Project Analysis
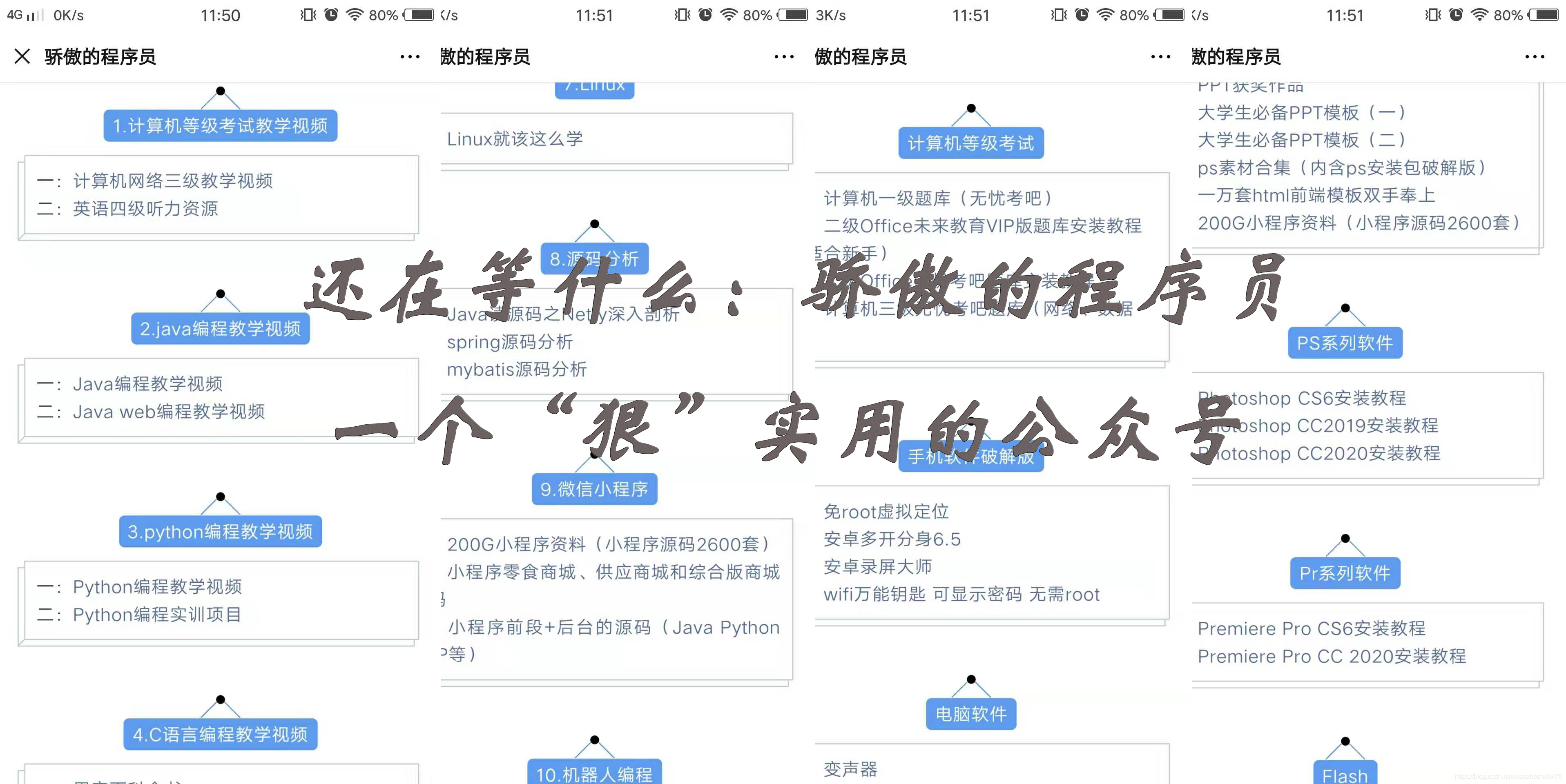
First, we have to first of all be ready to crawl websites embarrassments Wikipedia URL (http://www.qiushibaike.com/), we can look at the source code of the article, we find the law to crawl content, here is my extract the part of the code
<div class="content">
<span>
儿子三岁的时候,经常跟着奶奶,奶奶开了个养鸡场,养了三四千只鸡,孩子每天最高兴的就是跟奶奶进鸡房捡鸡蛋,拾进那个大木头箱子,拉出来,再装进蛋托里装箱。<br/><br/>有天奶奶正在那装蛋托呢,儿子在跟前玩,一个没立稳,一屁股坐在了装鸡蛋的大木箱子里,把满满的一箱子鸡蛋坐出了个大坑,吓的哇哇哭起来了,奶奶都没舍得训他。而是自己把剩下好的鸡蛋挨个都擦了装箱,把还能吃的坏一点的鸡蛋都留下来自个吃。<br/><br/>晚上吃饭的时候,他叔叔和爷爷看着饭桌上炒的一大盘鸡蛋,都说婆婆开眼了,舍得炒这么多鸡蛋,儿子在一边悠悠得说:“叔叔,
…
</span>
<span class="contentForAll">查看全文</span>
</div>
<a href="/article/122710686" target="_blank" class="contentHerf" onclick="_hmt.push(['_trackEvent','web-list-content','chick'])">
<div class="content">
<span>
单位安排我们一些管理人员先上班!<br/>这天领导突然检查工作,要求必须佩戴好口 罩去迎接!<br/>当时我在整理文件,着急忙慌的刚摘掉的口罩居然找不到了,情急之下,我抓起美女同事桌子上的一包口 罩就往外跑!<br/>在离领导们还有20米左右的时候,我赶紧拿出口罩准备戴上,拿出来才发现,是卫 生 巾!<br/>哎哟哟,众目奎奎一下,我这个脸呀!
</span>
</div>
Combined with the code above and below the front-end style, we can conclude that all of the articles is between <div class = "content"> </ div>, some students might ask, why is not <span> tag inside it, because some content inside a span of interference, such as above <span class = "contentForAll"> View full text </ span>, etc.
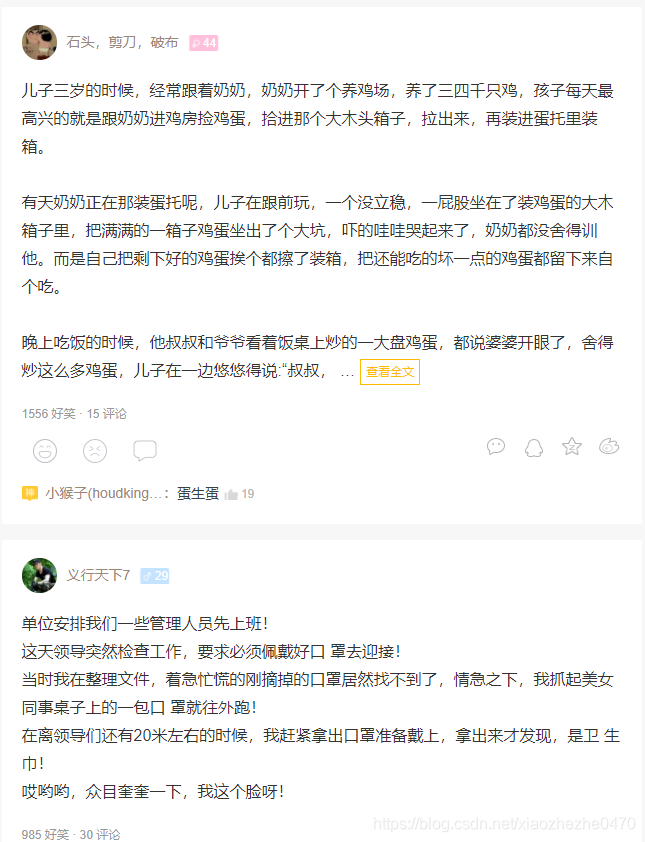
Second, open look at the interface, we can see that this is a lot of pages of , if we want to crawl all of the content, we also need to turn the page, which we need to analyze how to turn pages.
The second page URL: https: //www.qiushibaike.com/hot/page/2/
third page URL: https: //www.qiushibaike.com/hot/page/3/
fourth page URL: https: / /www.qiushibaike.com/hot/page/4/
so that everyone will find the right law
Third, if a little jump at me and said, very clearly, it would be to look at the code, the code can see I do not understand Previous article Urlib module introduction
#创建一个用户代理池数组
uapools=[
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",#360
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36",#谷歌
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0",
]
#定义一个方法UA()
def UA():
#创建一个urllib.request.build_opener()对象
opener = urllib.request.build_opener()
#每次从uapools中随机选取一个User-Agent
thisua = random.choice(uapools)
#以JSON格式(键值对)保存一个User-Agent
ua = ("User-Agent",thisua)
#将User-Agent赋值给opener.addheaders
opener.addheaders=[ua]
#将urllib.request的install_opener改成咱们的
urllib.request.install_opener(opener)
print("当前使用User-Agent:"+str(thisua))
sum = 0
for i in range(0,13):
#从第一页便利到第十三页
url = "https://www.qiushibaike.com/hot/page/"+ str(i+1) +"/"
UA()
#这回就可以快乐的爬取网站内容啦
data = urllib.request.urlopen(url).read().decode("utf-8","ignore")
string = '<div class="content">.*?<span>(.*?)</span>.*?</div>'
res = re.compile(string,re.S).findall(data)
for j in range(0,len(res)):
print(res[j])
print("-------------本页第" + str(j) + "条------------")
sum = sum + 1
print("共有"+ str(sum) +"条文章")
Look at the operating results of it: it seems embarrassments Encyclopedia As of 2020.2.7 Total 261 articles

where did not understand, or I have the wrong place, welcome in the comments section points out, thank you!