xml /etc/impala/conf/hive-site.xml
En sexto lugar, modificar el impala configuración
1, modificar el impala configuración predeterminada
Todos los nodos cambian el perfil predeterminado impala
vim / etc / default / impala
IMPALA_CATALOG_SERVICE_HOST = nodo 0 3
IMPALA_STATE_STORE_HOST = nodo 03
SCP / etc / default / impala node02: $ PWD
SCP / etc / default / impala node03: $ PWD
2, para agregar controladores de MySQL
Al configurar el archivo / etc / default / impala se pueden encontrar en la ubicación ha sido impulsado nombre especificado MySQL.
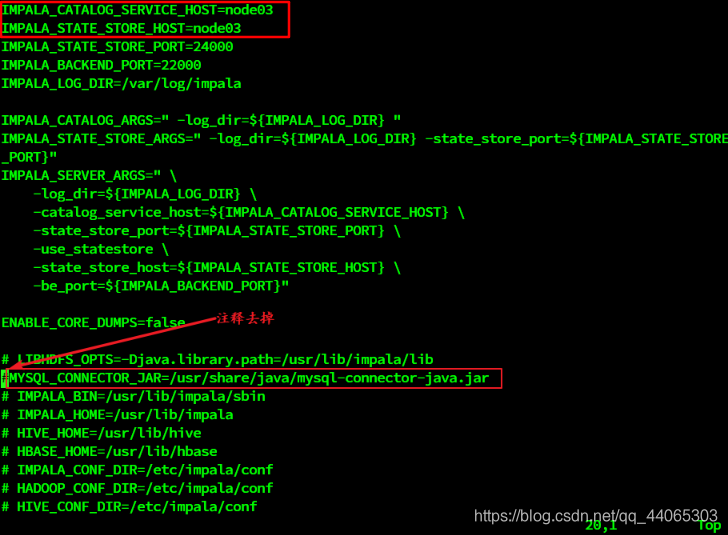
Utilizar un enlace simbólico a la ruta a (3 máquinas necesitan ser realizados)
Ln -s /export/servers/hive/lib/mysql-connector-java-5.1.32.jar /usr/share/java/mysql-connector-java.jar
3, modificar la configuración bigtop
JAVA_HOME bigtop ruta modificada (3 máquinas)
vim / etc / default / bigtop-utils
export JAVA_HOME = / export / servidores / jdk1.8.0_65
Siete, puesta en marcha, servicio de desactivación de impala
El nodo 3-nodo maestro inicia el siguiente proceso de tres servicios
puesta en servicio impala-estado-tienda
puesta en servicio impala-catálogo
puesta en servicio impala-servidor
Start nodo 1 y el nodo 2-promotor impala-servidor desde el nodo
puesta en servicio impala-servidor
existe proceso de vista impala
ps-ef | impala agarre

Después de iniciar todo sobre el impala por defecto de registro en / var / log / impala
Si es necesario apagar el comando service impala para iniciar la parada puede ser. Tenga en cuenta que después de que el proceso de apagado si todavía residen, se puede tomar la siguiente manera de quitar. En circunstancias normales, con la desaparición de cerca.
solución:

impala interfaz de usuario web
gestión de acceso Impalad interfaz http: // nodo-3: 25.000 /
gestión de acceso Statestored interfaz http: // nodo-3: 25.010 /
