Kafka ensure data reliability and consistency
Data reliability
Kafka reliability of data can be divided into Producter send messages to the Broker, Topic Leader Election partition replicas and several angles.
Topic partition replica
To ensure the reliability of data, Kafka began to introduce a version from 0.8.0 partition replica that each partition can be configured when the man several copies (such as creating a theme specified replication-factor, can also be configured in the default Broker level. replication.factor), typically set to 3.
Kafka can guarantee that in the event a single partition is ordered, zoning online (available) and offline (unavailable). Among the many partition copy of which is a copy of the Leader, the rest of the copy is a follower, all read and write operations are carried out through Leader, while follower will copy the data to the leader on a regular basis. When Leader hung up when one follower will again become the new Leader. By partitioning the copy, the data redundancy is introduced, but also provides the data reliability Kafka.
Kafka partition multi-core architecture is a copy of Kafka reliability assurance, the message is written to make multiple copies of Kafka in the event of a crash can still guarantee persistent messages.
Producer sending messages to the Broker
If you want to send a message to Kafka corresponding theme, complete by Producer. In order to allow the user to set the reliability data, Kafka message confirmation mechanism is provided inside the Producer, i.e. determines the message to send several copies of the corresponding partition is considered successful transmission of the message by the configuration. It can be specified when defining the parameters by acks Producer. This parameter supports the following three values:
- acks = 0: means that if producers can send messages across the network, then that message has been successfully written to Kafka. In this case the error may still occur, such as sending an object can be serialized or non-network card failure, but if it is a partition or the entire cluster offline for a long time is not available, it would not receive any error
- acks = 1: Leader means upon receipt if the message and write it to a file partition data (not necessarily synchronized to disk) will return an error response or acknowledgment. In this mode, if the normal Leader elections take place, producers will receive in the election of a LeaderNotAvailableException exception if the producer can properly handle the error, it will retry sending quiet interest, eventually the message will arrive safely at the new Leader There. However, there are still in this mode possible loss of data, such as message has been successfully written to the Leader, but before the message is copied to the copy follower Leader crashes
- acks = all: means Leader before returning an error response or acknowledgment, waits until all synchronized copies of all received information quiet. If the combination of parameters and min.insync.replicas, you can decide before returning to confirm how many copies there are at least able to receive information quiet, producers will have to retry until the message is successfully submitted. But this is the slowest approach, as producers continue to send other messages before all copies have to wait to receive the current message
Acks set different according to the actual application scenario, in order to ensure reliability of data.
Further, Producer transmission message may also choose to sync (default, sync configuration by producer.type =) or asynchronously (producer.type = async) mode. If set to asynchronous, although it will greatly improve messaging performance, but this increases the risk of losing data. If you need to ensure the reliability of the message must be producer.type set to sync.
Leader election
ISR (in-sync replicas) list, each partition leader maintains a list of ISR, ISR list which is a copy of Borker follower numbers, only to keep up with Leader of the follower a copy of which can be added to ISR, this is by replica.lag .time.max.ms parameter configuration. Only the ISR members have been selected as a possible leader.
So when Leader hung up, and in the case of unclean.leader.election.enable = false, Kafka will select the first follower from the ISR list as the new Leader, because this partition has been committed with the latest news. This can ensure the reliability of the data by the already committed message.
In summary, in order to ensure the reliability of data, it requires a minimum of several parameters:
- Level producer: acks = all (or request.required.acks = -1), simultaneous synchronization mode producer.type = sync
- topic level: setting replication.factor> = 3, and min.insync.replicas> = 2
- broker Grade: Incomplete Leader close election, that unclean.leader.election.enable = false;
Data consistency
Data consistency: Whether Leader Leader old or new elections, Consumer can read the same data.
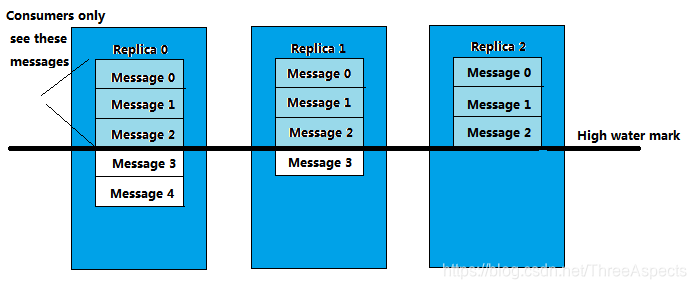
Suppose copy of the partition 3, where 0 is a copy of the Leader, and replica copies of a follower 2, and in which the list of ISR. Although the copy has been written 0 Message4, but only read to the Consumer Message2. Because all of the ISR Message2 are synchronized, only a High Water Mark above message was read Consumer support, depends on the minimum and the High Water Mark ISR list offset inside partition, corresponding to the FIG. 2 copies, this is very similar to barrel Theory.
The reason for this is not yet enough to copy a copy of the message is considered "unsafe", if the Leader crashes, another copy to become the new Leader, then these messages are likely to be lost. Allowing consumers to read these messages might undermine consistency. Imagine, a consumer reads from the current Leader (copy 0) and processed Message4, this time Leader hung up, a copy of the election for the new Leader 1, this time to go to another consumer reads the message from the new Leader, I found this news does not actually exist, which leads to data inconsistency.
Of course, the introduction of the High Water Mark mechanism will lead to copy messages between Broker slow for some reason, then the time the message reaches consumers will also become longer (because the message will first wait for the replication is complete). Delay time may be configured by parameters replica.lag.time.max.ms parameter, which specifies the maximum message copy may be allowed while copying of a delay time.
