Un Cluster Edition
- significado del clúster
- principios de la PAC
- sistema de agrupación
En este último caso, simplemente introdujo el uso Redis, la siguiente es Redis próxima vez que el entorno de clúster.
significado del clúster
Redis grupo está obligado a aparecer para resolver el problema no se puede resolver sola, ¿qué pregunta, simplemente resumir de la siguiente manera:
- En el entorno autónomo, si una instancia Redis no está disponible, o no está disponible en todos los casos, ya sea Redis como caché o como una base de datos para su uso, están obligados a causar un gran impacto en el negocio, la probabilidad de un único punto de fallo de la máquina es muy alta.
- Redis aplicación como operaciones de memoria puros, sujeto a la limitación del sistema operativo, la memoria no puede ser la expansión ilimitada, si necesitamos decenas de datos de caché de cientos de G, entorno independiente no puede proporcionar soporte
- Stand-alone rendimiento de la máquina en una muy buena situación, QPS oficial en 10-15w, pero teniendo en cuenta que hay muchos sub-tarea roscado, en general, debe ser inferior a 10W, independientes pueden no soportar entornos de alta concurrencia.
principios de la PAC
También conocido como teorema de CAP, que es, en un sistema distribuido, la consistencia (consistencia), disponibilidad (disponibilidad), la tolerancia de reparto (particiones tolerancia a fallos), los tres no puede tener ambos. Por ejemplo, fuerte consistencia y la disponibilidad son una pareja de amantes, no pueden coexistir, se introducirá la siguiente. Redis se implementa clúster AP.
sistema de agrupación
1. resolver el punto único de fallo
Dado que una máquina no es fiable, sería hacer más de una cosa unos pocos. la escala horizontal del servidor Redis no es una cosa para resolver el problema, mientras que convenientemente deslizarse hacia abajo para resolver los problemas de rendimiento: 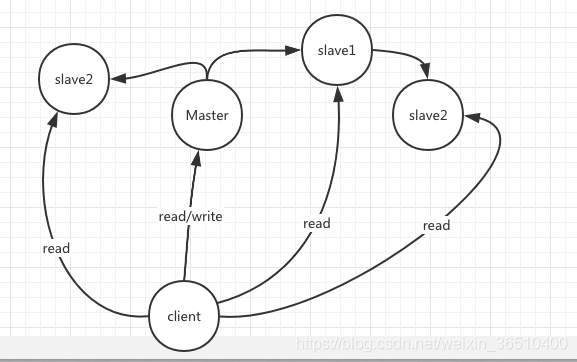
un plug-n Maestro mesa de ungüento, pomada cada bodega teóricamente una cantidad principal total de los datos, lo que equivale a Maestro de n espejo, cuando después de que el Maestro abajo, esclavo todavía puede contener datos completos de prestación de servicios, sino también el apoyo de lectura y escritura por separado, creo que hay un poco excitado al respecto.
En primer lugar, explicar dos términos:
- De maestro
sencillo de entender, es decir, el cliente puede conectarse al host, y también se puede conectar desde - En espera
del equipo, es decir, la máquina de copia de seguridad, el cliente no puede conectarse al servidor de copia de seguridad, solamente después de sacar el anfitrión, la máquina de preparación alternativo función de anfitrión puede conectar
Por lo general, el anfitrión puede leer y escribir sólo lectura de la máquina.
Viene con nuevos problemas
consistencia
calma abajo, cómo hacer que cada dueños de esclavos de datos completa? surgen problemas de consistencia de datos así, el siguiente diagrama simplificado de otro ejemplo:
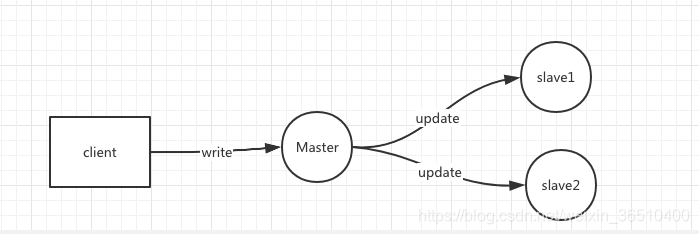
datos de cliente se escriben en un Matser, entonces Maestro de sincronización de datos tanto a esclavo. Supongamos ahora esclavo1 recibir una solicitud de sincronización y la sincronización completa de los datos, la red de esclavo2 debido a fluctuaciones en los EE.UU. y Europa simplemente recibir la petición, o recibidos ligera, pero se produce un error durante la sincronización de datos, la sincronización real no se ha completado, por lo que ahora ha habido tal situación, cuando el Maestro y SLAVE1 los datos más recientes, pero esclavo2 simplemente no tendrán estos datos. Supongamos que la actual situación de emergencia, Maestro y esclavo1 están abajo, dejando sólo la esclavo2 puede proporcionar servicios en este momento, estos nuevos datos se inserta tan perdido.
Dado que el nivel de expansión ha habido algunos problemas, simplemente subirse las mangas y hacerlo hacia abajo. Generalmente, hay tan pocos programas (contenidos pertenecientes a las siguientes extensiones que se extienden):
consistencia sólida
Bien entendido, o tres máquinas todos tienen éxito, o todos fallan. Ahora cliente envía un comando de escritura al Maestro, Maestro está escrito con éxito, los dos esclavos siguiente para Sincronizar datos porque Redis es un solo proceso, con el fin de lograr una consistencia fuerte, Maestro sólo puede ser bloqueada a la espera de los resultados de sincronización de dos esclavos, si ambos están exitosa respuesta Maestro, bien, una vez que se haya completado la escritura. Si la sincronización aviso esclavo1 se ha completado, la notificación esclavo2 falla, o la mitad de un día más tarde, ningún resultado sincronización dado que el maestro sólo puede creer que esta sincronización ha fallado, por consistencia fuerte, ya sea juzgado de nuevo o que los datos han sido revocado con éxito. Sin embargo, si los datos de revocación, o reintento (esta vez el mensaje ha bloqueado aún) para el cliente en términos de servicio equivalente no está disponible. Por lo tanto, la visión es muy bonito, pero el costo es demasiado grande un daño grave a la disponibilidad.
consistencia débil
Dado que la disponibilidad de la forma que sea muy aprensivo, desde luego, no puede utilizar síncrono bloqueado, oye, se reemplaza con el canto notificación asíncrona. Después de los datos del cliente llega Maestro, Maestro éxito en la línea, y dos notificación asíncrona esclavo Maestro de sincronización de datos, pero no puede garantizar que los datos de dos esclavo es totalmente coherente y Maestro.
La consistencia final
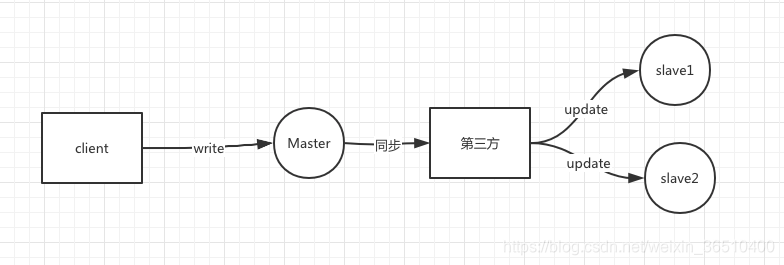
Se puede considerar si hay un tercero confiable, Sincronizar datos Maestría (la respuesta debe ser lo suficientemente rápido), para obtener la sincronización de datos de terceros después de la recepción exitosa, esclavo1, funcionamiento síncrono esclavo2 específica, asíncrono por un tercero para la actualización, asegúrese de que la final dos esclavos pueden actualizar.
La pregunta lee datos
Después de Redis lectura y escritura por separado, en el supuesto de datos maestros se ha actualizado, pero el esclavo no ha tenido tiempo para completar la actualización. Dos de cliente existente, una lectura de datos desde el maestro, la lectura de datos desde un esclavo, terminado, una nueva técnica ha sido leído, el otro es para leer los datos antiguos.
Maestro problema de un solo punto
Ya se trate de un maestro-esclavo o maestro y el esclavo, son inseparables de un Maestro de acogida, la pregunta es, el Maestro mismo, o una máquina de un solo punto, volver al origen del problema ...
Redis es cómo lograrlo?
De un solo punto maestro resolución de problemas
Imagínese si una persona, la forma de determinar si un maestro están disponibles? Muy simple, establecer la comunicación con el Maestro, Maestro determinar si el servicio puede ser proporcionado. A continuación podrá presentar la próxima Sentinel (Sentinel) R:
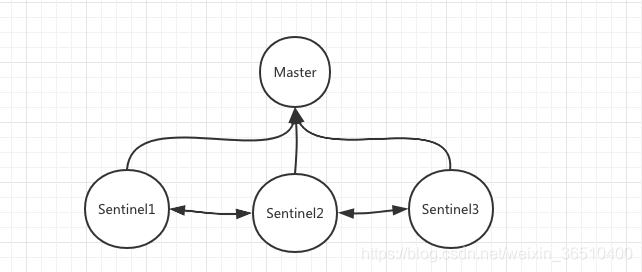
Creo que es elegante usted debe haber notado anteriormente centinela dibujé tres, ¿por qué no uno, ni dos?
En primer lugar, hay que definir el significado de la existencia Sentinel, es un único punto con el fin de resolver el problema del Maestro, dice sin rodeos, es para controlar el actual Maestro está vivo, puede proporcionar servicios.
Supongamos ahora que un Maestro es sólo una vigilancia centinela, si las fluctuaciones de red entre un cierto punto en el tiempo con el Maestro Sentinel, Sentinel piensan abajo Maestro, iniciar la recuperación de desastres, se convertirá en un nuevo interruptor maestro-esclavo, de hecho, el bueno de Maestro, ¿cuál dando lugar a un problema típico partición de red, parte de la conexión y aún así mantenerse en contacto con el viejo maestro, que forma parte de la nueva conexión y el nuevo maestro interactúan inconsistente.
Dado que sólo un centinela factible, además de un centinela qué va a pasar? Si un problema de conexión de centinela en algún momento, a juzgar problemas maestro, y otro centinela y Master mantiene conexión normal, buen Maestro juicio, por un pensamiento, un pensamiento y no hay problema, en el extremo que para escuchar a ella? Obviamente, sólo dos centinelas ni factible.
Al menos tres guardias para vigilar un Maestro, cuando más de la mitad el número de +1 centinelas pensar Maestro abajo, y ese es el número de votos superior a la mitad de la corriente Sentinel, antes de que puedan pensar Master es realmente abajo, y recuperación de desastres deben poner en marcha.
Sentinel acerca de esto, esta sección no se propaga en términos de la sección especial seguimiento detallado centinela si el trabajo es, cómo iniciar el rescate.
aplicación Redis
Aquí tenemos un poco simple mirada de demostración en Redis es cómo lograr la sincronización de datos:
Medio ambiente: Mac OS
herramientas: cáscara, cargador de muelle (soy perezoso, no quiero configurar una gran cantidad de cosas, el uso del contenedor ventana acoplable configuración por defecto)
Descripción: Este Redis de demostración utilizando la configuración por defecto, modificar el resultado de configuración, esta demo será un poco diferente.
1. En primer lugar, crear un entorno de clúster Redis en la simulación de la máquina. En primer lugar empezar a cuatro cáscara vacía:
2. 4 una cáscara de izquierda a derecha, respectivamente, entre el mandato siguiente (para demostrar el efecto, dejamos que el extremo frontal bloqueado instancia en ejecución Redis):
左上:
docker run --name master -p 6379:6379 redis
右上:
docker run --name slave1 -p 6380:6380 redis
左下:
docker exec -ti master redis-cli
右下:
docker exec -ti slave1 redis-cli
El efecto es el mismo:

hemos lanzado con éxito dos instancias Redis, un 6379, un 6380,
lanzados simultáneamente dos clientes, una instancia de conexión 6379, un ejemplo de conexión 6380
Además, debido a la ventana acoplable mecanismo de caja de arena no es la comunicación entre los dos recipientes, construimos un puente para la siguiente comunicación bidireccional entre instancias:
docker network create -d bridge myBridge
docker network connect myBridge master
docker network connect myBridge slave1
bien, hasta el momento, los preparativos se han completado.
3. Demostrar, añadimos ahora la sección 6379 Clave:

4. El 6380 se establece en 6379 esclavo está
conectado al cliente 6380 utilizado en el comando siguiente:
replicaof 172.17.0.2 6379
bien, terminado, ahora vemos la interfaz de pantalla de cuatro cáscara

de la concha del Maestro, Maestro podemos ver después de una conexión exitosa de esclavos, por lo que algunas cosas: el uso del modo de copia en escritura, la nueva obra un subproceso de fondo 23 lleva bgsave (es decir, la cantidad total del archivo generado RDB en el Master actual), después de la finalización del archivo RDB con el comando de sincronización se envía al esclavo.
En el esclavo cáscara, podemos ver que, después de establecer una conexión con el Maestro, comenzado a construir canal de sincronización, enviar un ping al Maestro para verificar la conexión es lisa, después de recibir un conjunto de datos maestro RDB enviados desde el primer claro sus datos antiguos, RDB entonces cargar los datos en la memoria.
Nos fijamos en los resultados:
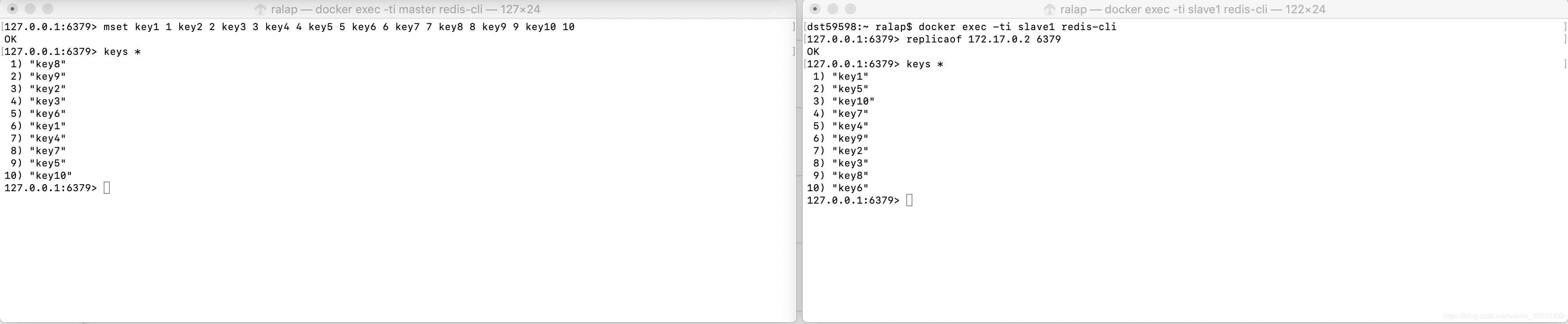
Hasta ahora, entre maestro y esclavo, para completar una sincronización completa del volumen de datos.
La sincronización de datos incrementales:
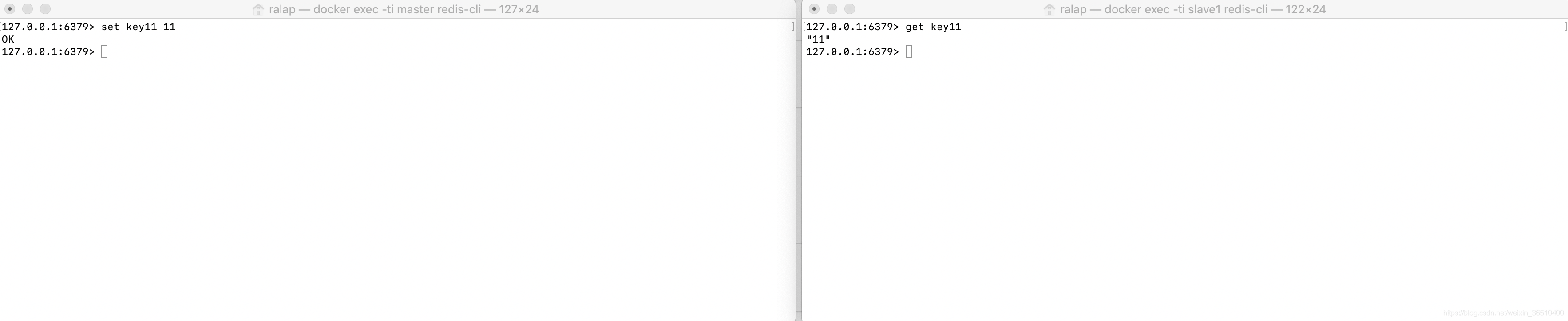
A continuación, añadir en Master en un key11, y luego ir al esclavo vista, se puede ver key11 se ha sincronizado a la esclava en
A continuación resumimos Redis lógica de replicación maestro-esclavo:
- La cantidad total de la sincronización de datos:
el uso general de la nueva conexión en la escena como maestro esclavo, o esclava hacia abajo por un largo tiempo, después de la reconexión de recuperación con el Maestro.
Se requiere que la cantidad total de la sincronización de archivos a utilizar RDB, el valor predeterminado es la primera generación de RDB archivos almacenados en el disco, y así sucesivamente todos los documentos generados después de RDB se completa, luego se envía al esclavo. Por lo tanto, el rendimiento está limitado por la velocidad del disco, se pueden añadir a la configuración en conf: repl-sin disco de sincronización no, el archivo de disco RDB generado no cae envía directamente sobre la red en la forma de un esclavo.
En cuanto al proceso de sincronización de datos, por encima de la demo ya cuenta con un proceso detallado aquí es no hacer demasiado explicó.
Además, señalan, borrar los datos antiguos en su propio esclavo, el proceso de carga de nuevos datos, el valor predeterminado es para ser bloqueado, se puede configurar de forma asíncrona en el conf, durante este tiempo, esclavo todavía responder a la solicitud, y vuelve a datos antiguos, pero la carga de nuevo conjunto de datos de operar sólo en el hilo principal puede bloquear ungüento. - sincronización incremental:
sincronización incremental de comparación con la cantidad completa de sincronización, un poco más complicada.
Nos fijamos en lo que son los próximos Maestro y esclavo información:
entrar en "información de replicación"
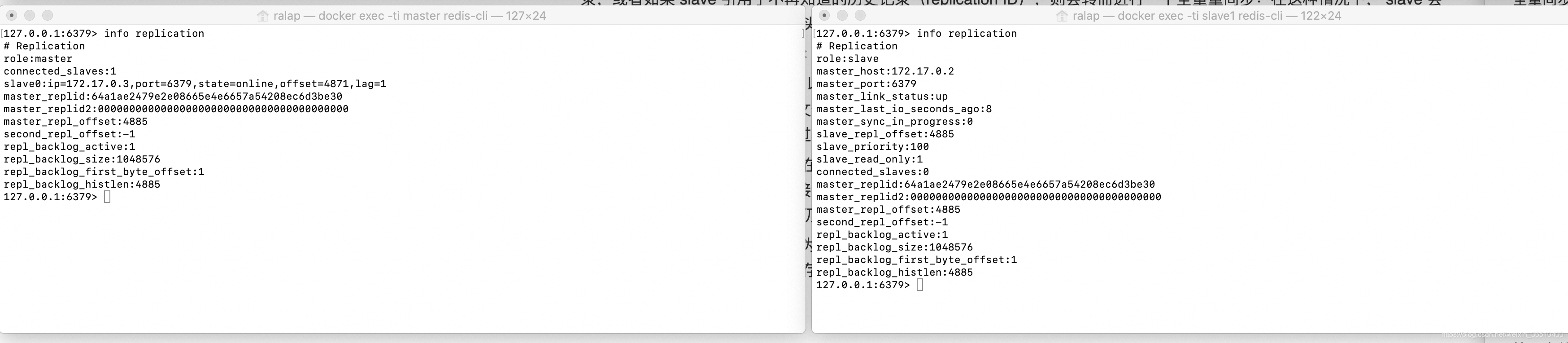
Podemos ver que en el Master, existe actualmente ID propio de replicación, así como sus propios datos offset, y el esclavo, no sólo tiene su ID de replicación, así como Maestro de Replid y Maestro de offset, que es la información de la última sincronización de datos principal.
Cuando la copia maestra de sí mismo a la corriente esclavo, cuántos bytes de datos enviados desde el compensados en sí aumentarán en número, cuando un nuevo objeto es modificar el funcionamiento de su propio conjunto de datos, que puede ser utilizado para actualizar el esclavo compensado estado. Sustancialmente cada uno de los ID de replicación y offset, puede determinar una versión exacta de los datos.
Cuando salve conectado al Maestro, utilice el comando enviado psync viejo maestro de la replica de su contrato de grabación y los compensado hasta ahora, así Masetr puede saber qué datos deben comenzar desde, y su sincronización de datos de seguimiento al esclavo
Supongamos que un problema de este tipo, si el tiempo de sincronización reciente esclavo es una hora antes, en esta hora, los datos maestros 4G ha sido actualizado, y de nuevo cuando la sincronización esclavo del tiempo, por lo que si o sincronizarlo? La respuesta no lo es.
A partir de la tabla anterior, podemos ver un mensaje "repl_backlog_size" se llama, este es el Maestro de la memoria intermedia de comando de operación, el tamaño de esa puede ser configurado para facilitar la comprensión, se puede pensar en él como un espacio de memoria del anillo:
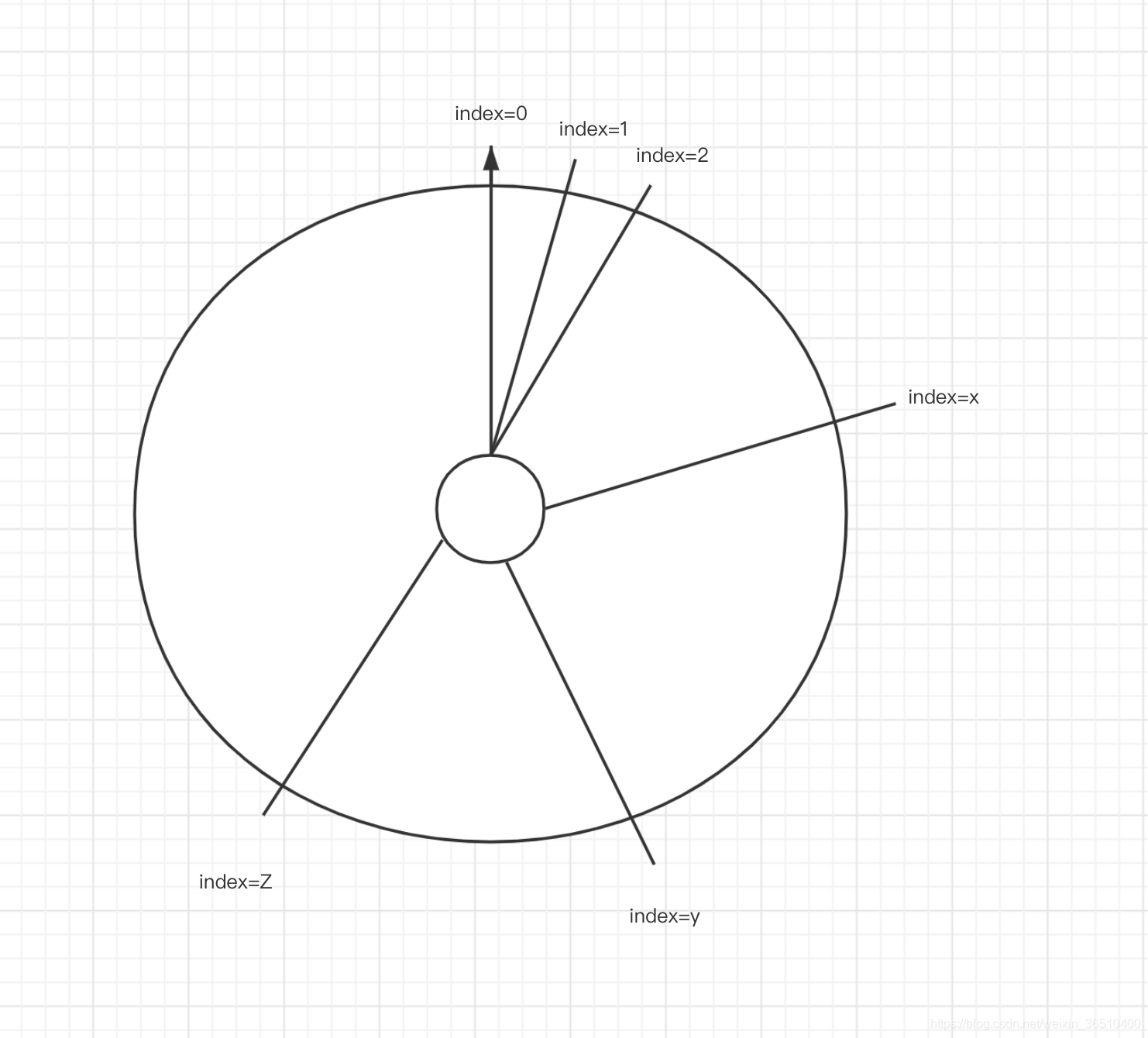
a partir index = 0, a una instrucción, los datos para llenar el anillo interior, toda la memoria circular hasta que esté lleno, un comando posterior de nuevo, donde el índice = 0 antes del inicio de la instrucción más antigua para reemplazar las nuevas instrucciones.
Cuando la información de desplazamiento esclavo lleva encima, Maestro basa en el desplazamiento, para encontrar el comando correspondiente en el búfer de desplazamiento, si se encuentran en la memoria intermedia, que es seguir el esclavo de sincronización de instrucciones, si no se encuentra en el búfer correspondiente offset, la cantidad total de datos se lleva a cabo la sincronización de RDB.
El modo por defecto es, el modo de lectura-escritura se puede ajustar por conf el esclavo sólo lectura.
el modo maestro-esclavo, Redis, ya que es la replicación asíncrona, no es posible asegurar que se reciben los datos de cada esclavo, siempre habrá pérdida de datos, es necesario ver si esta escenarios de uso específicos pueden tolerar, la tolerancia PubMed partición de la red.
Además, la consistencia de la porción de soporte Redis, disponiendo:
min Réplicas-a-Write-XXX
min-max-LAG-XXX Réplicas
conjunto mínimo de datos esclavo de escritura exitosas, y el máximo tiempo de espera de la comunicación entre sí. Por ejemplo, XXX configurado como 3, sólo cuando al menos tres ungüento haber escrito correctamente, estos datos se considerará exitosa de escritura y, finalmente, en el conjunto de datos Redis.
1. Capacidad para resolver problemas Redis
El espacio es limitado, para explicar en los capítulos siguientes partición Redis, así que estad atentos.
