word2vev the model gensim library mainly used CBOW (Huffman) and Skip-Gram model. CBOW based on the context indicates to predict the target word, the input word is 2c contexts (c indicates the window size), the output is the probability of target words; Skip-Gram is the opposite, the input is the current target word, the output word is context The probability.
After determining the input and output, in fact, training methods will be obvious, (for example CBOW) after the last input layer hidden layer output probability softmax all the words, and then back-propagation gradient descent decrease loss. But this one has a big problem: from the hidden layer to layer a large amount of calculation softmax output, because the probability to calculate softmax all the words, and then look for the maximum value of the probability. Such performance is clearly speaking for a embedding operation is worth the candle, therefore, word2vec here to do a very sophisticated optimization, based on this paper to introduce Huffman tree word2vec.
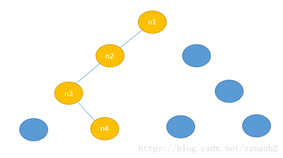
It is not difficult to know the rules of the achievements Huffman tree, each leaf node represents a target word, and each word also has a target path represents the encoding rules. In word2vec, we used logistic regression method, the provisions walk along the left subtree, then that is a negative category (Huffman tree coding 1), walk along the right subtree, then that positive class (Huffman coding tree 0) . Methods discriminate between positive and negative class category is the use of sigmoid function, for n1-n2-n3-n4 this path in terms of neural network training goal is to make the possibility of walking this path of maximum, we can give here first likelihood function:
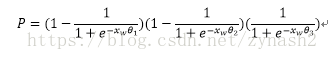
where the likelihood function is actually every step of the sigmoid quadrature, and our goal is to make the maximum probability that optimize the function by way of maximum likelihood . To give its general process, we first do some definitions:

In this case to explain the following: str = "I like to watch the world football", the target word W is football, in order to optimize the probability function, to obtain appropriate weights.






CBOW model workflow example
Suppose we now Corpus This is only a simple four word document: {I drink coffee everyday} we chose coffee as a central word, window size that is set to 2, according to the word of our "I" , "drink" and "everyday" to predict a word, and we hope that this word is coffee.






