Xpath the text () and string (.)
When we crawl the site using Xpath data extraction is the most commonly used Xpath the text () method that can extract information about the current element, but contains many elements nested under certain elements,
We want to make it extracted, this time on the use of the string (.) Method, but when the methods used are not the same with text (), would like to give the following examples to explain the specific differences.
Examples of sites: https://www.biedoul.com/wenzi/1/
E.g
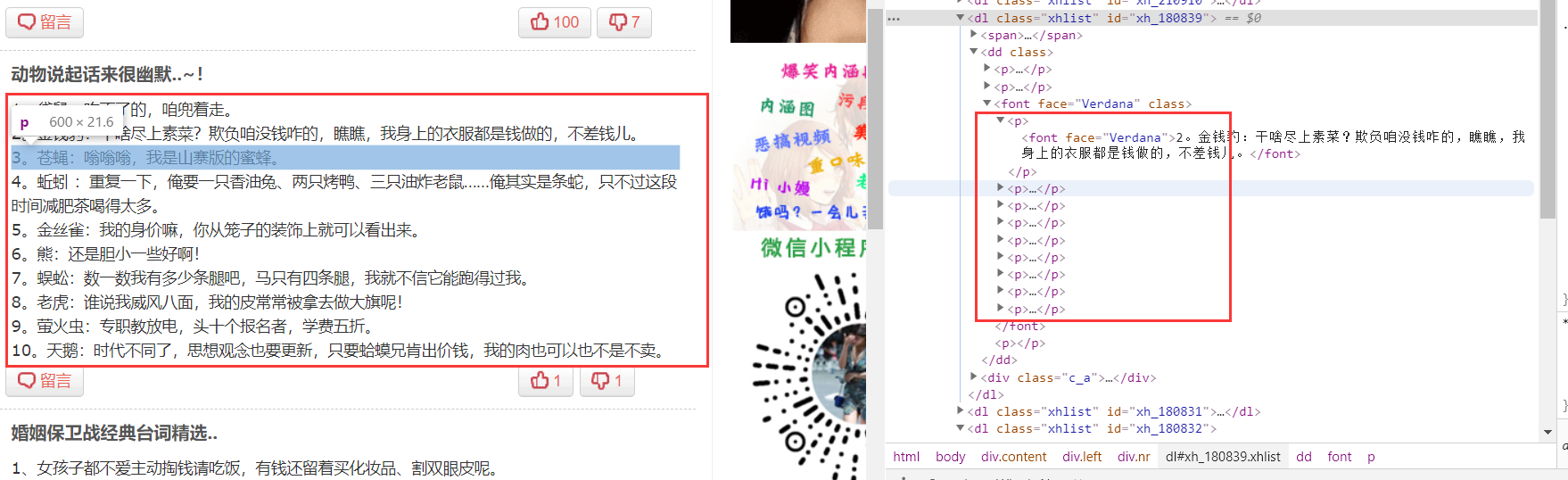
To this piece, for example, if we use the text () to pick this, you will find a piece that actually have 11 text () information, then we directly use text () to come and collect what will happen? We look at the results
We did get found, but we are the more strings to get a list, we would like to synthesize a need stitching, so we can use string (.), To see the effect
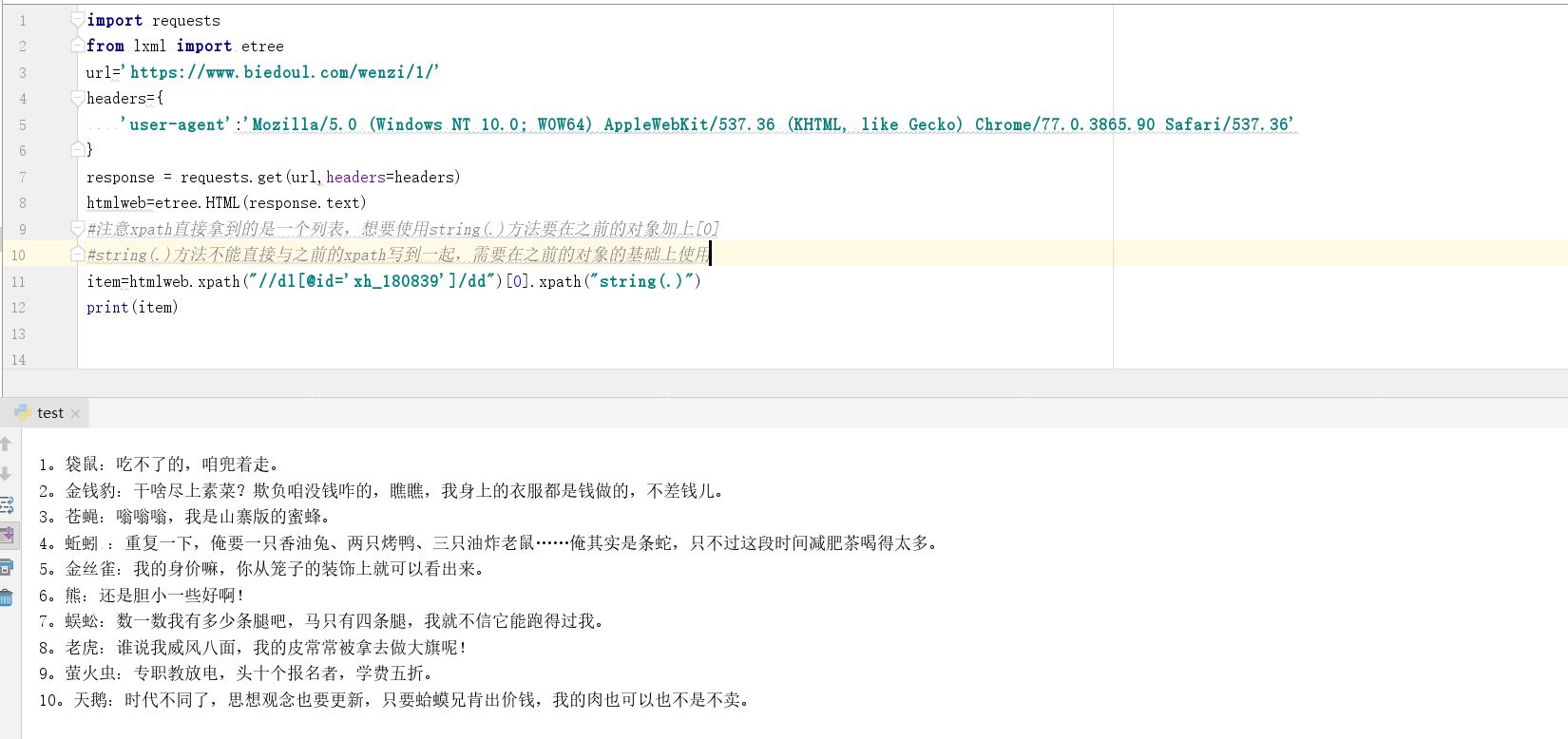
Findings now what we want, so when we need to pick up the contents of nested nodes when using the string (.) Method works better
Attach Code:
import requests from lxml import etree url='https://www.biedoul.com/wenzi/1/' headers={ 'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36' } response = requests.get(url,headers=headers) htmlweb=etree.HTML(response.text) #注意xpath直接拿到的是一个列表,想要使用string(.)方法要在之前的对象加上[0] #string(.)方法不能直接与之前的xpath写到一起,需要在之前的对象的基础上使用 item=htmlweb.xpath("//dl[@id='xh_180839']/dd")[0].xpath("string(.)") print(item)
既然写到这里了就直接附上爬取整个网站的代码吧,网站比较简单,没事用来看看段子也还凑合
import requests from lxml import etree urllist=[] #构造1000页的url for i in range(1,1001): urllist.append('https://www.biedoul.com/wenzi/'+str(i)+'/') headers={ 'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36' } number=0 for url in urllist: print('当前网站为'+str(url)) response=requests.get(url=url,headers=headers) #使用xpath时候需要先用lxml转换一下内容 htmlweb=etree.HTML(response.content.decode()) items=htmlweb.xpath("//dl[@class='xhlist']") #注意xpath拼接写法 要加上"." for item in items: print('*************************段子编号'+str(number)+'**************************************') print('title:'+item.xpath(".//dd/a/strong/text()")[0]) #string(.)方法切记如何使用 可以获取节点下所有嵌套节点内容 print('content:'+item.xpath("./dd")[0].xpath("string(.)")) number+=1 print('\n')
效果如图
