- System: windows 64
- Compiler: gcc version 8.1.0 (x86_64-posix-seh-rev0, Built by MinGW-W64 project)
- Text Editor: notepad
- Console: Cmder
- Programming languages: C, Python
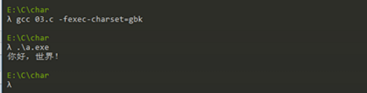
First, in order to print Chinese characters, must take into account the coding problem. Under Windows, since the coding system used GBK, UTF-8 is used when parsing and cause distortion GCC code runs the following:
#include <stdio.h> int main() { char *str = "你好,世界!"; printf("%s\n", str); return 0; }

Solution as follows: use the " -fexec-charset = GBK " command
Solve the coding problem, we also need to know that:
- That is the number of type char essentially occupies one byte (i.e., eight), can be encoded by printing% d,% c by printing characters
- In the C language, a character occupying two types char
- The two Chinese characters char type is negative
- When printing of Chinese characters, it must be followed by two char
According to these points, we can print out the characters and their coded:
#include <stdio.h> #include < String .h> int main () { // STR character pointer to a character literal, the literal character from the '\ 0' end char * STR = " Hello, ! the world the Hello, world! " ; // CHR character pointer to the address of the first character of the character literal str pointed that the first two char 'your' character in the char * CHR = str ; the printf ( " % S% zu \ n- " , strlen (STR), STR); // if they are '\ 0', indicating the end of a string of the while (! * CHR = ' \ 0 ' ) { // if chr code is negative, it indicates a Chinese character encountered IF (* chr <0 ) { // print Chinese characters and Chinese character coding // attention must be closely followed by two char printing (% c% c), otherwise it will print out ?? printf ( " % c% c:% d% d \ the n- " , CHR *, * (CHR + . 1 ), * (CHR), * (CHR + . 1 )); // CHR incremented two bytes (since each character is composed of two char composition) CHR + = 2 ; } the else { // print English characters the printf ( " % C: D% \ n- " , CHR *, * CHR); // CHR increment a byte ++ CHR; } } return 0 ; }
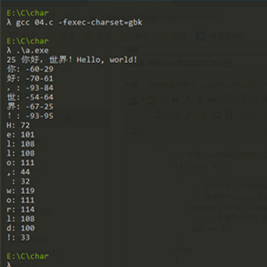
From the figure, we can see, the string occupies 25 bytes, four characters plus two full-width symbol occupies 12 bytes, plus 23 English characters, a total of 25 bytes. We can more clearly be seen from the configuration of FIG str:

However, according to the results of our online query, kanji 'you' of GBK coding should be: C4E3, but here, it prints out: -60-29, this is why?

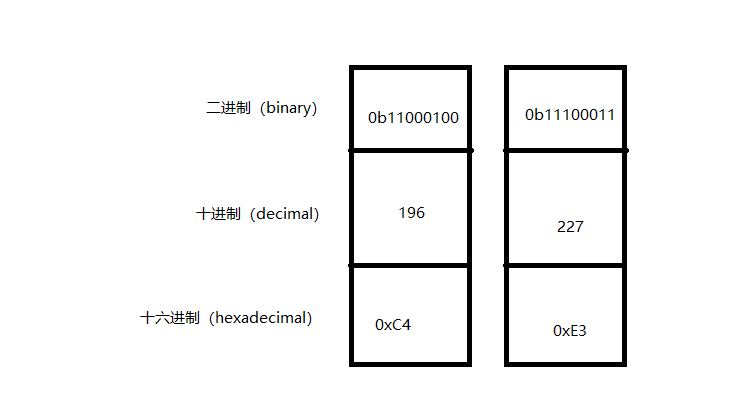
Ary issues involved here, it may -60-29 hexadecimal number C4E3 decimal?
First, let's take a look at C4E3 of binary and decimal numbers by Python. It did not seem detached with -60-29.
Let's look at the following code to import the <limits.h> header file, char type to see how much of the range:
#include <stdio.h> #include <limits.h> int main() { printf("[%d ~ %d]\n", CHAR_MIN, CHAR_MAX); printf("%c%c\n", 0xC4, 0xE3);return 0; }

我们可以看到:char类型的取值范围为[-128 ~ 127],但是我们却可以打印出汉字”你“。这是为什么呢?明明char的取值范围最多127,而汉字“你”的两个字符分别为:196和227,都超过了这个值。其实这是因为,C语言将这两个数字的二进制数作为负数处理。C中的char类型有1个字节,占8位,而它的最高位为符号位,当它为0时为正,1时则为负。C通过对正数做补码操作得到负数。补码,即对一个二进制数取反,然后再加1。比如,0xC4的二进制数为0b11000100,我们可以看到最高位1,在C中这个数就是负数。我们可以通过对这个二进制数做补码操作,得到0b00111100,即60。所以0b11000100在C中表示为-60。

从以上,我们可以发现,GBK编码中,一个汉字占两字节。因为C中char类型只占一个字节,所以需要使用两个char类型来表示汉字。一个字节能够表示的范围为[0 ~ 256],因为C中char为有符号类型,char的表示范围为[-128 ~ 127],所以在遇到大于127的数字时,会被char表示为负数。