Article Directory
Integers
When a collection contains only integer, and much of this element of the set, Redis will use the set of integers intset. First, look at the data structure of intset:
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
In fact, the data structure intset is better understood. A data storage element, length stored number of elements, i.e. the size of the contents, encoding for encoding the data to be stored.
We can know by the code, encoding encoding type includes:
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
In fact, we can see it. Redis encoding type, refers to the size of the data. As a memory database, this design is to save memory.
Since there are three small to large data structures used when inserting data as small as possible to save memory data structure, if the inserted data is larger than the original data structure, it will trigger expansion.
Expansion There are three steps:
- Depending on the type of new elements, modify the entire array of data types, and re-allocation of space
- The original data, installed for the new data type, to be put back in position, and the storage order of
- Then insert a new element
Integers are not supported downgrade, once the upgrade can not be downgraded.
Jump table
Jump table is? One kind linked list, is a use of space for time data structure. The average jump table support O (logN), look for the complexity of the worst O (N).
Jump table is made? ZskiplistNode a zskiplist and more composed. We take a look at their structure?:
/* ZSETs use a specialized version of Skiplists */
/*
* 跳跃表节点
*/
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
/*
* 跳跃表
*/
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;
This code so we can draw according to the following structure:
[Image dump the chain fails, the source station may have security chain mechanism, it is recommended to save the picture down uploaded directly (img-8veqZuZy-1573628505436) (media / 15663755251342 / 15663757297856.jpg)]
In fact, jump table is a data structure using the space for time, use level as an index of the list.
Redis before someone asked the author of Why jump table, instead of tree to build the index? Author's answer is:
- Province of memory.
- Serve ZRANGE or ZREVRANGE is a list of typical scenarios. Time complexity and performance? Almost balanced tree.
- The most important point is? Leaps table is very simple to achieve O (logN) level.
Packing List
Compression list Redis its author, in order to save memory design as much as possible out of the doubly linked list.
For a list of data structures annotated given compression code as follows:
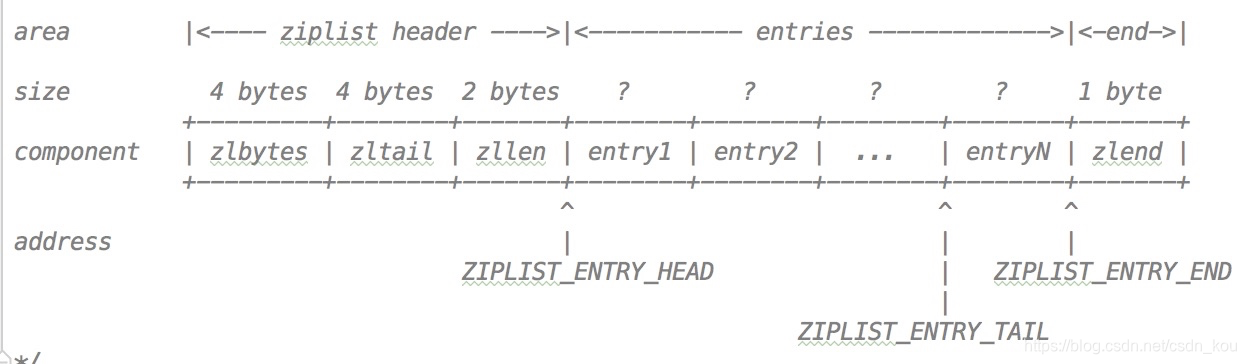
zlbytes 表示的是整个压缩列表使用的内存字节数
zltail 指定了压缩列表的尾节点的偏移量
zllen 是压缩列表 entry 的数量
entry 就是 ziplist 的节点
zlend 标记压缩列表的末端
The list also single pointer:
ZIPLIST_ENTRY_HEAD 列表开始节点的头偏移量
ZIPLIST_ENTRY_TAIL 列表结束节点的头偏移量
ZIPLIST_ENTRY_END 列表的尾节点结束的偏移量
? Look at the entry of a structure:
/*
* 保存 ziplist 节点信息的结构
*/
typedef struct zlentry {
// prevrawlen :前置节点的长度
// prevrawlensize :编码 prevrawlen 所需的字节大小
unsigned int prevrawlensize, prevrawlen;
// len :当前节点值的长度
// lensize :编码 len 所需的字节大小
unsigned int lensize, len;
// 当前节点 header 的大小
// 等于 prevrawlensize + lensize
unsigned int headersize;
// 当前节点值所使用的编码类型
unsigned char encoding;
// 指向当前节点的指针
unsigned char *p;
} zlentry;
In order to explain these parameters.
length prevrawlen front node, where more than one size, the size of the record is actually a prevrawlen. To save memory Redis not directly use the default length of the int, but escalating.
Similarly record len is the length of the current node,? Lensize? Len is the length of the record. ?
HeaderSize? Is the previously mentioned sum of two size.
encoding is? data type for this node. Here note encoding types include only integers and strings.
pointer p nodes, without too much explanation.
It should be noted that, since each node keeps the length of the front of a node, if the node is updated or deleted,? The data after this node also need to be modified, there is a worst-case scenario is that if each node in need zero point boundary expansion, it will cause after this node? node must modify the size of this parameter, triggering a chain reaction. This time is compressed list worst time complexity O (n ^ 2). However, all nodes are at a critical value, the probability of such can be said to be relatively small.
to sum up
The basic data structure so far on the introduction Redis finished. We can see Redis memory usage is really "preoccupied" for the memory is? The use of special savings. Meanwhile Redis as a single-threaded application, do not consider the problem of concurrency, the exposed a number of similar size or length of the parameters, the much reduced O (n) operations is O (1).
