tipos de datos básicos
documentación del usuario Palabos Capítulo VI de
(一) estructuras de datos El BlockXD
El documento original
Las estructuras de datos fundamentales que sostienen las variables de una simulación son de tipo Block2D para 2D simulaciones, y del tipo Block3D para la simulación (en lo que sigue, se utiliza el nombre genérico BlockXD para mantener el breve discusión, aunque no existe ningún tipo de BlockXD en Palabos ). Desde el punto de vista de un usuario, un constructo BlockXD representa una matriz regular 2D o 3D (o matriz) de datos. Detrás de las escenas, a veces son realmente implementan como matrices regulares y construcciones a veces como más complicado, lo que permite un ahorro ejemplo de memoria a través de las implementaciones de memoria escaso, o ejecuciones de programas paralelos basados en un modelo de datos en paralelo.
El BlockXD estructuras son especializado para diferentes áreas de aplicación. Un tipo de especializaciones se utiliza para especificar el tipo de datos almacenados en los bloques. Para almacenar las poblaciones de partículas de un enrejado de simulación de Boltzmann, y potencialmente otras variables como las fuerzas externas, que va a utilizar una especialización en la que el nombre del bloque se sustituye por BlockLattice. Para almacenar una variable escalar espacialmente extendida, el tipo de datos a utilizar es una variante de la ScalarFieldXD, mientras que por vectores o campos tensoriales de valor se almacenan en un TensorFieldXD o similar. Un segundo tipo de especialización se aplica para especificar la naturaleza de la estructura de datos subyacente. La estructura de datos AtomicBlockXD destaca esencialmente por una matriz de datos regular, mientras que el MultiBlockXD es una construcción compleja en la que el espacio que corresponde a un BlockXD está cubierta parcial o totalmente por bloques más pequeños de tipo AtomicBlockXD. El MultiBlockXD y la AtomicBlockXD tienen prácticamente la misma interfaz de usuario, y se les insta a utilizar sistemáticamente el MultiBlockXD más general en aplicaciones de usuario final. Es casi tan eficiente como el AtomicBlockXD para los problemas habituales, que puede ser utilizado para representar dominios irregulares, y es automáticamente paralelizable.
La siguiente figura ilustra el C ++ jerarquía de herencia entre las diversas especializaciones de la BlockXD:
La figura muestra, como ejemplo, unas pocas funciones implementadas en cada nivel de la jerarquía de herencia. Por ejemplo, todos los bloques de tipo “bloque de celosía” tienen un collideAndStream método (), sin importar si se implementan como un multi-bloque o un bloque atómico. De la misma manera, todos los multi-bloques tienen un getComponent método (), no importa si son del tipo de bloque-celosía, escalar-campo, o tensor de campo. La situación que se muestra en esta figura se conoce como “herencia múltiple”, porque las clases de los usuarios finales heredan de BlockXD de dos maneras: una vez a través de la ruta de acceso multi-bloque atómico vs., y una vez a través del bloque-celosía vs. scalar- vs ruta-campo de tensores. Tenga en cuenta que la herencia múltiple es a menudo considerado como una mala práctica, ya que puede dar lugar a código propenso a errores; en el presente caso, sin embargo,
Traducción de documentos
Guardar las estructuras de datos básicos utilizados para los valores de variables de simular, hay dos tipos de Block2D tipo Block3D simulación 2D y para la simulación (a continuación, se utiliza el nombre genérico BlockXD para mantener una breve discusión, aunque el tipo Palabos no existe BlockXD). Desde la perspectiva del usuario, BlockXD datos que representan una estructura de un 2D convencional o una matriz 3D (o matriz). Detrás de las cámaras, a veces se implementan como una matriz regular, y, a veces implementan como una construcción más compleja, como guardar en la memoria se consigue mediante una memoria escasa, o modelo paralelo basado en los datos de ejecución del programa paralelo.
estructura BlockXD específicamente para la aplicación de diferentes ámbitos, un tipo especializado para el primer tipo de datos especificados en el almacén de bloque. Almacenamiento de red de Boltzmann simulación de enjambre de partículas, y posiblemente otras variables, tales como la fuerza, se utiliza una estructura BlockXD especializado, que será el nombre de bloque BlockLattice reemplazado. Para extender las variables escalares de espacio de almacenamiento, tipos de datos son variante ScalarFieldXD, la magnitud del vector o tensor de campo almacenado en TensorFieldXD o tipos de datos similares. El segundo tipo se utiliza para especificar la naturaleza especializada de las estructuras de datos subyacentes. AtomicBlockXD representante de la esencia de una estructura de datos convencional de la matriz de datos, MultiBlockXD es una estructura compleja, en la que la porción más pequeña del bloque por un espacio que corresponde a tipo BlockXD AtomicBlockXD o cobertura completa. MultiBlockXD y AtomicBlockXD en realidad tienen la misma interfaz de usuario, le recomendamos que utilice sistemáticamente más genérico MultiBlockXD en la aplicación del usuario final. Para los problemas convencionales, y es casi tan AtomicBlockXD eficaz, que puede ser utilizado para representar un campo irregular, es de forma automática y en paralelo.
La siguiente figura muestra un diagrama de jerarquía de herencia C ++ entre las diferentes especialidades BlockXD:

Como un ejemplo, la figura muestra la realización de varias funciones de cada capa en la jerarquía de herencia. Por ejemplo, todos los tipos de "bloque-celosía" del bloque tiene un método collideAndStream (), si son de bloque o una pluralidad de bloques atómica implementado. Del mismo modo, todos los bloques tienen un método pluralidad getComponent (), si son bloque rejilla, escalar o tensor de campo tipo de campo. Mostrar el dibujo se llama "herencia múltiple", porque el usuario final de dos maneras de la clase de herencia BlockXD: una pluralidad de caminos por átomo, a través de un escalar bloque de rejilla y tensor camino campos. Tenga en cuenta que la herencia múltiple generalmente se considera una mala práctica, ya que conduciría al código propenso a errores, sin embargo, en las actuales circunstancias, tenemos una experiencia positiva en el gráfico de la herencia se muestra arriba, porque es fácil de usar y representan dos aspectos BlockXD de una manera natural.
explicación
Cada caso requiere New Block-enrejado BlockXD clase subordinada, en el que BlockLatticeXD como una rejilla de celosía monolítico campo de la computación, no paralela, la versión de la clase MultiBlockLatticeXD paralelo, implementado por un bloque de dominio computacional paralelo, de acuerdo con los procedimientos de la clase conjunto Auditoría paralelo, se formará la lista de punteros BlockLatticeXD correspondiente dentro de la clase en cada objeto declarado. En general, cuando se utilizan las clases MultiBlockLatticeXD, sólo es necesario para proporcionar el tamaño del dominio computacional y una clase dinámica de fondo para ello (es decir, clase dinámica por defecto), de la clase dinámica puede ser compartida con el fin de reducir el consumo de memoria, el puntero se encuentra dentro de la clase una referencia a la clase dinámica dirección almacenada, inicialización de objetos MultiBlockLatticeXD debe ser declarada en el nuevo montón cuando un objeto de clase dinámica, que es una nueva clase de objeto dinámica, la dirección del puntero de entrada.
La siguiente declaración es un objeto de la sintaxis, Nx, Ny se calculan como el tamaño del dominio, una nueva clase BGKdynamics zona montón, el puntero como un argumento para el objeto de celosía. <T, DESCRIPTOR> como un parámetro de plantilla, será introducido en la siguiente sección.
MultiBlockLattice2D<T, DESCRIPTOR> lattice(Nx, Ny, new BGKdynamics<T,DESCRIPTOR>);
Sobre la base de los hereda de la clase única figura colores estándar de clase terminal puede ser utilizado, no puede utilizar otras clases, las clases abstractas pertenecen, no pueden ser instanciadas.
(二) del enrejado descriptores
El documento original
construcciones Todo BlockXD están a plantillas con respecto al tipo de datos subyacente. En la práctica, esta función se utiliza para cambiar entre precisión simple y doble precisión aritmética cambiando sólo una palabra en el programa de usuario final:
// Construct a 100x100 scalar-field with double-precision floating point values. MultiScalarField2D<double> a(100,100); // Construct a 100x100 scalar-field with single-precision floating point values. MultiScalarField2D<float> b(100,100);Block-celosías tienen adicionalmente un parámetro de plantilla, el descriptor de celosía, que especifica algunas propiedades topológicas de la red (el número de poblaciones de partículas, las velocidades discretas, los pesos de las direcciones, y otras constantes de red). Por tanto, es fácil de probar diferentes entramados en una aplicación:
// Construct a 100x100 block-lattice using the D3Q19 structure. MultiBlockLattice2D<double, D3Q19Descriptor> lattice1(100,100); // Construct a 100x100 block-lattice using the D3Q27 structure. MultiBlockLattice2D<double, D3Q27Descriptor> lattice2(100,100);También es fácil escribir un nuevo descriptor de celosía (esto no está documentada, pero se puede ver los archivos en el directorio src / latticeBoltzmann / nearestNeighborLattices2D.h para ver cómo funciona). Esto es muy útil, ya que significa que no es necesario volver a escribir las partes de código largo para la implementación de un BlockLatticeXD cuando se cambia a un nuevo tipo de celosía. Este argumento es parte de un concepto general que se describe en la sección de desarrollo del programa no intrusiva con Palabos.
Traducción de documentos
Todo BlockXD están configurados de acuerdo con la plantilla del tipo de datos subyacente. En la práctica, esta función se utiliza para cambiar la precisión simple y la aritmética de doble precisión, sólo el usuario final cambia una palabra en el programa:
// 构建一个 100x100 的双精度浮点值的标量场
MultiScalarField2D<double> a(100,100);
// 构建一个 100x100 的单精度浮点值的标量场
MultiScalarField2D<float> b(100,100);
Block-enrejado parámetro de plantilla y un enrejado descriptores descriptor, que especifica el número de propiedades topológicas de rejilla (número de partículas, la velocidad discreta derecha, dirección, el peso y otras constantes de red). Utilizar un formato diferente en una aplicación es muy fácil:
// 构建一个 100x100 块格结构使用 D3Q19 描述符
MultiBlockLattice2D<double, D3Q19Descriptor> lattice1(100,100);
// 构建一个 100x100 块格结构使用 D3Q27 描述符
MultiBlockLattice2D<double, D3Q27Descriptor> lattice2(100,100);
Escribir un nuevo descriptores de celosía es también muy fácil (no hay documentación, pero se puede ver el latticeBoltzmann / nearestNeighborLattices2D.h directorio de archivo src / para ver cómo funciona). Esto es muy útil porque significa que cuando se cambia a un nuevo tipo de célula, no es necesario para poner en práctica BlockLatticeXD reescribir la sección de código largo. Esto es parte del desarrollo de Palabos procedimiento no invasivo se describe en la sección del concepto general.
explicación
Esto significa que parte de los descriptores de celosía, es necesario especificar los descriptores de celosía declaradas en el cálculo de los bloques de dominio objeto de entramado estructura, los descriptores de celosía, es decir, una estructura celular CELULAR predeterminada de los datos en el descriptor, que contiene, número de cantidad de datos celular incluido en el valor de desplazamiento y los diferentes datos, que generalmente se aplican a los valores de datos celulares seleccionados requeridas por el valor de desplazamiento. Descriptor es en realidad proporciona una tabla estructura celular continua, como una tabla de valores de datos de la tienda.
En circunstancias normales, la fundación, como los dos anteriores se pueden cambiar fácilmente el juego, pero los modelos más avanzados, todos tienen sus propios descriptores de celosía, el nuevo modelo a la intemperie, para ver los descriptores de celosía, de manera que más o menos desbloqueo estructura de datos de cuadrícula que ha calculado, que generalmente comprende varias partes, con el modelo existente simple, siempre que el descriptor de celosía a juego, y un procesador de datos de acuerdo con la forma original de clase dinámica, por lo general no es un problema.
Los descriptores de celosía pueden escribir su propia, pero, ah, no he tenido tiempo de probar, por lo general miré, tres están generalmente sumergidos desarrollaron una escritura, es decir, los descriptores de celosía, clase dinámica y un procesador de datos.
(三) Las clases de dinámica
El documento original
Durante un tiempo de iteración de un enrejado de simulación de Boltzmann, todas las células de un bloque de celosía realizar un paso de colisión local, seguido de una etapa de streaming. El paso de transmisión está codificado y puede ser influenciado solamente por la definición de las velocidades discretas en un descriptor de celosía. El paso de colisión por el contrario puede ser totalmente personalizado y puede ser diferente de una célula a otra. De esta manera, la naturaleza de la física simulada en la red se puede ajustar de forma local, y áreas específicas, tales como los límites puede conseguir un tratamiento individual.
Cada célula de un bloque de celosía tiene, adicionalmente a las variables de la simulación, un puntero a un objeto de tipo Dinámica.
Para aprender cómo definir una nueva clase dinámica, es más fácil mirar a una de las clases definidas en Palabos. Por ejemplo, la dinámica BGK está definido en el archivo src / basicDynamics / isoThermalDynamics.hh. Un ejemplo bueno para la dinámica de compuestos (una clase que modifica el comportamiento de otro, existente clase dinámica) es la dinámica Smagorinsky, definidas en src / complexDynamics / smagorinskyDynamics.hh.
Para la aplicación de la colisión, el objeto de la dinámica obtiene una referencia a una sola célula; por lo tanto, la etapa de colisión es necesariamente local. Ingredientes no locales de una simulación se implementan con procesadores de datos, como se muestra en la siguiente sección.
Al igual que el bloque de celosía, un objeto de la dinámica depende de dos parámetros de plantilla, uno para la representación de coma flotante, y uno para el descriptor de celosía. Mediante el uso de la información proporcionada en el descriptor de celosía, el paso de la colisión debe ser escrito de una manera genérica, enrejado independiente. Es evidente que hay una compensación eficiencia en la escritura de los algoritmos de una manera genérica, ya que es posible formular optimizaciones para enrejados específicos que el compilador no logra encontrar. Este problema puede evitarse mediante el uso de especializaciones de plantilla para una celosía dada. A modo de ejemplo, tomar de nuevo la aplicación de las BGKdynamics clase. La realización de la etapa de colisión se refiere a un genérico dynamicsTemplates objeto, que se definen en el archivo src / latticeBoltzmann / dynamicsTemplates.h.
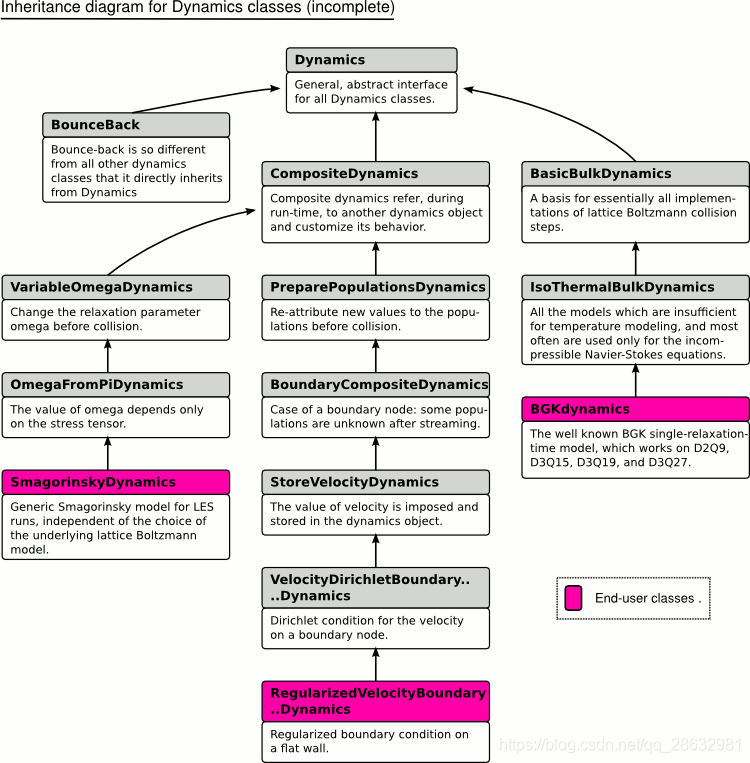
Traducción de documentos
Enrejado Boltzmann simulación iteración tiempo, todas las unidades de realizar el paso parcial de colisión bloque-red, y a continuación, realizar el flujo de paso. Corriente de paso estén codificadas, solamente mediante la definición de la retícula descriptores impacto velocidad discreta. Por otra parte, el paso de la colisión puede ser totalmente personalizado, y puede variar dependiendo de la célula. Así, en las propiedades físicas de la red se pueden simular ajuste local, áreas específicas, tales como fronteras pueden ser un proceso independiente.
Además del valor analógico de los datos variables, cada célula en el tipo de bloque célula también tiene un puntero que apunta a un objeto Dinámica.
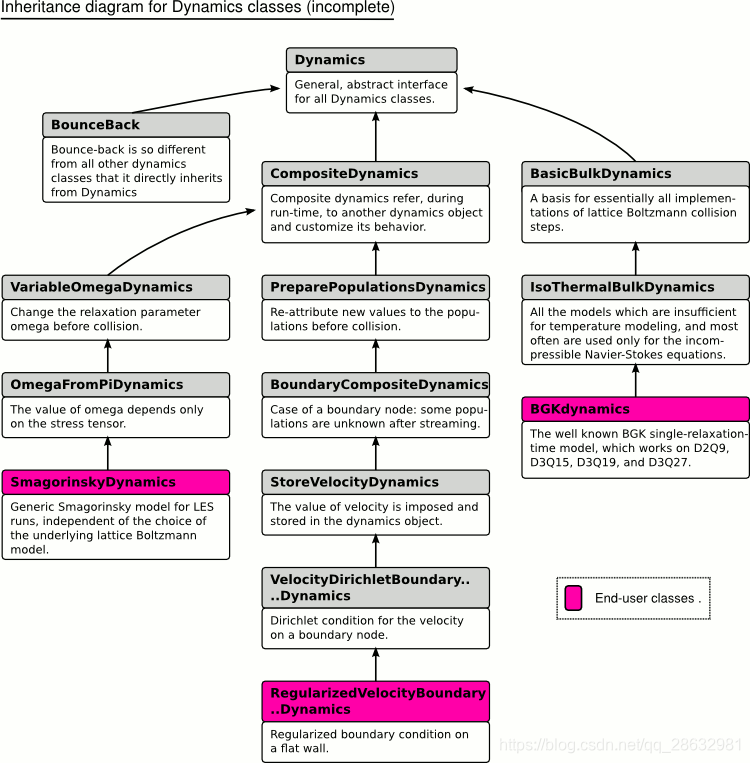
Para aprender cómo definir una nueva clase dinámica, la forma más fácil es para ver Palabos una clase definida. Por ejemplo, BGK dinámicamente define en src basicDynamics archivo / / isoThermalDynamics.hh. Un ejemplo bueno (modificado comportamiento cinético de otra clase clase existente) complejo es cinéticamente dinámica Smagorinsky, que se define en src / complexDynamics / smagorinskyDynamics.hh en.
Para la consecución de una colisión, una referencia a un único medio de adquisición de objeto Dynamics; por lo tanto, la etapa de conflicto debe ser localizada. componentes analógicos no locales se logra mediante un procesador de datos, como se muestra en la siguiente sección.
Y el bloque-celosía como plantilla objeto dinámico depende de dos parámetros, uno para la representación de coma flotante, una para descriptores de celosía. Mediante el uso de un identificador de rejilla proporcionada en la información de descripción, la colisión debería ser un paso común, la preparación de la forma de celosía independiente. Obviamente, de forma genérica para escribir algoritmo eficiente que es una solución de compromiso, ya que puede ser optimizado para un compilador rejilla particular no se puede encontrar. Este problema puede ser resuelto mediante el uso de una plantilla dada celosía de especialización. A fin de lograr clase BGKdynamics como un ejemplo. Paso-conflicto se refiere a un genéricos dynamicsTemplates objeto, que se definen en el archivo src / latticeBoltzmann / dynamicsTemplates.h en. versión efectiva del grupo de clase se puede encontrar una variedad de rejilla 2D y 3D en el archivo dynamicsTemplates2D.h y dynamicsTemplates3D.h.
explicación
Esta clase dinámica se aplica a la colisión entre el paso de migración, chocan con el proceso de migración para la especificación punto de la red, todos asociados con la migración dinámica de clases colisión, rebote colisión o similar en el nodo límite de parcela aplica, se derivan de esta clase generalmente calculado en la estructura de dominios de fase de inicialización se introduce en forma de una rejilla de bloques puntero (descrito en la sección anterior se ha explicado), el conjunto se puede repetir, después de un tiempo establecido es conjunto borrará el primer conjunto, siempre y cuando el cálculo final, puede determinar todos los puntos de la rejilla tiene una clase dinámica correspondiente, el cálculo de esta parte no hay ningún problema.
Clase dinámica se aplica sólo a la operación local, es decir, operan en un puntos locales de red, y no puede hacer referencia distinto del valor actual del punto de la cuadrícula a punto de la cuadrícula como el actual valor de referencia de cálculo de la migración de la colisión, si quieres rejilla extrapolar o similar la operación debe ser escrito en la parte de datos de la parte posterior del procesador. (Esta duda, recuerde que debe ser así, entonces I podrá ser revisada)
Del mismo modo, la única clase hereda el final de la clase, es la clase de usuario, el otro padre, son de tipo abstracto de datos o una clase de semi-abstracta no puede ser instanciada .
(四) Procesadores de datos
El documento original
procesadores de datos definen una operación a realizar sobre todo el dominio, o en partes de un bloque. En un bloque de celosía, que se utilizan para implementar toda la operación que no puede ser formulado en términos de objetos de dinámica. Estos consisten sobre todo de las operaciones no locales, tales como la evaluación de las plantillas de diferencias finitas para la aplicación de condiciones de contorno. En escalares-campos y tensor-campos, procesadores de datos proporcionan la manera solamente (suficientemente eficiente y paralelizable) para realizar una operación en un dominio espacialmente extendida.
Además, los procesadores de datos tienen la capacidad de intercambio de información entre varios bloques, ya sea del mismo tipo o de tipo diferente (ejemplo: el acoplamiento entre un bloque de celosía y escalar-campo). Este es por ejemplo utilizado para la aplicación de los acoplamientos físicos (fluidos de componentes múltiples, fluidos térmicos con Boussinesq aproximación), para la configuración de las condiciones iniciales (inicialización de la velocidad de los valores en un campo de vector), o la ejecución de clásica operaciones basadas en matrices (suma elemento racional de dos escalares-campos).
Finalmente, los procesadores de datos se utilizan para realizar operaciones de reducción, en todo el bloque o en sub-dominios. Los ejemplos van desde el cálculo de la energía cinética media en una simulación para el cálculo de la fuerza de arrastre que actúa sobre un obstáculo.
Dos puntos de vista diferentes se adoptó para la definición y la aplicación de un procesador de datos. En el nivel de aplicación, el usuario especifica un área (que puede ser rectangular o irregular) de un bloque dado, en el que para ejecutar el procesador de datos. Si el bloque tiene internamente una estructura multi-bloque, el procesador de datos está subdividido en varios procesadores de datos más específicos, uno para cada atómica de bloque dentro de la multi-bloque que se cruza con el área especificada. En el nivel de ejecución, un procesador de datos por lo tanto siempre actúa sobre un atómica-bloque, en un área que se determinó previamente por la intersección de la superficie original con el dominio de la atómico-bloque.
Cabe mencionar que, si bien los procesadores de datos en bruto son un tanto incómodo de usar, es probable que nunca se pondrá en contacto con ellos. En su lugar, Palabos ofrece una interfaz simplificada a través de los llamados funcionales procesamiento de datos, que ocultan los detalles técnicos para que pueda concentrarse en las partes esenciales. El resto de los concentrados guías de usuario exclusivamente en estos funcionales, los cuales serán llamados procesadores de datos, para abreviar.
Al final, es bastante fácil de definir nuevos procesadores de datos. Todo lo que necesita hacer es escribir una función que recibe una atómico-bloque y las coordenadas de un subdominio como parámetros, y ejecuta un algoritmo de este subdominio. Todas las operaciones complejas, como el sub-división de las operaciones en presencia de una multi-bloque, o la paralelización del código, son automáticos.
Un ejemplo educativa de un procesador de datos se encuentra en los ejemplos ejemplo archivo / codeByTopics / acoplamientos. Se muestra cómo inicializar un bloque de celosía con una velocidad de un campo vectorial escribiendo un procesador de datos para el bloque de celosía vs. 2D acoplamiento tensor de campo.
Más definiciones de los datos-procesadores que actúan sobre bloques-celosías pueden encontrarse en los archivos de src / simulationSetup / latticeInitializerXD.h y .hh, y de datos-procesadores que actúan sobre scalar- o tensor-campos se definen en los archivos de src / simulationSetup / dataFieldInitializerXD .hy .hh. Ejemplos para la evaluación de las operaciones de reducción se proporcionan en los archivos src / core / dataAnalysisXD.h y .hh.
Todos estos datos procesadores están envueltos en funciones de confort, que se resumen en el Apéndice: referencia parcial función / clase.
Traducción de documentos
operación El procesador de datos se define a cabo en una porción o de todo el bloque de dominio. En el bloque-red, no pueden ser utilizados para la realización de la operación de toda la dinámica objetos representados. Estos incluyen las operaciones no locales más importantes, tales como diferencias finitas Evaluación condición de contorno de la plantilla. En el dominio de campos escalares y tensoriales, el procesador de datos proporciona el único método factible (suficientemente eficaces y paralelización) para realizar operaciones en el campo de extensión espacial.
Además, el procesador de datos puede intercambiar información entre varios bloques, que bloquea puede ser del mismo tipo o pueden ser de diferentes tipos (por ejemplo: el acoplamiento entre la rejilla y los bloques campo escalar). Este es, por ejemplo implementar un acoplamiento físico (con el fluido de Boussinesq multicomponente, líquido caliente), las condiciones iniciales (valor de campo de vector de inicialización velocidad), o la operación clásica se realiza basándose en la matriz (Añadir los dos elementos campo escalar).
Por último, el procesador de datos opera en todo el bloque o subdominios en reducción. Los ejemplos van cubiertas cinéticos de energía calculado a partir de la simulación para calcular la resistencia media que actúa sobre el obstáculo.
Definición y aplicación del procesador de datos utilizando dos puntos de vista diferentes. En el nivel de aplicación, un usuario designa una región de un bloque dado (puede ser rectangular o irregular), las preformas procesador de datos en el área. Si el bloque de datos interna múltiple tiene una estructura de bloque, entonces el procesador de datos puede subdividirse en más procesador de datos específico, el procesador de datos correspondiente a cada uno de una pluralidad de bloques atómica dentro de un área designada de intersección. Así, en el nivel de aplicación, un procesador de datos siempre actúa en el bloque atómico, es decir, el área de intersección determina previamente por el dominio de la región original del bloque atómica.
Cabe mencionar que, si bien el procesador de datos en bruto incómodo de usar, pero no se puede entrar en contacto con ellos. En su lugar, Palabos proporcionada por las denominadas funciones de procesamiento de datos con una interfaz simplificada que oculta los detalles técnicos de estas funciones, para que pueda concentrarse en una parte clave. El resto de la guía del usuario centrarse exclusivamente en estas funciones, se hace referencia como un procesador de datos.
Por último, definir un nuevo procesador de datos es muy fácil. Que tiene que hacer es escribir una función que recibe un bloque y las coordenadas atómicas de un subdominio como un parámetro y ejecutar un algoritmo en este subdominio. Todas las operaciones complejas, tales como la existencia de una pluralidad de segmentos operativos, código o en paralelo, son automáticos.
Un procesador de datos se puede encontrar en los ejemplos de archivos de muestra / codeByTopics / acoplamientos pueden ser ejemplos instructivos. Se prepara por el procesador de dos dimensiones bloque de celosía de acoplamiento tensor de datos de campo, el bloque de muestra de inicialización cómo el campo vector de la velocidad de un cedazo con.
Más se pueden encontrar en el papel de src / simulationSetup / latticeInitializerXD.h y el archivo .hh define el procesador de datos de bloque de rejilla, el procesador de datos para definir el papel de un escalar o tensor de campo en src / simulationSetup / dataFieldInitializerXD.h y .hh archivo. src / core / dataAnalysisx.h y documento .hh proporciona un ejemplo de evaluación de la operación de restauración.
Todos estos procesadores de datos se empaquetan en un funciones convenientes, estas funciones en el manual de documentos Apéndice: un resumen de la sección de referencia de función / clase parcial.
explicación
Aquí es un procesador de datos que actúa sobre cada sección de estadísticas macro después de la colisión con la migración, con los datos más entrante de datos de cuadrícula en bloques, cada punto de datos, por una envoltura de papel de, sobres que quieren operar en y alrededor del punto de datos correspondiente al tamaño del sobre del paquete, no se me ha reescrito por completo procesador de datos, pero más o menos visto la necesidad de reescribir el procesador de datos es heredado por el padre llegue a ejecutar una función, para lograr sus propios bloque de datos celular se vuelve a escribir, y las operaciones estadísticas relacionadas necesario.
(E) Resumen
El por encima de cuatro, como Palabos los datos más básicos Tipo de ella, lo que reescribir descriptor, Dinámicas de clase, de los responsables de gama alta, reescribiendo los tres, se puede hacer un modelo y condiciones de contorno Palabos no existe, no se recomienda para reescritura novato o en la comprensión de la situación, llamando a la clase original tanto como sea posible para lograr los efectos del cálculo de su simulación.
