1 Introduction
Preface analyzed ES source code written procedures, as detailed in [Source] Elasticsearch write source code analysis .
Elasticsearch (ES) query interface with distributed data retrieval, aggregation analysis capabilities, data retrieval capabilities to support full-text search, log analysis and other scenes, such as the code on Github search platform, based on the types of ES log analysis services; Aggregated analysis capability to support index analysis, APM and other scenes, such as monitoring the scene, the application of Nikkatsu / retention analysis.
Based on the 6.7.1 version, distributed execution framework analyzes the ES and the body of the query process, explore how ES distributed queries, data retrieval, aggregation capability analysis.
2 basic flow of inquiries
Pictures from the official website, the source code from version 6.7.1:
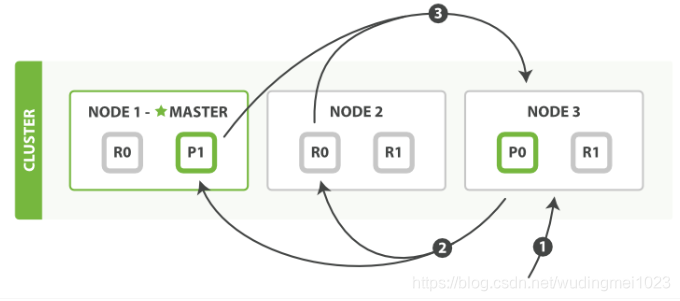
- The client may send a query to any node, the receiving node will query the coordinator node as the query;
- The coordinating node to resolve the query, the query corresponding data fragmentation distribution sub-tasks;
- Each slice of the local query results are returned to the coordinator node, into convergence by coordinating node back to the client.
As shown: the client sends a request to the node Node3, after parsing the query node Node3, distribute requests to Node1 and Node2 numbers 0 and 1, where the fragment, both repeat fragments around the query returns data to Node3, Node3 eventually be brought together, and then returned to the client.
From the practical implementation point of view, the coordinator node processing logic complex process than the above, the coordinator node processing logic corresponding to different types of queries have some differences.
The following first to introduce common queries under category 2, there are three types of queries in the previous version: DFS_QUERY_THEN_FETCH, QUERY_AND_FETCH and QUERY_THEN_FETCH, after the 5.3 version, QUERY_AND_FETCH has been removed.
2.1 DFS_QUERY_THEN_FETCH
Inside there is a search operator is a logical division when TF (Term Frequency) and DF (Document Frequency) is calculated base points, but Elasticsearch query, the query is independent of each Shard, each of the TF and DF Shard is independent, even though at the time of writing distributed by _routing guarantee Doc, but can not guarantee the TF and DF uniform, then it will lead to local TF and DF are not allowed to appear, this time based on TF, DF operator points are not allowed.
To solve this problem, Elasticsearch introduced DFS queries, such as DFS_query_then_fetch, will first collect all the TF and DF values Shard, and then these values into the request, do query_then_fetch again, this time to count points TF and DF is accurate of.
2.2 QUERY_THEN_FETCH
ES default query, the query process, query, and fetch divided into two stages:
Query Phase: retrieving data fragmentation and aggregation size, attention returns only documents scheduling round id set, does not return the actual data.
The coordinating node: After the resolution query, send a query command to the target data fragmentation.
Node data: within each tile according to filtering, sorting, and other conditions for fragmentation and particle size of the document retrieval id data aggregation result is returned.
Fetch Phase: generate a final retrieval results of the polymerization.
Coordinating node: Query Phase merge results to obtain a final set of id and polymerization results, and the target data piece transmission data fetch command file.
Data node: on-demand content to crawl data actually needed.
3 source query process analysis
Here in the default QUERY_THEN_FETCH query as an example:
3.1 queries entrance
This is a logic and processing all the requests are similar ES, reference may be requested bulk process. Request to Rest Case Study:

Rest distribution is done by RestController module. When ES node starts, loads all built Rest Action requests, and the corresponding path request and Http Rest Action as <Path, RestXXXAction> tuple registered in RestController. Rest for any such request, RestController module according Http only path, can easily find the corresponding request for distribution of the Action Rest. Sample RestSearchAction registered as follows:
public RestSearchAction(Settings settings, RestController controller) {
super(settings);
controller.registerHandler(GET, "/_search", this);
controller.registerHandler(POST, "/_search", this);
controller.registerHandler(GET, "/{index}/_search", this);
controller.registerHandler(POST, "/{index}/_search", this);
controller.registerHandler(GET, "/{index}/{type}/_search", this);
controller.registerHandler(POST, "/{index}/{type}/_search", this);
}
Rest for parsing the layer Http request parameters, RestRequest SearchRequest parsed and converted, and then do the processing on SearchRequest, this logic in prepareRequest method, part of the code as follows:
public RestChannelConsumer prepareRequest(final RestRequest request, final NodeClient client) throws IOException {
//根据RestRequest构建SearchRequest
SearchRequest searchRequest = new SearchRequest();
IntConsumer setSize = size -> searchRequest.source().size(size);
request.withContentOrSourceParamParserOrNull(parser ->
parseSearchRequest(searchRequest, request, parser, setSize));
//处理SearchRequest
return channel -> client.search(searchRequest, new RestStatusToXContentListener<>(channel));
}
NodeClient SearchRequest when processing the request, the request is converted to the corresponding action in the action Transport layer, then the action Transport layer SearchRequest treated, the code conversion action is as follows:
public < Request extends ActionRequest,
Response extends ActionResponse
> Task executeLocally(GenericAction<Request, Response> action, Request request, TaskListener<Response> listener) {
return transportAction(action).execute(request, listener);
}
private < Request extends ActionRequest,
Response extends ActionResponse
> TransportAction<Request, Response> transportAction(GenericAction<Request, Response> action) {
.....
//actions是个action到transportAction的Map,这个映射关系是在节点启动时初始化的
TransportAction<Request, Response> transportAction = actions.get(action);
......
return transportAction;
}
Then enter TransportAction, TransportAction # execute (Request request, ActionListener listener) -> TransportAction # execute (Task task, Request request, ActionListener listener) -> TransportAction # proceed (Task task, String actionName, Request request, ActionListener listener). TransportAction calls a request filter chain to process the request, if the associated plug defines the filtering action of the process, the process first performs the logic card, then processing logic enters TransportAction, the processing logic of the filter chain as follows:
public void proceed(Task task, String actionName, Request request, ActionListener<Response> listener) {
int i = index.getAndIncrement();
try {
if (i < this.action.filters.length) {
//应用插件的逻辑
this.action.filters[i].apply(task, actionName, request, listener, this);
} else if (i == this.action.filters.length) {
//执行TransportAction的逻辑
this.action.doExecute(task, request, listener);
} else {
......
}
} catch(Exception e) {
.....
}
}
Search requests for specific target of TransportAction here corresponds TransportSearchAction example of this, Rest Transport layer into a layer flow is completed, the next section will describe in detail the processing logic TransportSearchAction.
3.1 distribute queries
Code entry: TransportSearchAction # doExecute.
First, resolve to obtain specific query involves a list of indexes, including remote clusters and local clusters (clusters for remote access across the cluster):
final ClusterState clusterState = clusterService.state();
//获取远程集群indices列表
final Map<String, OriginalIndices> remoteClusterIndices = remoteClusterService.groupIndices(searchRequest.indicesOptions(),
searchRequest.indices(), idx -> indexNameExpressionResolver.hasIndexOrAlias(idx, clusterState));
//获取本地集群indices列表
OriginalIndices localIndices = remoteClusterIndices.remove(RemoteClusterAware.LOCAL_CLUSTER_GROUP_KEY);
if (remoteClusterIndices.isEmpty()) {
executeSearch((SearchTask)task, timeProvider, searchRequest, localIndices, Collections.emptyList(),
(clusterName, nodeId) -> null, clusterState, Collections.emptyMap(), listener,
clusterState.getNodes().getDataNodes().size(), SearchResponse.Clusters.EMPTY);
} else {
//远程集群的处理逻辑
.....
}
Then enter executeSearch methods, constructors purpose shard list, we can see:
- Under red state can query;
- The default target need to check all the parts of the index;
- Defaults QUERY_THEN_FETCH query;
- The maximum number of concurrent queries fragment 256;
- The default is not open request cache.
private void executeSearch(....) {
// red状态也可以查询
clusterState.blocks().globalBlockedRaiseException(ClusterBlockLevel.READ);
......
// 结合routing信息、preference信息,构造目的shard列表
GroupShardsIterator<ShardIterator> localShardsIterator = clusterService.operationRouting().searchShards(clusterState,
concreteIndices, routingMap, searchRequest.preference(), searchService.getResponseCollectorService(), nodeSearchCounts);
GroupShardsIterator<SearchShardIterator> shardIterators = mergeShardsIterators(localShardsIterator, localIndices,
searchRequest.getLocalClusterAlias(), remoteShardIterators);
.....
if (shardIterators.size() == 1) {
// 只有一个分片的时候,默认就是QUERY_THEN_FETCH,不存在评分不一致的问题
searchRequest.searchType(QUERY_THEN_FETCH);
}
if (searchRequest.allowPartialSearchResults() == null) {
// 用户未定义首选项,采用默认方式
searchRequest.allowPartialSearchResults(searchService.defaultAllowPartialSearchResults());
}
if (searchRequest.isSuggestOnly()) {
// 默认是没有开启请求缓存的
searchRequest.requestCache(false);
switch (searchRequest.searchType()) {
case DFS_QUERY_THEN_FETCH:
// 默认情况下DFS_QUERY_THEN_FETCH会转化成QUERY_THEN_FETCH
searchRequest.searchType(QUERY_THEN_FETCH);
break;
}
}
.....
// 最大并发分片数,最大是256:Math.min(256, Math.max(nodeCount, 1)* IndexMetaData.INDEX_NUMBER_OF_SHARDS_SETTING.getDefault(Settings.EMPTY))
setMaxConcurrentShardRequests(searchRequest, nodeCount);
boolean preFilterSearchShards = shouldPreFilterSearchShards(searchRequest, shardIterators);
// 生成查询请求的调度类searchAsyncAction并启动调度执行
searchAsyncAction(task, searchRequest, shardIterators, timeProvider, connectionLookup, clusterState.version(),
Collections.unmodifiableMap(aliasFilter), concreteIndexBoosts, routingMap, listener, preFilterSearchShards, clusters).start();
}
Then enters the run-implemented method of class InitialSearchPhase SearchPhase: Based on the shard is traversed sends a query to the node where the shard, if there are N shard the same node, the list is transmitted N times its request, the request will not merge into one.
public final void run() throws IOException {
.....
if (shardsIts.size() > 0) {
// 最大分片请求数可以通过max_concurrent_shard_requests参数配置,6.5之后版本新增参数
int maxConcurrentShardRequests = Math.min(this.maxConcurrentShardRequests, shardsIts.size());
....
for (int index = 0; index < maxConcurrentShardRequests; index++) {
final SearchShardIterator shardRoutings = shardsIts.get(index);
// 执行shard级请求
performPhaseOnShard(index, shardRoutings, shardRoutings.nextOrNull());
}
}
}
shardsIts all fragments related to this query, shardRoutings.nextOrNull () from a master slice select one or all copies.
Continued Next: query source code analysis (two).
