Recently found a relatively busy practice, learn a python, used to process log files to get work in the test, the above procedure is hereby write about the things learned. ____Xuefeng Zhang
A. Dividing a regular expression json format data log in at the interface.
1.1 Simple usage of regular expressions re.findall
正则 re.findall 的简单用法(返回string中所有与pattern相匹配的全部字串,返回形式为数组)
语法:| 1 |
|
import re
Python 正则表达式 re findall 方法能够以列表的形式返回能匹配的子串
# print (help(re.findall))
# print (dir(re.findall))
findall查找全部r标识代表后面是正则的语句| 1 2 3 |
|
符号^表示匹配以https开头的的字符串返回,| 1 2 3 |
|
用$符号表示以html结尾的字符串返回,判断是否字符串结束的字符串| 1 2 3 |
|
# [...]匹配括号中的其中一个字符| 1 2 3 |
|
“d”是正则语法规则用来匹配0到9之间的数返回列表| 1 2 3 4 5 6 |
|
小d表示取数字0-9,大D表示不要数字,也就是出了数字以外的内容返回| 1 2 3 |
|
“w”在正则里面代表匹配从小写a到z,大写A到Z,数字0到9| 1 2 3 |
|
“W”在正则里面代表匹配除了字母与数字以外的特殊符号| 1 2 3 |
|
1.2 obtaining a large section between the two text strings:
Or by re string.find. The following codes used are re
import re
#文本所在TXT文件
file = '123.txt'
#关键字1,2(修改引号间的内容)
w1 = '123'
w2 = '456'
f = open(file,'r')
buff = f.read()
#清除换行符,请取消下一行注释
#buff = buff.replace('\n','')
pat = re.compile(w1+'(.*?)'+w2,re.S)
result = pat.findall(buff)
print(result)
python regular expression re.S role
In the regular expression in Python, there is an argument for the re.S. It represents. "" (Does not include outer double quotes, the same below) extended to the role of the entire string, including "\ n". Look at the following code:
import re
a = '''asdfhellopass:
123
worldaf
'''
b = re.findall('hello(.*?)world',a)
c = re.findall('hello(.*?)world',a,re.S)
print 'b is ' , b
print 'c is ' , c运行结果如下:
b is []
c is ['pass:\n\t123\n\t']Any character in the regular expression, "." In addition to the role of a match "\ n", that is, it is a match in a row. Here the "line" is "\ n" to distinguish. There are a string end of each row has a "\ n", but it is not visible.
If only one line string uses the following effects:
# -*- coding: cp936 -*-
import re
string = "xxxxxxxxxxxxxxxxxxxxxxxx entry '某某内容' for aaaaaaaaaaaaaaaaaa"
result = re.findall(".*entry(.*)for.*",string)
for x in result:
print x
输出:
# '某某内容'
If you do not use re.S parameters, only to be matched within each line, if there is no line, it replaced a row to start again, does not cross lines. The future use re.S parameter, the regular expression will be the string as a whole, the "\ n" as an ordinary character string added to this, in the whole match.
Second parse Json string using python - Get Json string keyword
Look at the code
import json
data = {
"statusCode": 200,
"data": {
"totoal": "5",
"height": "5.97",
"weight": "10.30",
"age": "11"
},
"msg": "成功"
}
#dumps:把字典转换为json字符串
s = json.dumps(data)
print s
#loads:把json转换为dict
s1 = json.loads(s)
print s1
#打印statusCode对应的值
print s1["statusCode"]
#打印data下age对应的值
print s1["data"]["age"] III. Use of Excel read and write python
We can use xlwt module to write data to an Excel spreadsheet, use xlrd module reads data from Excel. Better suggestions have pymysql databases and CSV format python csv format output , in front of the work needed.
3.1 python installation xlrd-1.10 and xlwt-1.3.0
First, download the installation package https://pan.baidu.com/s/1HvtpAgEfdtn1JAVOPNcJhw Password: is83 (source site)
cmd xlrd find the path, and then write setup.py install installation

xlwt installation above
这样就安装完成了。
然后验证,打开Python 命令行,不报错,表明你安装成功了,恭喜你可以继续学习了。
3.2 对Excel进行读写操作
3.2.1 对Excel的写操作:
# -*- coding: utf-8 -*-
#导入xlwt模块
import xlwt
# 创建一个Workbook对象,这就相当于创建了一个Excel文件
book = xlwt.Workbook(encoding='utf-8', style_compression=0)
'''
Workbook类初始化时有encoding和style_compression参数
encoding:设置字符编码,一般要这样设置:w = Workbook(encoding='utf-8'),就可以在excel中输出中文了。
默认是ascii。当然要记得在文件头部添加:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
style_compression:表示是否压缩,不常用。
'''
#创建一个sheet对象,一个sheet对象对应Excel文件中的一张表格。
# 在电脑桌面右键新建一个Excel文件,其中就包含sheet1,sheet2,sheet3三张表
sheet = book.add_sheet('test', cell_overwrite_ok=True)
# 其中的test是这张表的名字,cell_overwrite_ok,表示是否可以覆盖单元格,其实是Worksheet实例化的一个参数,默认值是False
# 向表test中添加数据
sheet.write(0, 0, 'EnglishName') # 其中的'0-行, 0-列'指定表中的单元,'EnglishName'是向该单元写入的内容
sheet.write(1, 0, 'Marcovaldo')
txt1 = '中文名字'
sheet.write(0, 1, txt1.decode('utf-8')) # 此处需要将中文字符串解码成unicode码,否则会报错
txt2 = '马可瓦多'
sheet.write(1, 1, txt2.decode('utf-8'))
# 最后,将以上操作保存到指定的Excel文件中
book.save(r'e:\test1.xls') # 在字符串前加r,声明为raw字符串,这样就不会处理其中的转义了。否则,可能会报错3.2.2 对Excel的写操作
表格如图
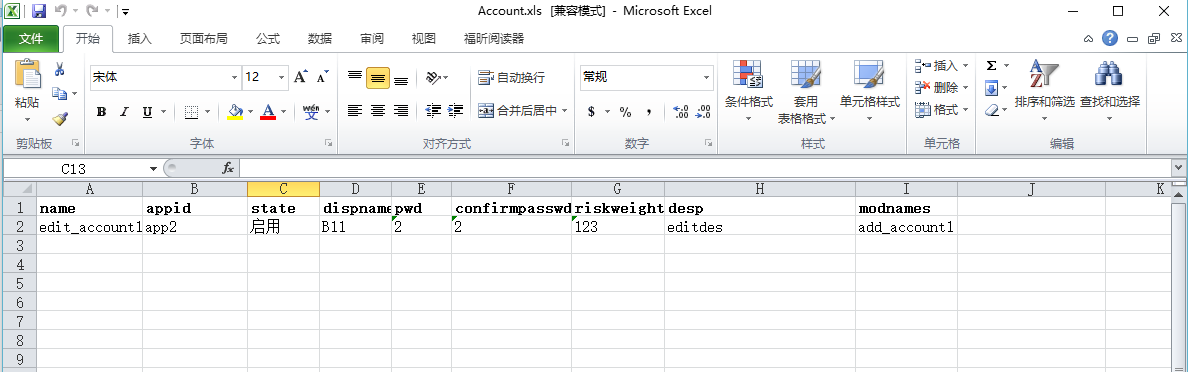
# -*- coding: utf-8 -*-
import xlrd
xlsfile = r"C:\Users\Administrator\Desktop\test\Account.xls"# 打开指定路径中的xls文件
book = xlrd.open_workbook(xlsfile)#得到Excel文件的book对象,实例化对象
sheet0 = book.sheet_by_index(0) # 通过sheet索引获得sheet对象
print "1、",sheet0
sheet_name = book.sheet_names()[0]# 获得指定索引的sheet表名字
print "2、",sheet_name
sheet1 = book.sheet_by_name(sheet_name)# 通过sheet名字来获取,当然如果知道sheet名字就可以直接指定
nrows = sheet0.nrows # 获取行总数
print "3、",nrows
#循环打印每一行的内容
for i in range(nrows):
print sheet1.row_values(i)
ncols = sheet0.ncols #获取列总数
print "4、",ncols
row_data = sheet0.row_values(0) # 获得第1行的数据列表
print row_data
col_data = sheet0.col_values(0) # 获得第1列的数据列表
print "5、",col_data
# 通过坐标读取表格中的数据
cell_value1 = sheet0.cell_value(0, 0)
print "6、",cell_value1
cell_value2 = sheet0.cell_value(0, 1)
print "7、",cell_value2
参考资料:
http://blog.csdn.net/majordong100/article/details/50708365
http://www.cnblogs.com/lhj588/archive/2012/01/06/2314181.html
http://www.cnblogs.com/snake-hand/p/3153158.html
至此,自动处理就完成了,下面讲一下报的bug
1.UnicodeEncodeError: 'ascii' codec can't encode character...
在python2.7下,因为想从数据库中读出来分类名进行写入到文件,提示
UnicodeEncodeError: 'ascii' codec can't encode character u'\uff08' in position 12: ordinal not in range(128)
不用fp.write,用print打印却正常,这到底是怎么回来呢?
#! /usr/bin/python
# -*- coding: utf-8 -*-
import sys
print sys.getdefaultencoding();运行上面的程序提示
ascii
原来如此,在程序的头部加上
import sys
reload(sys)
sys.setdefaultencoding('utf-8')再次运行,错误消失。
总结一下,python2.7是基于ascii去处理字符流,当字符流不属于ascii范围内,就会抛出异常(ordinal not in range(128)。
2.ValueError: Expecting , delimiter
检查json格式错误,少了个逗号。
