By contrast to this article we explain in detail the explanation in Python2 and Python3 difference in urllib library and usage, a friend in need to follow to learn under the bar.
This article describes urllib changes in different versions of the library in Python, and to explain the relevant Python3.X usage urllib library.
urllib library control Issue 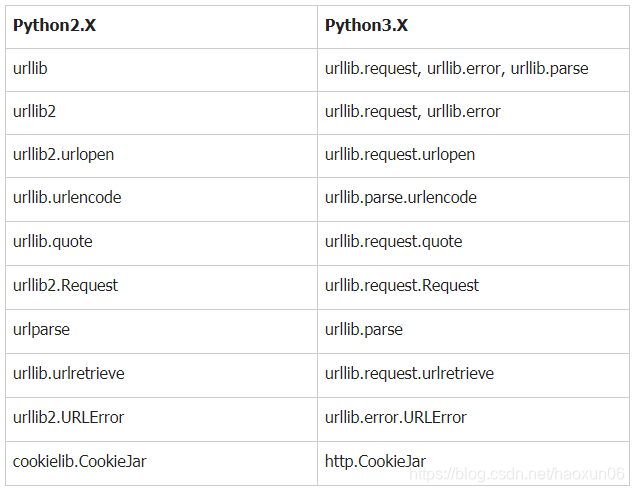
urllib library is used to operate URL, python crawling pages of third-party libraries, the same library as well as requests, httplib2.
In Python2.X, the sub-urllib and urllib2, but in the Python3.X are merged into a unified urllib in. Changes which can be seen by the common table, according to the change quickly write the corresponding version of the python program.
Relatively speaking, Python3.X support for the Chinese friendly than Python2.X, so the next blog to introduce some of the common uses urllib library by Python3.X.
send request
import urllib.request
r = urllib.request.urlopen(<a href="http://www.python.org/" rel="external nofollow">http://www.python.org/</a>)
Urllib.request first import module using the urlopen () sends a request to the URL parameters, returns a http.client.HTTPResponse object.
In the urlopen (), a timeout field, after the appropriate number of times can be set to stop waiting for a response. In addition, it can also be used r.info (), r.getcode (), r.geturl () to obtain the corresponding current environmental information, status code, the current page URL.
Read the contents of the response
import urllib.request
url = "http://www.python.org/"
with urllib.request.urlopen(url) as r:
r.read()
Use r.read () to read the contents of the memory in response, the content page's source code (using the corresponding browser "view source" function to see), and for decoding the returned string corresponding decode () .
URL parameter passed
import urllib.request
import urllib.parse
params = urllib.parse.urlencode({'q': 'urllib', 'check_keywords': 'yes', 'area': 'default'})
url = "https://docs.python.org/3/search.html?{}".format(params)
r = urllib.request.urlopen(url)
A string dictionary by urlencode () encoded data transmitting URL query string,
params encoded as a string, each key-value pairs in the dictionary '&' connection: 'q = urllib & check_keywords = yes & area = default'
URL after the building: https: //docs.python.org/3/search.html q = urllib & check_keywords = yes & area = default?
Of course, the urlopen () constructed directly supported URL, the request simply may not get () is encoded, construct a direct request by manually urlencode. The method described above makes the code modular, more elegant.
Parameters passed Chinese
import urllib.request
searchword = urllib.request.quote(input("请输入要查询的关键字:"))
url = "https://cn.bing.com/images/async?q={}&first=0&mmasync=1".format(searchword)
r = urllib.request.urlopen(url)
The URL is the use of pictures bing interfaces, query keyword q pictures. If the incoming URL directly to the Chinese request, will lead to coding errors. We need to use quote (), URL-encode the Chinese keywords, you can use the corresponding unquote () to decode.
Custom request headers
import urllib.request
url = 'https://docs.python.org/3/library/urllib.request.html'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer': 'https://docs.python.org/3/library/urllib.html'
}
req = urllib.request.Request(url, headers=headers)
r = urllib.request.urlopen(req)
Sometimes when crawling some pages, there will be 403 error (Forbidden), which prohibits access. This is because the site server Headers property authenticate visitors, for example: by sending a request urllib library, the default to "Python-urllib / XY" as a User-Agent, where X is the major version number of Python, Y deputy version number. So, we need to build the Request object by urllib.request.Request (), passing a dictionary of the Headers property, analog browser.
Headers appropriate information, developers can debug tool through a browser, "Network" "Check" function tab to view the appropriate page to get or use packet capture analysis software Fiddler, Wireshark.
In addition to the above-described method can also be used urllib.request.build_opener () or req.add_header () custom request header, see the official sample.
In the Python2.X, modules, and the urllib urllib2 modules generally used together because urllib.urlencode () may encode the URL parameters, and urllib2.Request () Request object can be constructed, customization request header, and then use the unified urllib2.urlopen ( )send request.
POST request is transmitted
import urllib.request
import urllib.parse
url = 'https://passport.cnblogs.com/user/signin?'
post = {
'username': 'xxx',
'password': 'xxxx'
}
postdata = urllib.parse.urlencode(post).encode('utf-8')
req = urllib.request.Request(url, postdata)
r = urllib.request.urlopen(req)
We conduct registration, login and other operations, will transmit information via POST form.
In this case, we need to analyze the page structure, constructed POST form data, using urlencode () performs encoding processing, returns the string, and then specify the 'utf-8' encoding format, this is only because POSTdata bytes or a file object. Finally postdata transmitted by the Request () object using the urlopen () send the request.
Download remote data locally
import urllib.request
url = "https://www.python.org/static/img/python-logo.png"
urllib.request.urlretrieve(url, "python-logo.png")
Crawling pictures, video and other remote data, use urlretrieve () downloaded to the local.
The first parameter is downloaded to url, the second parameter is a stored path after downloading.
The sample download python official website logo to the current directory and returns a tuple (filename, headers).
Set the proxy IP
import urllib.request
url = "https://www.cnblogs.com/"
proxy_ip = "180.106.16.132:8118"
proxy = urllib.request.ProxyHandler({'http': proxy_ip})
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
r = urllib.request.urlopen(url)
Sometimes frequent crawling a web page, the site will be blocked IP server. In this case, the proxy IP may be provided by the above method.
First, the online site to find a proxy IP can use IP, build ProxyHandler () object, 'http' and proxy IP to a dictionary as a parameter, set the proxy server information. And then build opener object, the proxy and HTTPHandler incoming class. By installl_opener () opener provided to the global, when a transmission request by the urlopen (), will be used to transmit the corresponding request message previously set.
Exception Handling
import urllib.request
import urllib.error
url = "http://www.balabalabala.org"
try:
r = urllib.request.urlopen(url)
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print(e.code)
if hasattr(e, 'reason'):
print(e.reason)
You can use URLError class, to deal with some URL-related abnormalities. After introduction urllib.error, capture UrlError exception, since only when an abnormality occurs HTTPError (UrlError subclass), will have an abnormal state code e.code, it is necessary to determine whether there is abnormality property code.
Cookie Usage
import urllib.request
import http.cookiejar
url = "http://www.balabalabala.org/"
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cjar))
urllib.request.install_opener(opener)
r = urllib.request.urlopen(url)
Stateless when accessing web pages, Cookie session protocol to maintain state between HTTP. For example: Some sites need to log in operation, for the first time can log in by submitting a POST form, when crawling other sites under that site, you can use the Cookie to stay logged in, all without having to log in each time by submitting the form.
First, construct CookieJar () objects cjar, reuse HTTPCookieProcessor () processor, processing cjar, and - the build_opener constructed by opener object (), arranged to global, by the urlopen () sends a request
We recommend the python learning sites, click to enter , to see how old the program is to learn! From basic python script, reptiles, django, data mining, programming techniques, work experience, as well as senior careful study of small python partners to combat finishing zero-based information projects! The method has timed programmer Python explain everyday technology, to share some of the learning and the need to pay attention to small details
