la web oficial del proyecto de NVIDIA
capa de Convolución parcial Implementar código fuente
resumen
El método de reparación de una red basada en estudio profundidad de imagen convencional utilizando convolución estándar en la imagen dañado, utilizado para el volumen de píxeles efectivos (píxeles de la parte no falta) lleno de valores y deleciones (típicamente de promedio) apropiados como parte de las condiciones la operación de producto. Esto a menudo conduce a artefactos tales como las diferencias de color y borrosa. Después del tratamiento se utiliza normalmente para reducir estos artefactos, pero costoso, puede fallar. Los autores sugieren el uso de parte de la convolución Partial Convolutions, the convolution is masked and renormalized to be conditioned on only valid pixels. Que comprende además un mecanismo para la siguiente capa puede ser generado máscara actualizado automáticamente . Nuestro modelo es mejor que otros irregular masksmétodos. Se demuestra la comparación cualitativa y cuantitativa con otros métodos para validar nuestro enfoque
Introducción
- aprendizaje previo Profundidad región principalmente rectangular situado cerca del centro de la imagen, y normalmente se basan en cara de post-procesamiento. ausencia irregular puede ser una buena reparación en el presente documento. No se requiere post-procesamiento de
post-processingimagen de Poisson y la operación de mezclablending operation. - Imágenes reciente método de reparación:
- No utilizar el enfoque de aprendizaje profundo es el uso de la no-falta parte de la información estadística imagen para suplir la falta de partes para lograr la imagen reparación.
PatchMatch - Utilizando el método de aprendizaje profundo es principalmente la porción de píxeles de relleno fijo en valores y operaciones de convolución que faltan en estas imágenes, estos métodos están afectadas depende del valor inicial del agujero, que generalmente presenta una falta de región de agujero textura, color distinto contraste o fenómeno por el hombre alrededor del borde del agujero. Y el marco de la red a menudo se utiliza
U-Netla arquitectura. - Sobre los objetivos de trabajo para lograr la independencia de la parte del valor de inicialización falta y hay ningún tratamiento adicional después de la fusión de perder una buena parte de la previsión. Y permitir la reparación de falta irregular.
- No utilizar el enfoque de aprendizaje profundo es el uso de la no-falta parte de la información estadística imagen para suplir la falta de partes para lograr la imagen reparación.
- convolución parte de la capa de diseño,
comprising a masked and renormalized convolution operation followed by a mask-update step.(masked and re-normalized convolutionmás común en la segmentación de imágenes, también llamadosegmentation-aware convolutions, pero no tiene quemaskser modificado.) - convolución parte del diseño,
given a binary mask our convolutional results depend only on the non-hole regions at every layer.los autores también se extiende alautomatic mask update step,principioremoves any masking where the partial convolution was able to operate on an unmasked value.como capa de entidad siempre y cuando un número suficiente de capas, la parte que falta se desaparecen constantemente actualizada. Esto no tiene nada que ver con el contenido de las partes que faltan (sin tener en cuenta el contenido de la parte que falta de la inicialización). - La principal contribución de este trabajo:
- máscara automática hecho con el paso de actualización
automatic mask updatecapa porción de convoluciónpartial convolutions. - Con
skip linksconvolución típica T-Net se puede conseguir un buen efecto de solucionar, pero podemos probar Recibe los últimos parches resultan Parte convolución capa y la máscara de convolución en lugar de la actualización. - A nuestro entender, en primer lugar demostrar la efectividad del modelo de restauración de la imagen de capacitación sobre los agujeros de forma irregular.
- Se propone un conjunto de datos grande máscara irregular, el conjunto de datos está a disposición del público, con el fin de reparar el modelo de la futura formación y evaluación.
- máscara automática hecho con el paso de actualización
Acercarse
Parte de la etapa máscara de convolución y actualización de modelos nos proponemos utilizar la pila para llevar a cabo la restauración de imágenes. Definimos primero las máscaras de convolución y mecanismo de actualización, a continuación, analizar el modelo de arquitectura y pérdida de función.
Capa parcial convolucional
- porción de la capa de convolución
Partial Convolutional Layer, que comprende una parte de convolución de la máscara y de actualización demask updateoperaciones. - Siempre
Wes una convolución pesos del filtro peso debla desviación correspondiente.Xvalor característico (valor de píxel) de convolución actual (deslizamiento) de la ventana,Muna máscara binaria correspondientemask. Cada posición de porción de convolución se expresa como: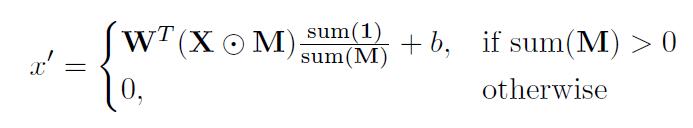 donde ⊙ denota una multiplicación pixel-sabia. Como puede verse, el valor de salida sólo depende de entrada sin blindaje. Factor de escala 1 / sum (M) adecuado para ajustar la aplicación de escala eficaz cantidad de cambio (no apantallado) de entrada.
donde ⊙ denota una multiplicación pixel-sabia. Como puede verse, el valor de salida sólo depende de entrada sin blindaje. Factor de escala 1 / sum (M) adecuado para ajustar la aplicación de escala eficaz cantidad de cambio (no apantallado) de entrada. - Después de la sección de operación de convolución, la máscara de actualización a qué reglas: Si al menos una convolución válida se puede introducir como condición para el valor de salida, entonces marcar la ubicación como válido.
 En la parte inferior de la capa de convolución tiene suficiente aplicación continua, si la entrada contiene los píxeles válidos, entonces cualquier final de todo 1 máscara.
En la parte inferior de la capa de convolución tiene suficiente aplicación continua, si la entrada contiene los píxeles válidos, entonces cualquier final de todo 1 máscara.
Arquitectura de red e Implementación
-
Implementación
Partial convolution layerSe basa enpytorchextensible.- No basado
pytorchse consigue directamente método: definir la forma de una máscara binaria es C × H × Wbinary masks, o características asociadas con la misma imagen tamaño, y luego se fija usando una capa de máscara de convolución para lograr la actualización, convolución fijado el mismo tamaño y la capa de convolución capa tamaño de la porción, los pesos de convolución del núcleo son todos 1, no compensados.
-
Diseño de red
- Red-como la estructura U-red, en lugar de todas las capas en todo convolución porciones de convolución, y se utiliza en la etapa de decodificación
nearest neighbor up-sampling. Utilizado en la etapa de codificaciónReLu, que se utiliza en la fase de decodificación de alfa = 0,2LeakyReLU. Cada porción de convolución y fuera de la primera capa y la última convolución deReLu/LeakyReLUla capa de volumen usando normalizado entre las capas.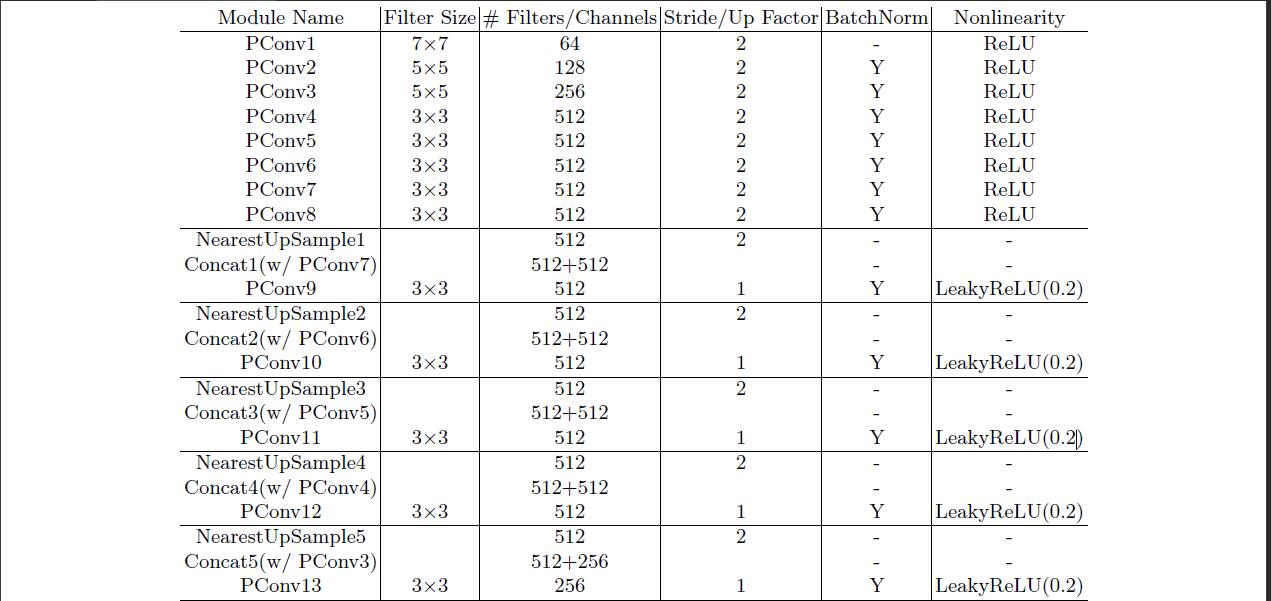
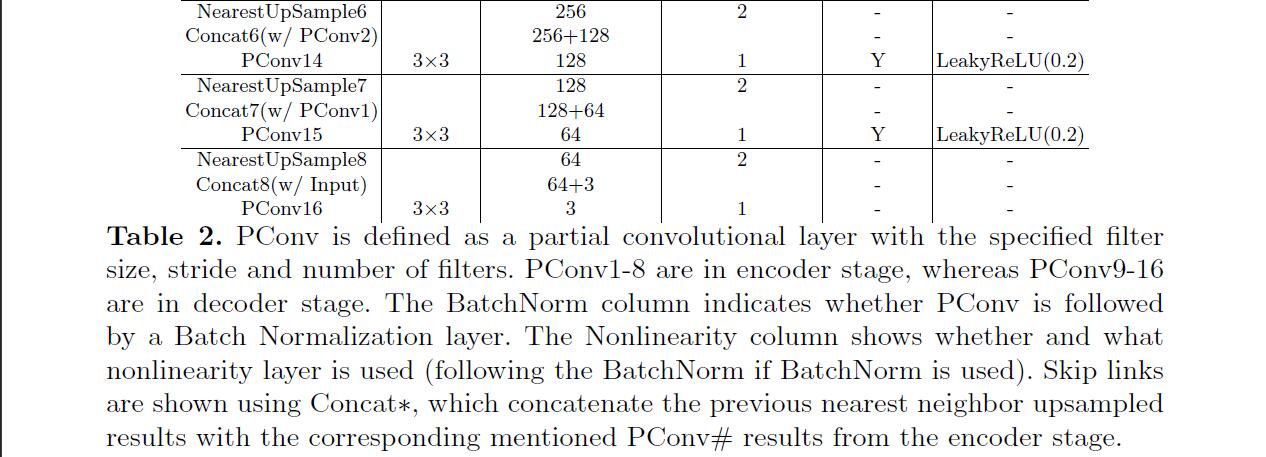
- Red-como la estructura U-red, en lugar de todas las capas en todo convolución porciones de convolución, y se utiliza en la etapa de decodificación
-
La convolución parcial como relleno
- Utilizamos algunos convolución de la imagen en el límite con la máscara apropiada en lugar de la típica llena. Esto asegura que el contenido de la imagen se ha fijado en la frontera no se verán afectados por valor no válido que la imagen, estos valores pueden interpretarse como otro agujero.
-
función de pérdida
- 定义:
input image with hole\ (I_ {in} \) ,initial binary mask\ (M \) (0 para los agujeros),the network prediction\ (I_ {a cabo} \) , ythe ground truth image\ (I_ {gt} \) - Incluye función de pérdida de cinco, a saber:
perpixel losses\ (L_ {agujero} \) yperceptual loss\ (L_ {perceptual} \) ystyle-loss(\ (L_ {StyleOut} \) y \ (L_ {stylecomp} \) ) ytotal variation (TV)\ (L_ {tv} \) perpixel losses: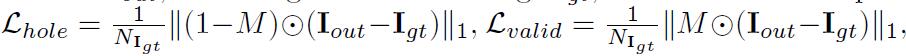

perceptual loss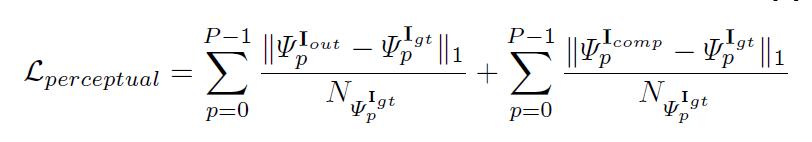
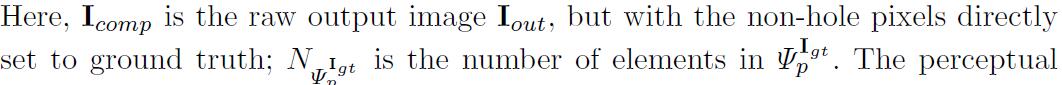
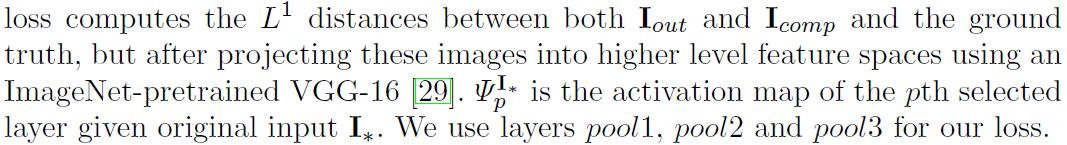
style-lossEn primer lugar, la aplicaciónL1antes de realizar una autocorrelación ((la matriz de Gram) en cada característica en la figura.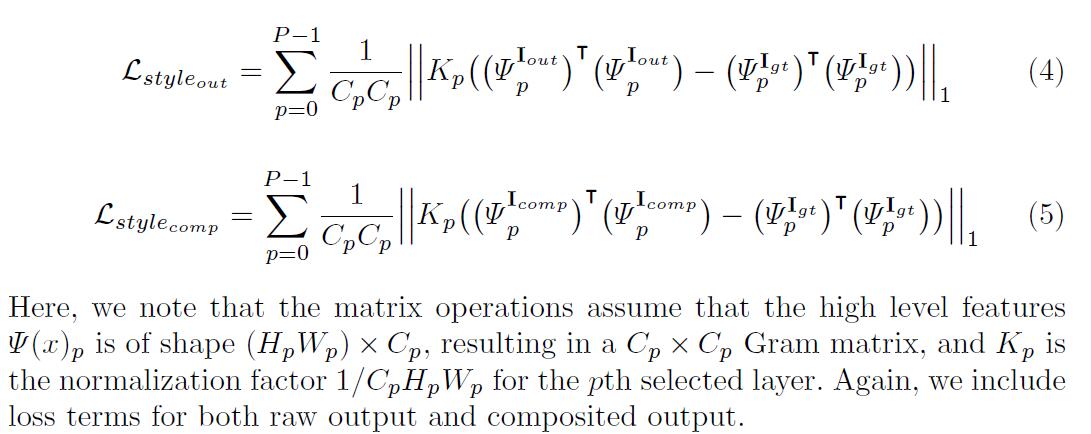
total variation (TV)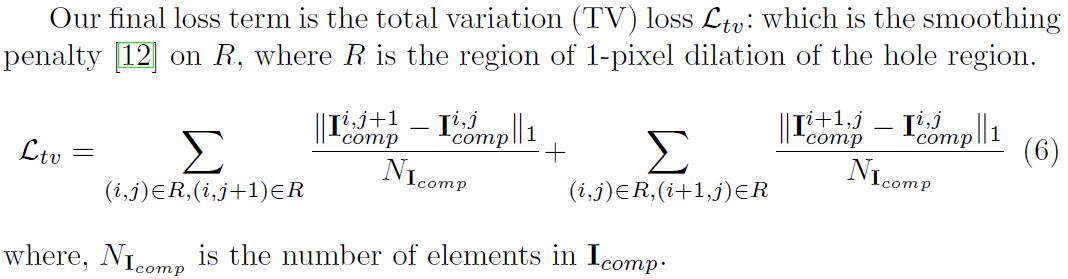
- pérdida total \ (L_ {totales} \)
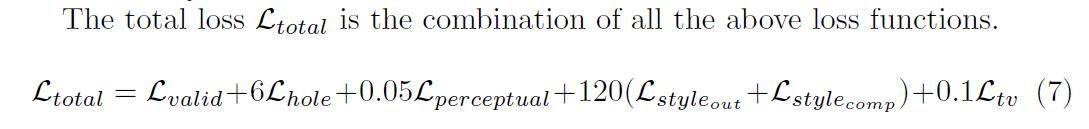
- 定义:
-
Estudio de la ablación de términos diferentes, la pérdida (pérdida de la función de los diferentes experimentos de ablación)

experimentos
Máscara irregular del conjunto de datos
- Todas las máscaras y la imagen a tamaño se utiliza para la formación y las pruebas
512×512. - Tuvimos que entrenar
55116másMasky produjimos para probar24866una máscara. - Cuando se probó en
24866unaMaskmejora de los datos llevado a cabo. - Al mismo tiempo, tenemos más
Maskla clasificación por tamaño.
Proceso de entrenamiento
Datos de entrenamiento
- Imagen mediante tres conjuntos separados de entrenamiento y de prueba de datos,
ImageNetconjuntos de datos,Places2conjuntos de datos, yCelebA-HQ.
Procedimiento de Formación
Adam for optimizationBatchSize:6
Formación inicial y puesta a punto
- eliminación de la imagen, la normalización de lotes tendrá un impacto, ya que la media y la varianza se calculan para los píxeles que faltan, así que tiene sentido hacer caso de ellos en un lugar protegido. Sin embargo, cada aplicación se llena gradualmente de la cavidad, y por lo general se realiza por completo por la etapa de decodificador. Para utilizar el lote en presencia de agujeros normalizado, primero permitimos lote normalizado usando la tasa de aprendizaje de 0,0002 formación inicial. A continuación, utilizamos para ajustar la velocidad de aprendizaje de 0.00005, por lotes y parte congelación de los parámetros del codificador de normalización de la red. Seguimos siendo permitido la normalización de lotes en el decodificador. Esto no sólo evita los problemas de media y varianza incorrectas, sino también para ayudar a lograr una convergencia más rápida.
Las comparaciones
-
En comparación con los cuatro métodos siguientes:
nombre del método característica PM PatchMatch, el enfoque no basado en el aprendizaje del estado de la técnica GL Método propuesto por Iizuka et al. GntIpt Método propuesto por Yu et al. Conv estructura de la red Igual que nuestro método pero usando capas típicas convolucionales. pesos de pérdida se volvieron a determinaron a través de la búsqueda hiperparámetro. PConv la nuestra
Las comparaciones cualitativas


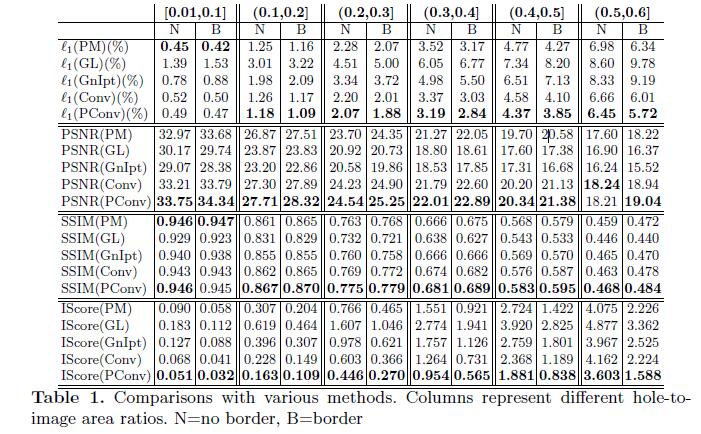
Las comparaciones cuantitativas.
- Evaluar los resultados de la restauración de la imagen no es mejor métodos de evaluación.
- Los criterios de evaluación son los siguientes:
L1 error,PSNR,SSIM,inception score (IS-core). - En donde
L1 error,PSNR,SSIMel conjunto de datosPlaces2de evaluación,Inception score (IS-core)establecer los datosImageNetevaluados.
propagación
- Parte de convolución aplicado a la super-resolución de imagen