Autor original: SessionBest
Dirección original: principio de implementación subyacente de Lucene, su estructura de índice
1. Introducción a Lucene y los principios de indexación
Esta parte se expande desde tres aspectos: Introducción a Lucene, Principios del índice, Implementación del índice Lucene.
1.1 Introducción a Lucene
Lucene fue desarrollado originalmente por el famoso Doug Cutting, de código abierto en 2000, y ahora es la mejor opción para soluciones de recuperación de texto completo de código abierto. Sus características se resumen a continuación: implementación completa de Java, código abierto, alto rendimiento, funciones completas, La expansión fácil y las funciones completas se reflejan en Soporte para segmentación de palabras, varios métodos de consulta (prefijo, difuso, regular, etc.), resaltado de puntuación, almacenamiento en columnas (DocValues), etc.
Además, aunque Lucene ha estado en desarrollo durante más de 10 años, todavía mantiene un desarrollo activo para satisfacer las crecientes necesidades de análisis de datos. La última versión 6.0 introduce árboles de bloques kd, que mejoran de manera integral el rendimiento de recuperación de información de tipo digital y ubicación geográfica. Además, los sistemas de análisis y recuperación distribuidos Solr y ElasticSearch basados en Lucene también se están desarrollando en pleno desarrollo, y ElasticSearch también se utiliza en nuestros proyectos.
El uso general de Lucene se muestra en la figura:
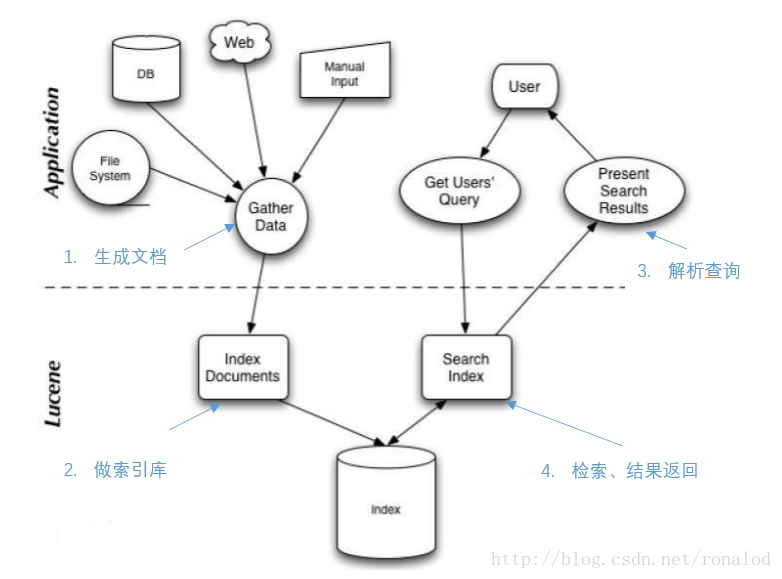
Combine el código para explicar los cuatro pasos:
IndexWriter iw=new IndexWriter();//创建IndexWriter
Document doc=new Document( new StringField("name", "Donald Trump", Field.Store.YES)); //构建索引文档
iw.addDocument(doc); //做索引库
IndexReader reader = DirectoryReader.open(FSDirectory.open(new File(index)));
IndexSearcher searcher = new IndexSearcher(reader); //打开索引
Query query = parser.parse("name:trump");//解析查询
TopDocs results =searcher.search(query, 100);//检索并取回前100个文档号
for(ScoreDoc hit:results.hits)
{
Document doc=searcher .doc(hit.doc)//真正取文档
}Es muy simple de usar, pero solo conociendo los principios detrás de esto podemos hacer un buen uso de Lucene.Los principios generales de recuperación y los detalles de implementación de Lucene se presentarán más adelante.
1.2 Principio del índice
La tecnología de recuperación de texto completo tiene una larga historia, y la mayoría de ellas se basan en índices invertidos . Ha habido algunas otras soluciones, como la toma de huellas digitales de archivos. El índice invertido, como su nombre indica, es contrario a las palabras que contiene un artículo. Comienza con la palabra y registra en qué documentos ha aparecido la palabra. Consta de dos partes: un diccionario y una tabla invertida .
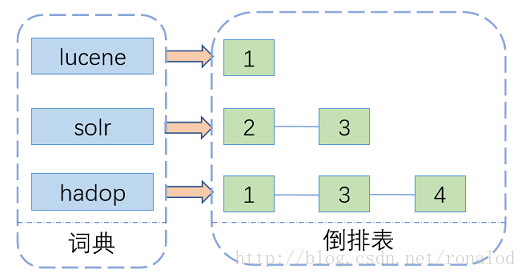
Entre ellas, la estructura del diccionario es particularmente importante. Hay muchos tipos de estructuras de diccionario, cada una con sus propias ventajas y desventajas. La más simple es ordenar una matriz y recuperar datos mediante una búsqueda binaria. La más rápida tiene una tabla hash. La búsqueda de disco tiene árbol B y árbol B + , pero una estructura de índice invertida que pueda soportar terabytes de datos debe equilibrarse en tiempo y espacio. La siguiente figura enumera las ventajas y desventajas de algunos diccionarios comunes:
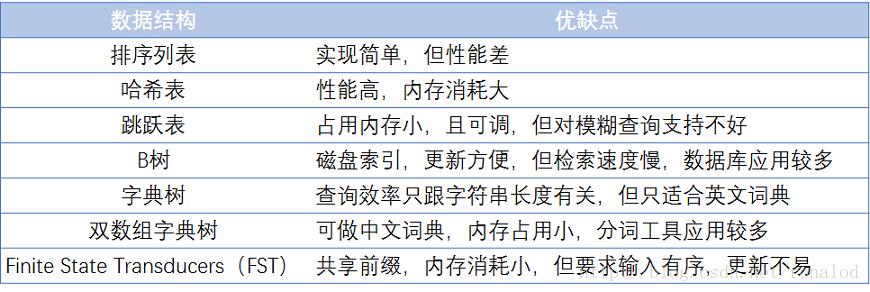
Los disponibles son: árbol B +, tabla de salto, árbol FST
B +:
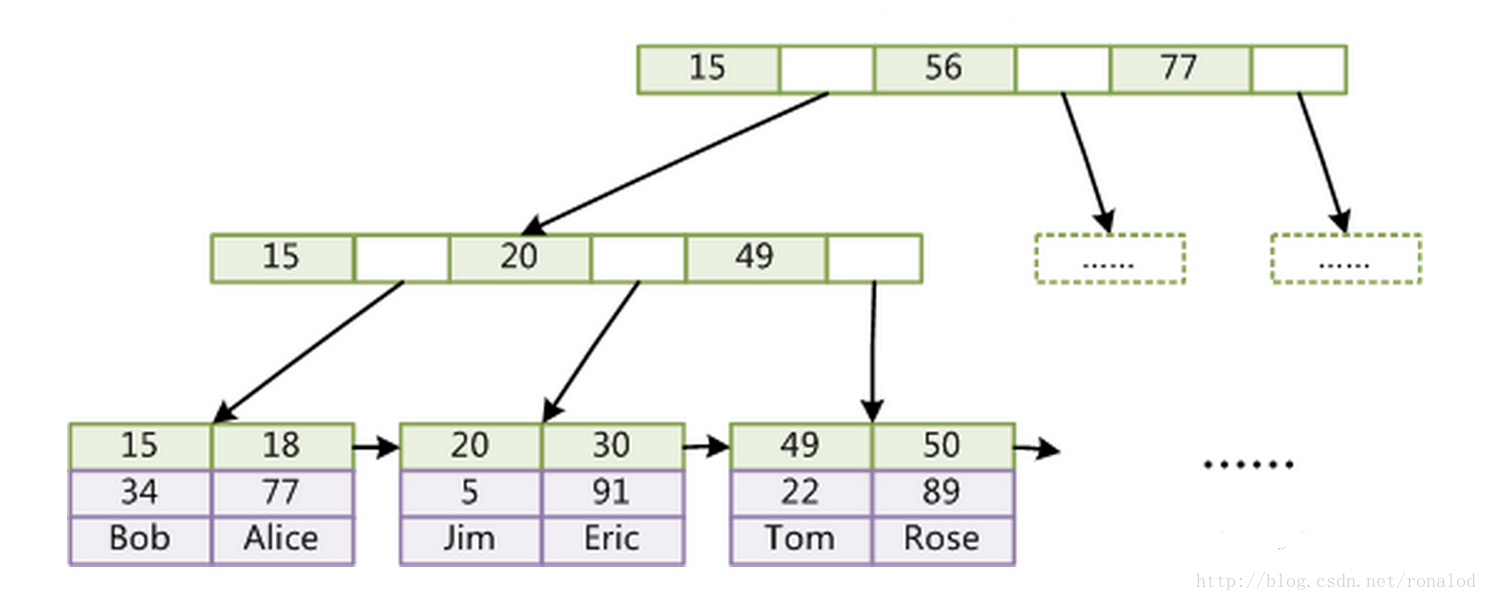
- Base teórica: árbol de búsqueda equilibrado multidireccional
- Ventajas: índice de almacenamiento externo, actualizable
- Desventajas: gran espacio, no lo suficientemente rápido
Mesa de salto:
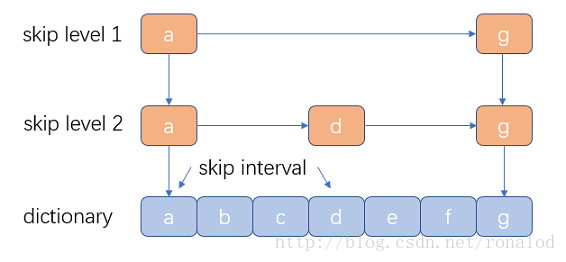
- Ventajas: estructura simple, intervalo de omisión controlable y niveles controlables. Antes de Lucene3.0, también se usaba la estructura de tabla de omisión, que luego fue reemplazada por FST. Sin embargo, las tablas de omisión tienen otras aplicaciones en Lucene, como la combinación de tablas invertidas y el documento indexación de números .
- Desventajas: soporte de consultas difusas deficiente
FST:
La estructura de índice utilizada actualmente por Lucene
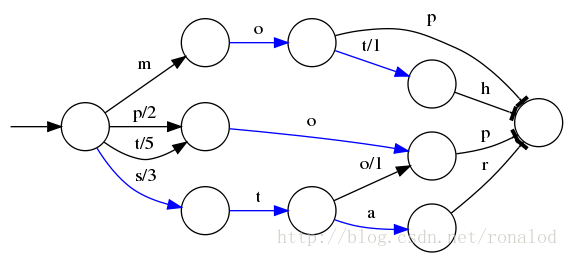
Base teórica: "Construcción directa de transductores subsecuentes acíclicos mínimos", que construye gráficos acíclicos dirigidos mínimos ingresando cadenas ordenadas .
Ventajas: bajo uso de memoria, tasa de compresión generalmente entre 3 y 20 veces, buen soporte de consulta difusa, consulta rápida
Desventajas: estructura compleja, requisitos de entrada ordenados, no es fácil de actualizar Lucene tiene una implementación FST. Desde la interfaz externa, es muy similar a la estructura del Mapa, con búsqueda e iteración:
String inputs={"abc","abd","acf","acg"}; //keys
long outputs={1,3,5,7}; //values
FST<Long> fst=new FST<>();
for(int i=0;i<inputs.length;i++)
{
fst.add(inputs[i],outputs[i])
}
//get
Long value=fst.get("abd"); //得到3
//迭代
BytesRefFSTEnum<Long> iterator=new BytesRefFSTEnum<>(fst);
while(iterator.next!=null){...}Prueba de rendimiento de 1 millón de datos:
| estructura de datos | HashMap | TreeMap | FST |
|---|---|---|---|
| Tiempo de construcción (ms) | 185 | 500 | 1512 |
| Consultar todas las claves (ms) | 106 | 218 | 890 |
Se puede ver que el rendimiento de FST es básicamente el mismo que el de HaspMap, pero FST tiene la ventaja incomparable de que ocupa una pequeña cantidad de memoria, solo alrededor de una décima parte de HashMap. Esto es esencial para la recuperación a gran escala de datos grandes. Después de todo, la velocidad es más rápida. Es inútil no entrar en la memoria. Por lo tanto, una estructura de diccionario calificada requiere:
- Velocidad de consulta.
- Uso de memoria.
- Combinación de memoria + disco.
Más adelante analizaremos la estructura del índice de Lucene, centrándonos en estos tres puntos de las características de la implementación de FST de Lucene.
1.3 Implementación del índice Lucene
Después de años de evolución y optimización, Lucene tiene una estructura de archivo de índice como se muestra en la figura. Básicamente se puede dividir en tres partes: diccionario, tabla invertida, archivo directo y DocValues de almacenamiento en columnas .
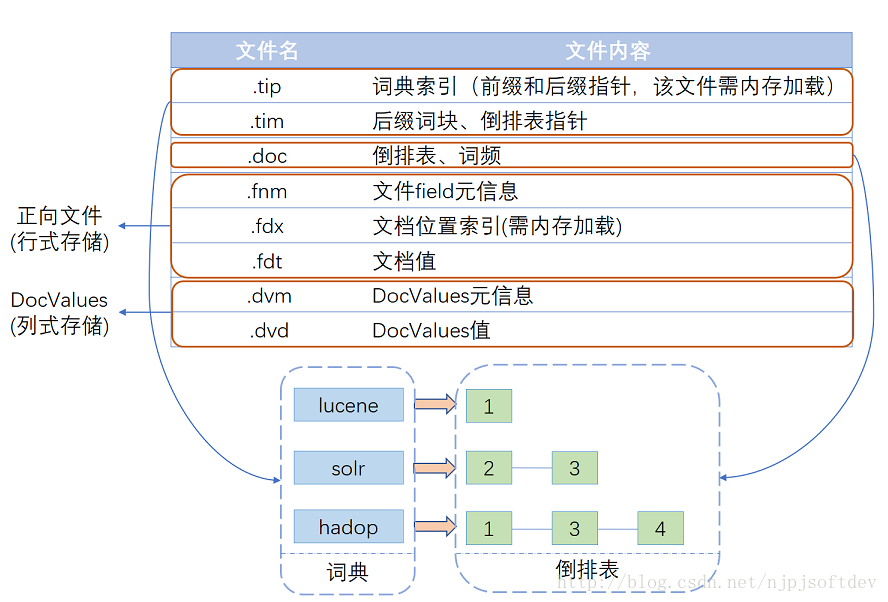
A continuación se detalla la estructura de cada parte:
1. Estructura del índice
La estructura de datos utilizada actualmente por Lucene es FST, y sus características son:
- La complejidad de la búsqueda de palabras es O (len (str))
- Prefijo compartido, ahorra espacio
- La memoria almacena el índice de prefijo, el disco almacena el bloque de palabras de sufijo
Esto es consistente con los tres elementos de la estructura del diccionario que mencionamos anteriormente: 1. Velocidad de consulta. 2. Uso de memoria. 3. Combinación de memoria + disco. Insertamos cuatro palabras abd, abe, acf, acg en la biblioteca de índices y miramos el contenido del archivo de índice.
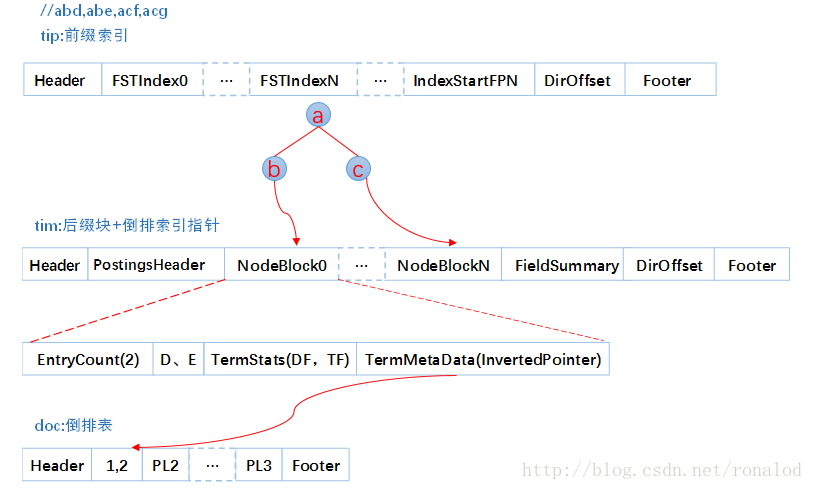
En la parte de la sugerencia, cada columna tiene un índice FST, por lo que habrá múltiples FST, y cada FST almacena los punteros de bloque de prefijo y sufijo, donde los prefijos son a, ab y ac. Otra información de bloques de sufijos y palabras, como el puntero de tabla invertida, TFDF, etc., se almacena en tiempo El archivo doc contiene una tabla invertida de cada palabra. Entonces, su proceso de recuperación se divide en tres pasos:
- Cargue el archivo tip en la memoria y busque la posición del bloque de palabras de sufijo a través del prefijo coincidente FST.
- De acuerdo con la posición del bloque de palabras, lea el bloque de sufijo en el archivo de tiempo del disco y busque el sufijo y la información de posición de la tabla invertida correspondiente.
- Cargue la tabla invertida en el archivo doc de acuerdo con la posición de la tabla invertida.
Habrá dos problemas aquí. El primero es cómo calcular el prefijo y el segundo es cómo escribir el sufijo en el disco y ubicarlo a través de FST. A continuación, se describe el proceso de construcción de FST por Lucene: Se sabe que FST requiere entrada en orden, por lo que Lucene lo analizará Las palabras del documento se ordenan por adelantado y luego se construye el FST. Suponemos que la entrada es abd, abd, acf, acg, luego todo el proceso de construcción es el siguiente:
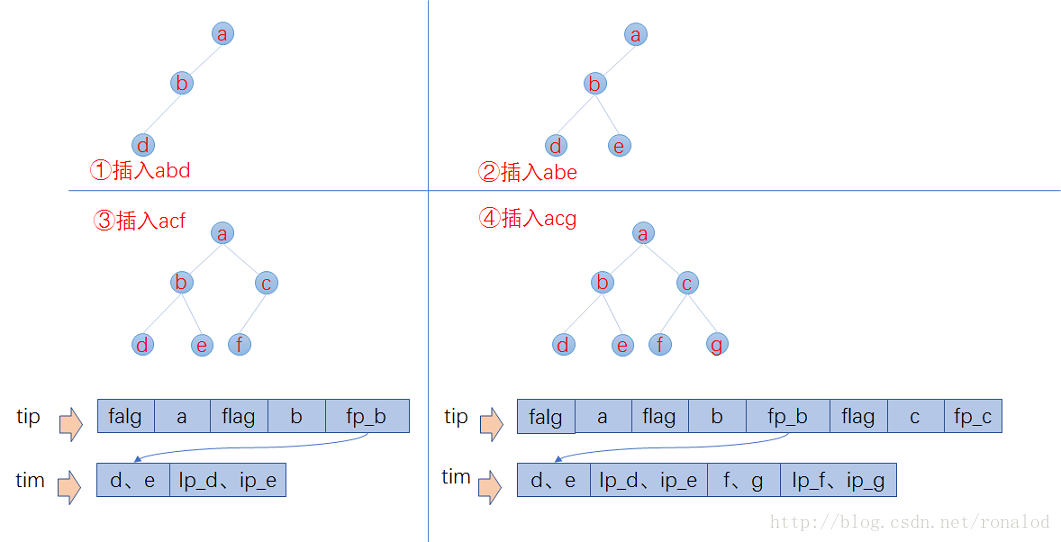
- Al insertar abd, no hay salida.
- Al insertar abe, se calcula el prefijo ab, pero en este momento, no sé si no habrá otras palabras con el prefijo ab, por lo que no hay salida en este momento.
- Al insertar acf, porque está en orden, sabiendo que no habrá más palabras con el prefijo ab, entonces puede escribir tip y tim. En tim, escriba el bloque de sufijo d, e y su posición de tabla invertida ip_d, escriba a, b y la posición del bloque de palabras de sufijo con el prefijo ab en ip_e, tip (en situaciones reales, se escribirá más información, como la frecuencia de palabras).
- Cuando se inserta acg, se calcula que el prefijo ac se comparte con acf En este momento, la entrada ha finalizado y todos los datos se escriben en el disco. Los bloques de sufijo f, gy las correspondientes posiciones de la tabla invertida se escriben en tim, yc y las posiciones de los bloques de sufijo con el prefijo ac se escriben en tip.
Lo anterior es un proceso simplificado.Las principales estrategias de optimización implementadas por el FST de Lucene son:
- El número mínimo de sufijos. Lucene tiene un número mínimo de sufijos para el prefijo escrito en la sugerencia, el valor predeterminado es 25, para reducir aún más el uso de memoria. Si el número de sufijo es 25, entonces no habrá prefijos ab y ac, y solo habrá un nodo seguidor, y abd, abe, acf y acg se almacenarán como sufijos en el archivo tim. Una biblioteca de índice de nuestro 10g, el consumo de memoria de índice solo representa alrededor de 20M.
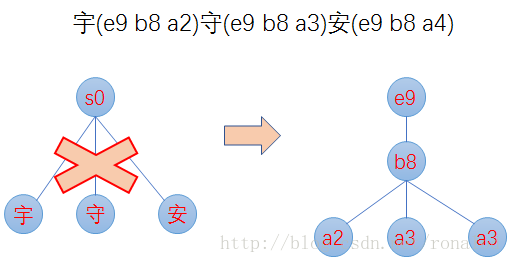
- El cálculo del prefijo se basa en bytes en lugar de char, lo que puede reducir el número de sufijos y evitar que demasiados sufijos afecten el rendimiento. Por ejemplo, los tres caracteres chinos de Yu (e9 b8 a2), Shou (e9 b8 a3) y An (e9 b8 a4) son construidos por FST. No solo hay un nodo raíz y tres caracteres chinos como sufijos, sino que comienzan del código Unicode. e9 y b8 son prefijos, a2, a3 y a4 son sufijos, como se muestra en la siguiente figura:
2. Estructura de mesa invertida
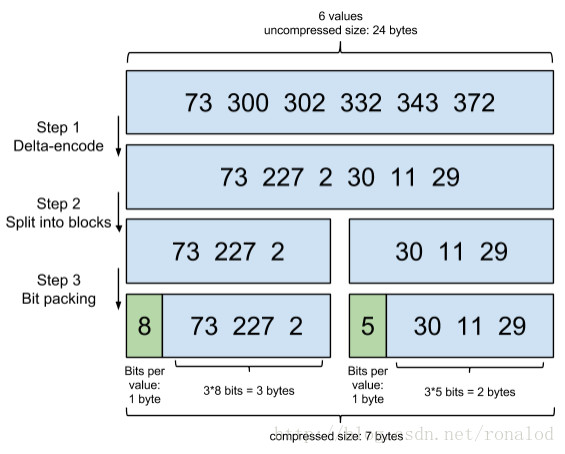
La tabla invertida es una colección de números de documentos, pero hay muchos detalles sobre cómo almacenarla y recuperarla. La estructura de tabla invertida que utiliza Lucene actualmente se llama Marco de referencia, que tiene dos características principales:
1) Compresión de datos: Puede ver cómo convertir 6 El número se comprime de los 24bytes originales a 7bytes.
2) La tabla de salto acelera la combinación, porque en la consulta booleana, y las operaciones yo deben combinar la tabla invertida, entonces el mismo número de documento debe ubicarse rápidamente, por lo que la tabla de salto se usa para buscar el mismo Número del Documento.
Esta parte puede hacer referencia a un blog de ElasticSearch, que contiene algunas pruebas de rendimiento:
Tabla invertida de ElasticSearch
3. Reenviar documentos
El archivo de reenvío se refiere al documento original. Lucene también proporciona la función de almacenamiento para el documento original. Su función de almacenamiento es bloque + compresión. El archivo fdt es el archivo que almacena el documento original. Ocupa el 90% del espacio en disco del biblioteca de índices. El archivo fdx Para indexar archivos, obtenga rápidamente la ubicación del documento a través del número de documento (número
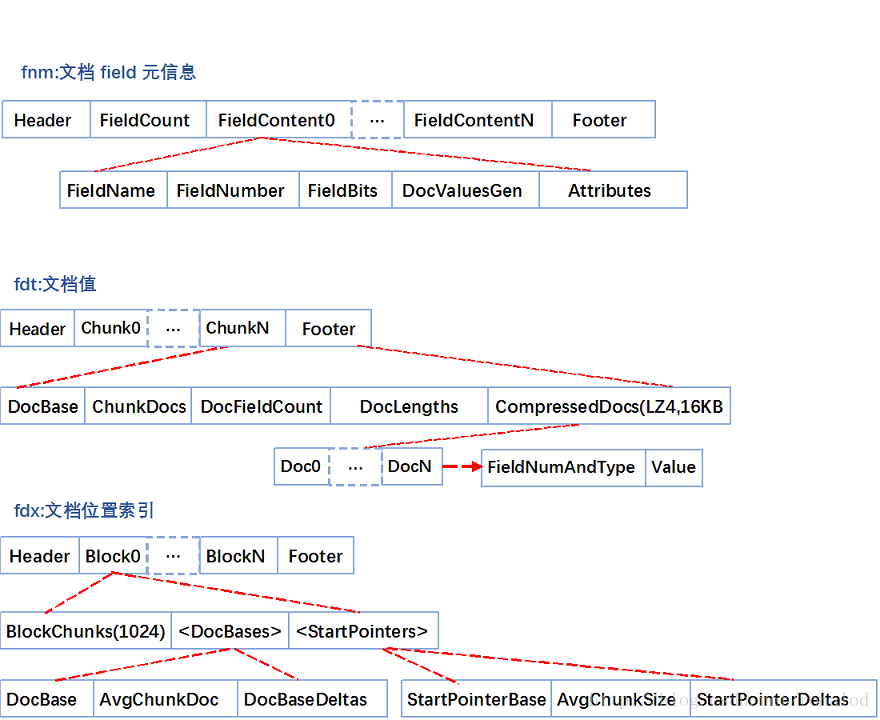
autoincrementado ), y su estructura de archivo es la siguiente: fnm almacena varios tipos de columnas, nombres de columnas, métodos de almacenamiento y otra información para meta información.
fdt es el valor del documento. Una parte es un bloque. Cuando Lucene indexa un documento, el documento se almacena en caché primero. Cuando la caché es mayor de 16 KB, el documento se comprimirá y almacenará. Un fragmento contiene el documento inicial del fragmento, cuántos documentos y el contenido del documento comprimido.
fdx es el índice del número de documento. Cuando se almacena la tabla invertida, el número de documento se puede ubicar rápidamente a través de fdx para ubicar la posición del documento, es decir, la posición del fragmento. Su estructura de índice es relativamente simple, que es la estructura de la tabla de omisión. Primero, agrupará 1024 fragmentos en un bloque. Cada bloque registra el valor del documento inicial y el bloque es equivalente a una tabla de salto de nivel.
Entonces, para encontrar un documento, hay tres pasos: el
primer paso es encontrar el bloque de dos maneras y ubicar a qué bloque pertenece.
El segundo paso es encontrar el fragmento y la posición del fragmento al que pertenece de acuerdo con el número de documento inicial de cada fragmento del bloque.
El tercer paso es cargar el fragmento de fdt y encontrar el documento. Un detalle más aquí es que almacenar el valor del documento inicial y la ubicación del fragmento del fragmento no es una matriz simple, sino un método de compresión promedio. Por tanto, el valor del documento inicial del Nth fragmento se restaura desde DocBase + AvgChunkDocs * n + DocBaseDeltas [n], y la posición del Nth fragmento en fdt se restaura desde StartPointerBase + AvgChunkSize * n + StartPointerDeltas [n].
A partir del análisis anterior, se puede ver que Lucene almacena los archivos originales como almacenamiento y, para mejorar la utilización del espacio, varios documentos se comprimen juntos, por lo que los documentos adicionales deben leerse y descomprimirse al buscar documentos, por lo que el proceso de La obtención de documentos es muy aleatoria, aunque IO y Lucene proporcionan columnas específicas para la obtención, se puede ver en la estructura de almacenamiento que no reducirá el tiempo de obtención de documentos.
4. DocValues de almacenamiento en columnas
Sabemos que el índice invertido puede resolver el mapeo rápido de palabras a documentos, pero cuando necesitamos realizar operaciones de agregación como clasificación, ordenamiento y cálculos matemáticos en los resultados de la recuperación, necesitamos un mapeo rápido de números de documentos a valores y si es un índice invertido o los documentos almacenados en filas no pueden cumplir con los requisitos.
Antes de la versión original 4.0, Lucene se dio cuenta de este requisito a través de FieldCache. Su principio es cambiar la asignación (valor de campo -> doc) a la asignación (doc -> valor de campo) invirtiendo la tabla invertida por columna, pero este método de implementación Hay dos problemas importantes:
1. Largo tiempo de construcción.
2. Gran huella de memoria, fácil de eliminar la memoria y afectar la recolección de basura.
Por lo tanto, después de la versión 4.0, Lucene introdujo DocValues para resolver este problema, es un almacenamiento en columnas como FieldCache, pero tiene las siguientes ventajas:
1. Pre-compila y escribe archivos.
2. Basado en el archivo de correlación, sin memoria de almacenamiento dinámico de JVM, error de página de programación del sistema.
El método de implementación de DocValues es solo entre un 10 y un 25% más lento que la memoria FieldCache, pero la estabilidad ha mejorado mucho.
Actualmente, Lucene tiene cinco tipos de DocValues: NUMERIC, BINARY, SORTED, SORTED_SET, SORTED_NUMERIC, y existen métodos de compresión específicos para cada tipo de Lucene.
Por ejemplo, para el tipo NUMÉRICO, es decir, el tipo de número, existen muchos métodos de compresión para el tipo de número, como: incremento, compresión de tabla y máximo divisor común. Se seleccionan diferentes métodos de compresión de acuerdo con las características de los datos. .
El tipo CLASIFICADO es el tipo de cadena y el método de compresión es la compresión de tabla: el diccionario de cadenas se ordena y se le asigna una ID digital por adelantado, y solo la tabla de asignación de cadenas y la matriz numérica se almacenan cuando se almacena, y la matriz numérica se puede almacenar comprimido por NUMERIC de nuevo. Compresión, como se muestra a continuación:
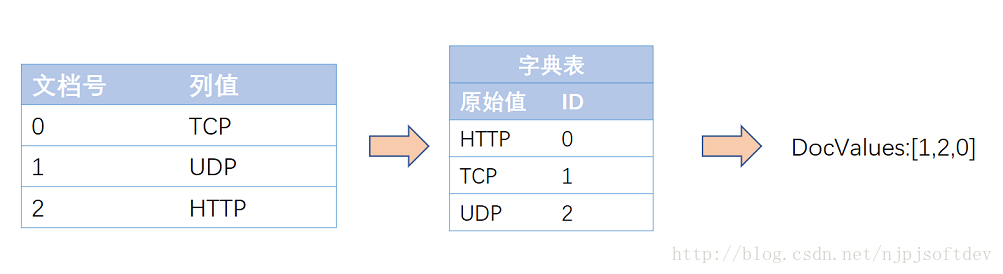
De esta manera, la matriz de cadenas original se convierte en una matriz numérica. Primero, se reduce el espacio y la asignación de archivos es más eficiente. En segundo lugar, el método de acceso original se convierte en un acceso de longitud fija.
Para la aplicación de DocValues se implementa de manera más sistemática y completa la función ElasticSearch, es decir, la función Aggregation-aggregation de ElasticSearch. Sus funciones de agregación se dividen en tres categorías:
1. Métrica ->
Funciones estadísticas típicas: suma, min, max, avg , cardinalidad, porcentaje, etc.
2. Bucket ->
funciones típicas de agrupación : histograma de fecha, agrupación, partición de ubicación geográfica
3. Pipline ->
funciones típicas basadas en agregación y reagregación : encontrar el valor máximo basado en el promedio de cada grupo .
Según estas funciones de agregación, ElasticSearch ya no se limita a la búsqueda y puede responder las siguientes preguntas de SQL
select gender,count(*),avg(age) from employee where dept='sales' group by gender
销售部门男女人数、平均年龄是多少 Veamos cómo ElasticSearch implementa el SQL anterior basado en índice invertido y DocValues.
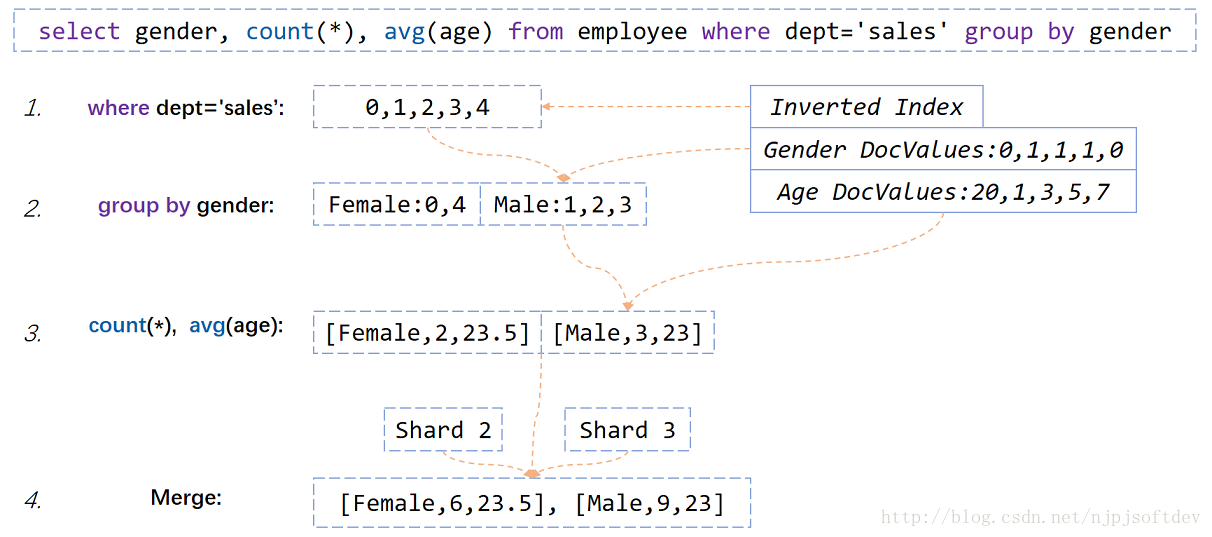
1. Busque la tabla invertida del departamento de ventas del índice invertido.
2. Saque el género correspondiente de cada persona de los DocValues del género según la tabla invertida y agrúpelos en Femenino y Masculino.
3. Calcule el número de personas en cada grupo y la edad promedio de acuerdo con la situación de agrupación y la edad DocValues
4. Debido a que ElasticSearch está particionado, la combinación de los resultados devueltos de cada partición es el resultado final.
Lo anterior es el proceso general de agregación de ElasticSearch. También se puede ver que un cuello de botella de la agregación de ElasticSearch es que el último paso de agregación solo se puede agregar en una sola máquina, por lo que algunas estadísticas tendrán errores, como el recuento (*) grupo por límite de producción 5, el total final No es preciso. Debido a la agregación de memoria de un solo punto, es imposible que cada partición devuelva todas las estadísticas de agrupación, solo una parte, y el resultado final será incorrecto al resumir, de la siguiente manera:
Datos originales:
| Fragmento 1 | Fragmento 2 | Fragmento 3 |
|---|---|---|
| Producto A (25) | Producto A (30) | Producto A (45) |
| Producto B (18) | Producto B (25) | Producto C (44) |
| Producto C (6) | Producto F (17) | Producto Z (36) |
| Producto D (3) | Producto Z (16) | Producto G (30) |
| Producto E (2) | Producto G (15) | Producto E (29) |
| Producto F (2) | Producto H (14) | Producto H (28) |
| Producto G (2) | Producto I (10) | Producto Q (2) |
| Producto H (2) | Producto Q (6) | Producto D (1) |
| Producto I (1) | Producto J (8) | |
| Producto J (1) | Producto C (4) |
count (*) grupo por límite de producción 5. Los datos devueltos por cada nodo son los siguientes:
| Fragmento 1 | Fragmento 2 | Fragmento 3 |
|---|---|---|
| Producto A (25) | Producto A (30) | Producto A (45) |
| Producto B (18) | Producto B (25) | Producto C (44) |
| Producto C (6) | Producto F (17) | Producto Z (36) |
| Producto D (3) | Producto Z (16) | Producto G (30) |
| Producto E (2) | Producto G (15) | Producto E (29) |
Después de la fusión:
| Fusionados |
|---|
| Producto A (100) |
| Producto Z (52) |
| Producto C (50) |
| Producto G (45) |
| Producto B (43) |
El número total del producto A es correcto porque todos los nodos han regresado, pero el producto C no se devuelve en el nodo 2 porque no está entre los 5 primeros, por lo que el número total es incorrecto.
para resumir
Lo anterior es la introducción de Lucene y el análisis de los principios subyacentes, centrándose en las estrategias de implementación y las características de Lucene. El siguiente artículo presentará cómo podemos optimizar nuestro sistema de recuperación de texto completo a partir de estos principios subyacentes.
Declaración de derechos de autor: este artículo es el artículo original del blogger y no puede reproducirse sin el permiso del blogger. https://blog.csdn.net/njpjsoftdev/article/details/54015485