Q1. ¿Por qué utilizar una cola de mensajes? (Cola de mensajes Escenario?)
R: En primer lugar la cola de mensajes es una estructura "FIFO" de datos, en segundo lugar, un papel importante en la cola de mensajes son: desacoplamiento, asíncrono, recorte, seguido breve explicación de lo anterior tres puntos

antes del desacoplamiento: el día de hoy Internet Software el diseño arquitectónico no sólo se ha limitado a los monómeros tradicionales y viejos patrones de diseño arquitectónico y verticales, y cada vez más SOA y arquitectura distribuida diseñada para ser aplicada por los distintos negocios de todos los tamaños, ya sea entre el servicio de llamada RPC o llama RELAJANTE se ha convertido en la norma, que necesita un módulo de servicio a la llamada B, C, etc. más módulos para completar sus necesidades de negocio, mayor será el grado de acoplamiento entre los módulos, menor será la tolerancia a fallos, se llama un módulo fracaso podría llevar al fracaso de todo el negocio, el impacto de las ventas y los usuarios de negocios a utilizar, lo que no podemos aceptar
la desvinculación: después de usar la cola de mensajes MQ, reduciendo el grado de acoplamiento entre los módulos, para mejorar la tolerancia a fallos, si una después de un módulo se llama se produce una excepción, que no afectará a la empresa en general, sólo es necesario para el servicio después del consumo cola de la reparación puede mejorar considerablemente la experiencia del usuario
Asíncrono hace: Un acuerdo de auto-servicio con su propio negocio lleva 20 ms, llamada B, C, D cada servicio lleva 200 ms, 300 ms, 400 ms, el costo total para completar la llamada de servicio 20 + 200 + 300 + 400 = 920ms, la cual no podemos tolerar
después asíncrono: un acuerdo de autoservicio con su propio negocio lleva 20 ms, un mensaje a la toma MQ 5 ms, el tiempo total de 20 + 5 = 25 ms, reducir considerablemente el tiempo y mejorar el tiempo de respuesta, mejorar la experiencia del usuario
Antes de recorte: Si hay un aumento de los negocios, al inicio de actividad pico, los usuarios se dispararon, directamente sobre el gran número de solicitudes abruma el sistema, lo que lleva al colapso de todo el servicio
después de recorte: el uso de la cola de mensajes MQ, el gran número de mensajes almacenados en caché dispersado en un tiempo relativamente largo para el proceso, la solicitud no sea consumido por el sistema de inmediato para garantizar la disponibilidad del sistema y la experiencia de usuario
Q2. Comparar producto Message Queue?
R: preámbulos, por primera vez en el mapa
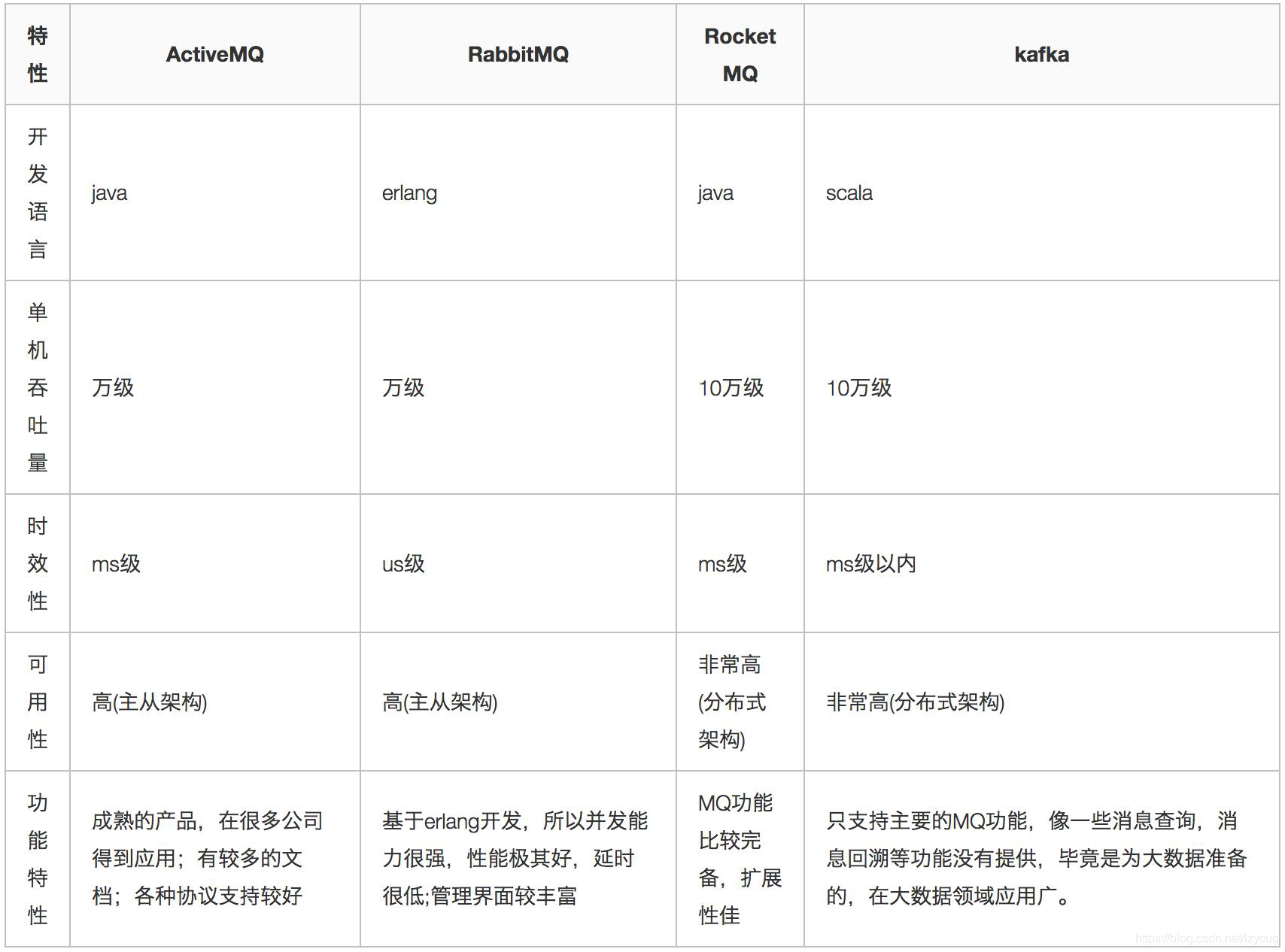
en el mapa del mercado común, ActiveMQ, RabbitMQ, RocketMQ, Kafka hizo una comparación de cuatro productos, principalmente a su lenguaje de desarrollo, solo el rendimiento, puntualidad, disponibilidad y propiedades funcionales una comparación
basada en la figura da un resumen breve de la persona:
ActiveMQ: un producto MQ temprano, no probada a gran escala de rendimiento de escena, la comunidad no es muy activa, pero ahora no lo hacen mucho uso, y no se recomienda
RabbitMQ : lenguaje de desarrollo de Erlang para bloquear un gran número de ingenieros de Java ir a estudiar en profundidad y controlarlo, para las empresas, casi en un estado incontrolable, pero RabbitMQ es de código abierto, el apoyo relativamente estable, la actividad es alta, sin tener en cuenta secundaria el desarrollo, la búsqueda de rendimiento y estabilidad, recomienda
RocketMQ: desarrollo del lenguaje es Java, sometido a operaciones simultáneas excesivos dentro de la prueba Ali, la estabilidad y el rendimiento son buenas, este último puede ser considerado desarrollo secundario, se recomienda
Kafka: campo de datos grande tiempo real, la recopilación de registros y otras escenas, con Kafka es el estándar de la industria, un alto grado de activistas de la comunidad, se recomienda. Grandes áreas de la recogida de datos de registro y otros servicios recomendados
Q3. Ventajas y desventajas cola de mensajes?
R: De hecho, las ventajas de utilizar MQ se ha dado una pregunta en nuestro interior está desacoplado, asíncrono, recorte, pero la tecnología es una espada de doble filo, MQ no es una excepción, serán traídos para resolver algunos de los problemas otros problemas, hacer la siguiente declaración simple de los inconvenientes del uso de MQ:
- La menor disponibilidad del sistema: MQ es un producto de middleware, introducimos middleware externo, está obligado a pasar necesidad de un esfuerzo adicional para mantenerla, si el tiempo de inactividad MQ middleware dará lugar a todo el sistema inutilizable (derivaciones a las preguntas: cómo garantizar una alta disponibilidad de la cola de mensajes, lo siguiente será responder)
- La complejidad del sistema aumenta: Anteriormente ningún middleware, las llamadas remotas entre sistemas es sincrónico, después de la adición de MQ, se convirtió en una llamada asincrónica (introducción de cuestiones: cómo garantizar que el mensaje no se pierde, y cómo asegurar que los mensajes no se repitan el consumo, la forma de garantizar el orden del mensaje)
- implicaciones Consistencia: sistema A de tráfico procesados por MQ a B, C, D tres datos de sistema de mensajería, si el sistema B, C sistema de procesamiento con éxito, el procesamiento del sistema D falla (pregunta incorporado: cómo garantizar la consistencia del procesamiento de datos de mensaje )
Q4. ¿Cómo asegurar una alta disponibilidad de la cola de mensajes?
R: En primer lugar la palabra: "grupo", seguido de las colas de mensajes para diferentes productos, que no son el camino para alcanzar el mismo clúster
de alta disponibilidad RabbitMQ en base a un modo maestro-esclavo. RabbitMQ tiene tres modos: modo autónomo, lo normal en racimo modo, el modo de espejo clúster.
- Stand-alone modo:
el modo independiente es el nivel de demostración, la producción no está en uso. - el modo de clúster ordinaria
modo normal es comenzar múltiples instancias de clúster RabbitMQ en varias máquinas, cada máquina un comienzo. Sin embargo, la cola se crea sólo en un RabbitMQ los anteriores ejemplos, pero otros ejemplos se sincronizan los metadatos de la cola. Cuando se consumen, si la conexión a otra instancia, recibirá el mensaje de la instancia propietario de la cola y luego de nuevo a usted

- Los ejemplos se inician RabbitMQ en varias máquinas
- Se comunican entre sí a través de varias instancias
- Cola crea únicamente en un RabbitMQ, otros casos se mantienen sincronizados metadatos
- El consumo de tiempo, si la conexión no es cola, entonces la instancia actual será extraer datos de la instancia de cola, donde
Características:
ninguna realmente alta disponibilidad
de datos y los gastos generales que tira de un solo caso de cuellos de botella
En pocas palabras: Este modo no proporciona alta disponibilidad, este enfoque sólo aumenta el rendimiento, que es dejar más de un nodo del clúster para servir a una cola de las operaciones de lectura y escritura
- La creación de reflejo modo de clúster
se proporciona este modo RabbitMQ es un verdadero modo de alta disponibilidad, con el racimo de ordinario no es el mismo, se creó la cola, o si los metadatos dentro de los datos de cola de mensajes entre varias instancias están presentes, entonces cada cuando se escribe un mensaje a la cola, lo hará automáticamente los mensajes a múltiples colas de mensajes en sincronía
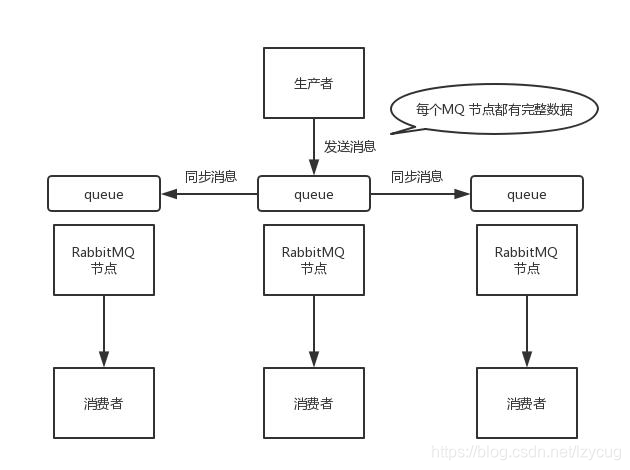
- Los ejemplos se inician RabbitMQ en varias máquinas
- Se comunican entre sí a través de varias instancias
- Cada vez que el productor de escribir un mensaje a la cola, el mensaje automáticamente se sincronizará que hacer cola varias instancias. Cola en cada nodo tiene RabbitMQ datos de mensajes y metadatos
- Un nodo se cae, los demás nodos de los datos sigue intacta, no afecta el cliente consumidor
La ventaja de este modelo es que cualquier máquina uno va hacia abajo, la otra máquina también se puede utilizar.
Desventaja es que: 1, consumen demasiada rendimiento, todas las máquinas deben estar sincronizados mensaje, resulta de la presión en la red y consumen mucho. 2, ninguna extensión, si hay una cola de una carga pesada, incluso si el incremento de la máquina, la nueva máquina también contiene todos los datos de la cola, y no hay manera de ampliar la cola.
¿Cómo puedo convertir el modelo de clúster espejo: una nueva estrategia reflejado el modo de clúster en la consola, el tiempo especificado puede requerir la sincronización de datos en todos los nodos pueden sincronizarse con los requisitos de nodo especificado, y luego crear una cola en la aplicación de esta estrategia, lo hará automáticamente los datos se sincronizan con otros nodos para ir por encima
RocketMQ HA - dual maestro de bis
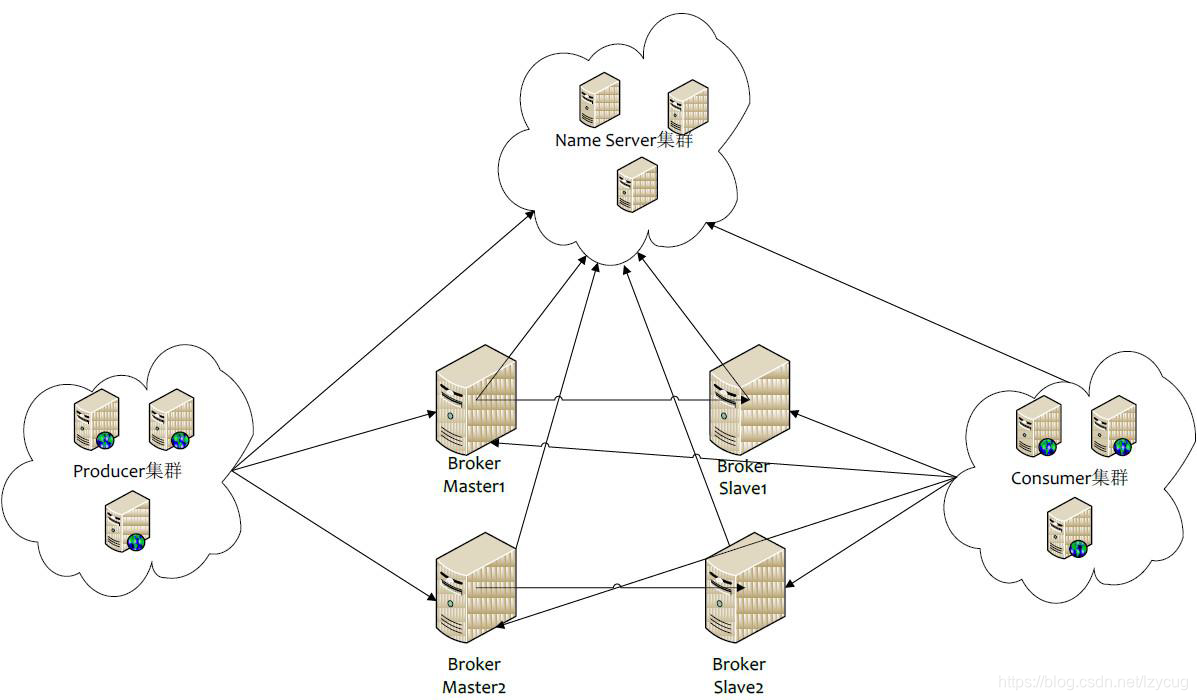
- Los productores que se encuentran por el Corredor Nombre del servidor
- Fabricante mensaje de cola de envío al nodo maestro 2 Broker
- Broker nodo maestro de sincronización, respectivamente, y los datos respectivos de nodo
- Los consumidores suscribirse al nodo desde el maestro o
Kafka disponibilidad
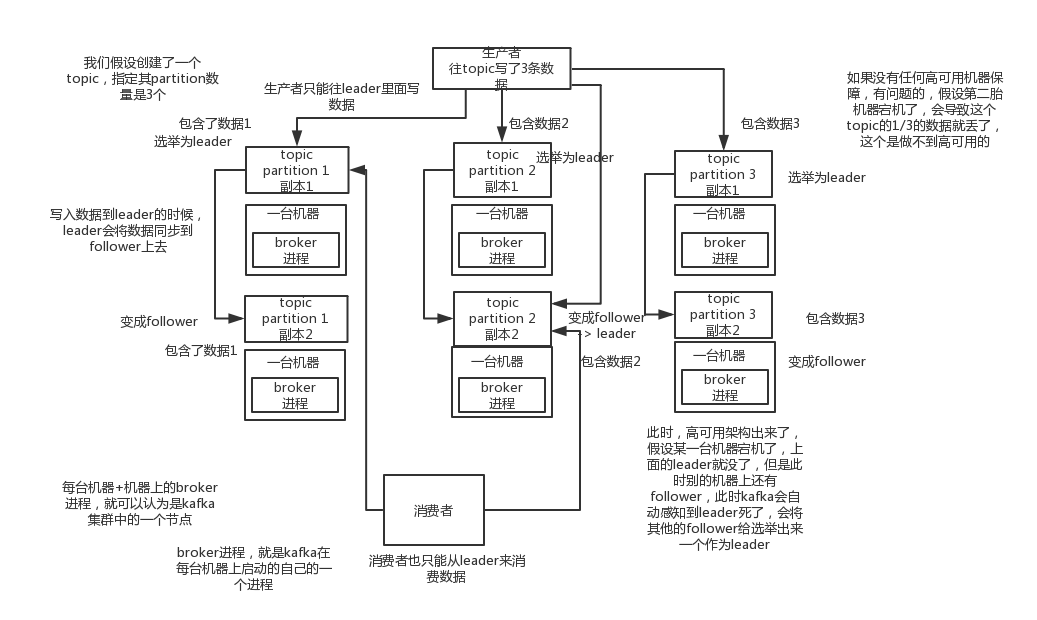
kafka una comprensión básica de la arquitectura: corredor múltiple, cada corredor es un nodo; se crea un tema, este tema puede dividirse en varias particiones, cada partición puede existir en un corredor diferente, cada uno partición para poner parte de los datos.
Se trata de una cola de mensajes distribuido natural, que es un tema de datos se dispersa en varias máquinas, cada máquina para poner una porción de los datos.
De hecho RabbitMQ y la cola de mensajes como, no se distribuyen, es la cola de mensajes, pero ofrece algunas agrupaciones, HA mecanismo de ella, porque no importa cómo el juego, los datos RabbitMQ se coloca en una cola de un nodo lane, reflejando el clúster, cada nodo se pone en la cola de datos completo.
kafka 0,8 anterioridad, no existe un mecanismo de HA es cualquier corredor está abajo, partición en ese corredor de los residuos, no se puede escribir son incapaces de leer, nada que hablan de una alta disponibilidad.
Después de kafka 0.8, proporciona mecanismo de HA es el mecanismo de copia de réplica. Cada partición de datos estará sincronizado con la máquina de la guitarra, para formar sus propias copias múltiples réplicas. Toda la réplica a continuación, elegir a un líder, entonces el líder de la producción y el consumo están relacionadas con este acuerdo, a continuación, otra réplica es seguidor. El momento de la escritura, el líder de la sincronización de datos será responsable de todo el seguidor a ir, cuando leyó los datos se pueden leer directamente líder. Puede leer y escribir líder? Muy simple, si usted es libre de leer y escribir cada seguidor, entonces ellos se preocupan problema de consistencia de los datos, la complejidad del sistema es demasiado alto, es fácil equivocarse. kafka de todo réplica distribuye uniformemente en una partición diferente máquinas, por lo que puede aumentar la tolerancia a fallos.
Tales actividades, existe la llamada de alta disponibilidad, ya que si un corredor está abajo, está bien, el corredor por encima de partición en las otras máquinas tienen una copia si hay una partición de este máximo líder, por lo que en este momento se volverá a elegir a un nuevo líder a cabo, seguimos a leer y escribir el nuevo líder puede ser. Esta es la llamada alta disponibilidad.
Cuando se escriben datos, escribió el productor líder, entonces líder va a escribir datos en un disco local baja, a continuación, otra seguidora por su propia iniciativa a los datos de extracción del líder. Una vez que todos los datos son buenos sincronización seguidor, que será enviado a la ACK líder, acuse de recibo después de recibir toda seguidor del líder, volverá a los mensajes de escritura al productor de éxito. (Por supuesto, esto es sólo un modo, este comportamiento puede ajustarse apropiadamente)
El consumo de tiempo, sólo en el líder de leer, pero sólo un mensaje se ha sincronizado con éxito en todo seguidor han regresado acuse de recibo cuando la noticia será leído por los consumidores.
De hecho, este mecanismo, charla profunda, puede ser muy profunda, pero todavía volver atrás y buscar el tema de nuestro programa, entrevista, al menos has oído aquí centrado entienden generalmente la forma Kafka es para asegurar la alta disponibilidad mecanismo , ¿verdad? No sabremos nada sobre el sitio, sino también al entrevistador para dibujar la carta. Al encuentro con el entrevistador es muy kafka maestro, la excavación de una pregunta, a continuación, sólo se puede decir que lo siento, no eres demasiado profundamente estudiados.
Pero hay que entender que esto es una solución de compromiso, que son rápidos para detectar sistema de preguntas de la entrevista común, en lugar de kafka estudio en profundidad, debe estudiar a fondo kafka, usted no es mucho tiempo. Sólo se puede estar seguro de que, tal vez usted no sabía que antes de esto, pero ahora ya sabes, se solicitó a la entrevista, es probable que pueda hablar. A continuación, una gran cantidad de otros candidatos, tal vez no tan bueno como usted, no han visto esto, se le pidió simplemente no respondió, por el contrario, señalan que se puede decir, es probable que sea el punto.
Q5. ¿Cómo asegurarse de que los mensajes no se pierden?
R: En primer lugar, permítanme analizo lo que podría pasar mensajes perdidos
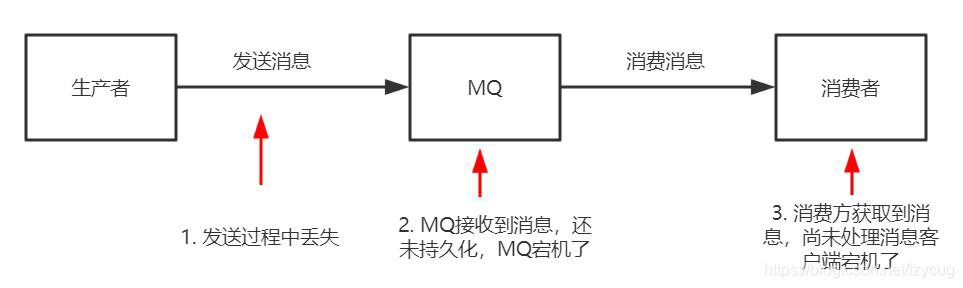
1, cuando el productor a la cola de mensajes MQ, posiblemente debido a la fluctuación de la red y otras razones perdieron mensajes se presentan
2, MQ recibe el mensaje enviado por el productor, aún no ha tenido tiempo de almacenamiento persistente, cortes de energía y otras causas de pérdida de mensajes
3, los consumidores obtener el mensaje tras mensaje de la MQ, y sin embargo no ha tenido que lidiar con el mensaje de que los consumidores tiempo de inactividad que resulta en la pérdida de mensajes
de análisis claramente pueden conducir a la pérdida de mensajes la razón por la que puede adoptar diferentes estrategias para diferentes etapas para evitar la pérdida de mensajes
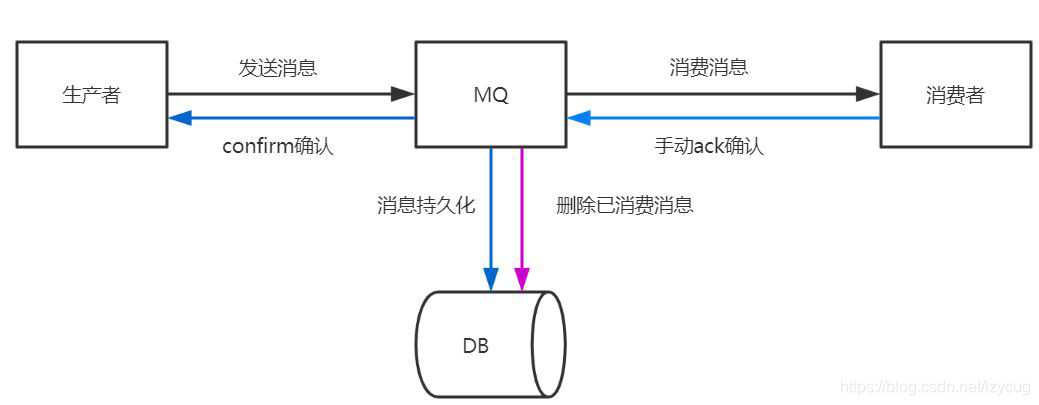
1, después de que el productor envía un mensaje a MQ, MQ necesita confirmación para confirmar
2, el mensaje MQ se recibe mensaje oportuno persistencia,
3, consumidores después de recibir el mensaje procesado confirmar ack manualmente
4, MQ después de recibir confirmación ACK consumidor la eliminación de mensajes persistentes
Q6. ¿Cómo asegurarse de que los mensajes no se repiten consumo? (Tales como la forma de asegurar el poder del mensaje?)
R: En primer lugar, cabe señalar que los mensajes duplicados son inevitables, debido a que la causa de la raíz se repite cadena de noticias inalcanzable, ya que repite el mensaje no se puede evitar, que tenemos que hacer es cómo asegurar que los mensajes duplicados no se repitan el consumo, que el poder del mensaje equivalencia
- Repetir el mensaje se envía
cuando un mensaje ha sido enviado con éxito al servidor, la red aparece flash, lo que resulta en el servidor al cliente no reconoció. Si en este momento los productores se dieron cuenta de que no pudo enviar el mensaje y tratar de enviar el mensaje de nuevo, los consumidores seguimiento recibirán el mismo contenido del mensaje de dos

- Cuando el mensaje se repite el consumo de
consumo de noticias escenario, el mensaje ha sido entregado al tratamiento de consumidores y empresas se ha completado, cuando la retroalimentación de los consumidores al tiempo de respuesta del servidor MQ a la desconexión de la red. Con el fin de garantizar que los mensajes se consumen al menos una vez, los intentos de servidor MQ han sido tratados antes de la entrega de las noticias de los consumidores de nuevo después de que se restablezca la red, esta vez los consumidores recibirán el mismo contenido del mensaje dos

soluciones:
- Llevar un mensaje de identificación único a nivel mundial para enviar un mensaje al remitente del mensaje
- Después de obtener el primer consumo de los consumidores sobre la base de la existencia de registros de consumo en el ID de la consulta ReDiS / db en
- Si no hay un consumo excesivo de consumo normal, completas escritas Redis post-consumo / db
- Si el mensaje es demasiado el consumo directo o abandonar actualización
Por supuesto, esto es sólo una solución ideas básicas expuestas, existen diferentes soluciones para diferentes productos MQ, pero la idea general no se desvían de lo anterior, podemos encontrar soluciones más detallada en Internet, no aquí en elaborada
Q7. ¿Cómo garantizar que el orden de los mensajes?
A: se refiere al mensaje se puede ordenar según el orden de transmisión del consumo mensajes.
Por ejemplo: una orden tenía tres mensajes, a saber, la creación de pedidos, órdenes de pago, el pedido se ha completado. Cuando el consumo, de acuerdo con el orden de consumo tiene sentido. Al mismo tiempo entre varios pedidos es el consumo paralelo.
para el consumo local
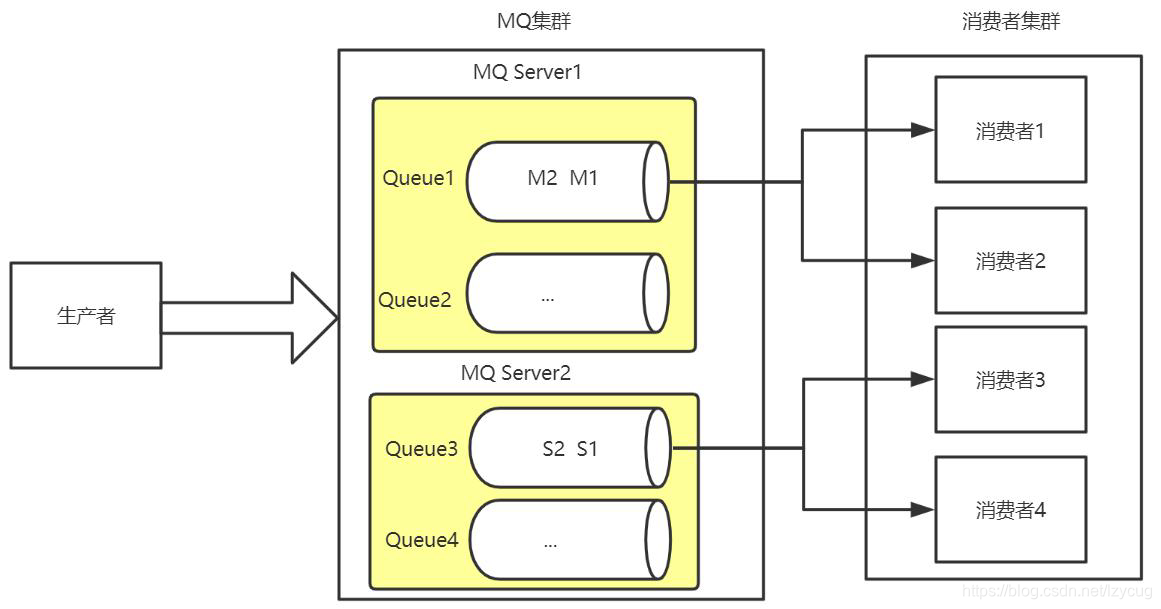
- Productores de enviar el mismo mensaje a un mensaje de grupo de acuerdo con el Identificador de Cola
- Múltiples consumidores adquieren simultáneamente mensajes de cola para el consumo
- MQ utilizando el bloqueo del segmento para asegurar el consumo ordenada en una sola cola
Q8. Acumulación proceso de cómo hacer frente a un gran número de mensajes?
R: En primer lugar, la acumulación de una gran cantidad de mensajes de posibles motivos
Consumidor no hace que el mensaje no es el consumo normal:
- fallo en la red
- Post-consumo procesa el mensaje no responde normalmente a la MQ Servidor

Solución:
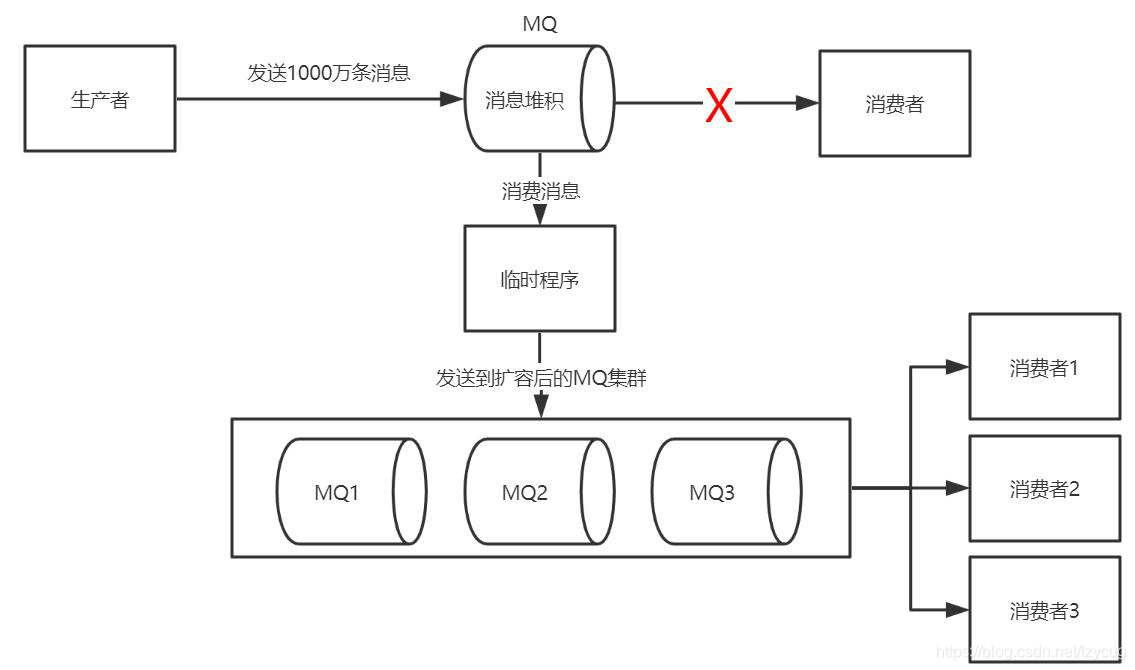
3. La verificación y reparación la tasa de consumo normal de los consumidores
4. mayor clúster mensaje volcado capacidad MQ
5. Mayor pluralidad consumo de nodos consumidores en mensaje masiva paralela
6. Cuando se termina el consumidor, restaurar el esquema original
Mensaje de caducidad Q9. cómo hacer frente a
A: La razón caducado genera mensajes?
- Noticias establece una fecha de caducidad
- el consumo de los consumidores falló, provocando que los mensajes no han sido procesados, el mensaje caducará
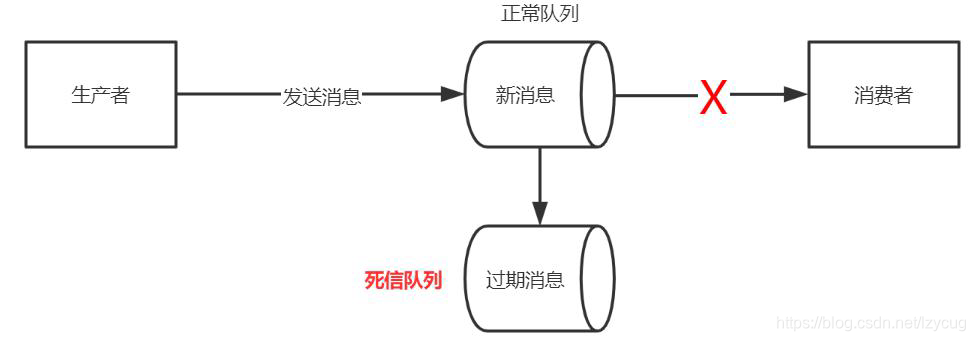
cómo manejar mensajes caducados? - cola de mensajes, aceptando mensajes caducados
- Consumidor cola de mensajes no expiró mensajes, la tala
- mensaje de re-consulta al MQ caducado
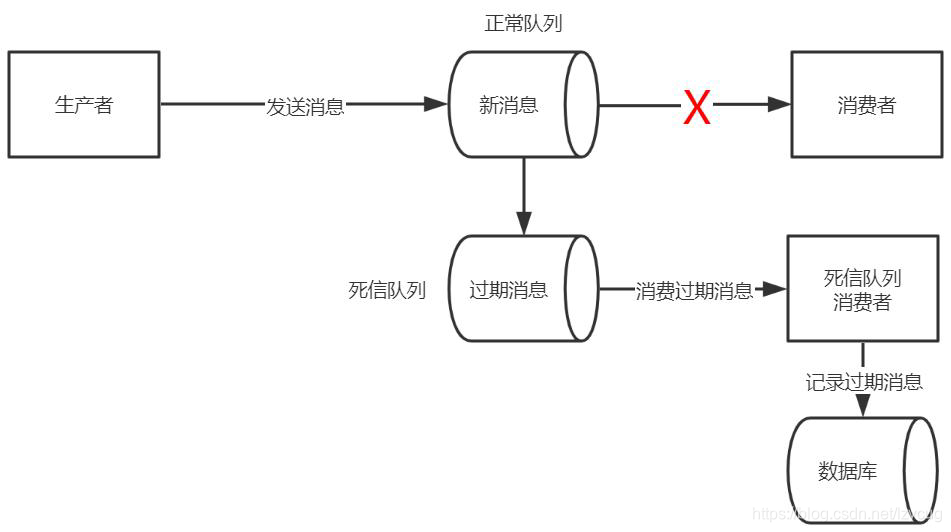
- mensajes caducados en cola de mensajes
- Iniciar un consumidor especial de pasar mensajes de cola de mensajes, y se escribe en el registro de base de datos
- Consulta el registro de mensajes de bases de datos, vuelva a enviar el mensaje al MQ
Una gran cantidad de información citada anteriormente caballo programadores de datos oscura centro de Xi'an quisiera agradecer a los maestros caballo oscuro
