1 Overview
The above has analyzedthe basic concepts and basic operations of elasticsearch, so that everyone can become familiar with the basic use of es. This article will provide a more in-depth analysis of some advanced operations of elasticsearch based on the above to help you understand and use elasticsearch more deeply.
2.elasticsearch in practice
This article will use the most common hotel accommodation scenario as a demonstration. Many e-commerce platforms will have hotel booking scenarios. Users can search for hotel information that meets the requirements based on location, price, rating and other conditions, search for qualified hotels, and then proceed A series of operations such as placing orders and making payments. First, you need to understand a concept in elasticsearch: aggregations.
Aggregation can realize statistics, analysis, and calculation of document data. There are three common types of aggregation:
(1) Bucket aggregation: used to group documents according to Document field value grouping (TermAggregation), grouping by date ladder (Date Histogram);
(2)Metric aggregation: Used to calculate some values, such as: maximum value, minimum value, average value, etc.; Avg (finding the average value), Max (finding the maximum value), Min (finding the minimum value), Stats (finding max and min at the same time) , avg, sum, etc.);
(3)Pipeline (pipline) aggregation: based on the results of other aggregations polymerization.
All functions of aggregation can be viewed inOfficial Documents and can be consulted during use.
2.1 DSL implements aggregation
2.1.1 DSL implements Bucket aggregation
For example: Which cities do the hotels in the statistical data belong to? At this time, the aggregation can be done based on the city where the hotel is located, as shown below:
#聚合
GET /hotel/_search
{
"size": 0, //设置size为0,结果中不包含文档,只包含聚合结果
"aggs": {
//定义聚合
"cityAgg": {
//定义聚合名称
"terms": {
//聚合的类型,按照分布城市进行聚合,所以选择term
"field": "city", //参与聚合的字段
"size": 10, //希望获取的聚合结果数量
"order": {
"_count": "asc" //排序方式,默认倒序
}
}
}
}
}
By default, Bucket aggregation aggregates all documents in the index database. We can limit the scope of documents to be aggregated by adding query conditions, as shown below:
#聚合
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 1000 //酒店价格大于1000
}
}
},
"size": 0,
"aggs": {
"cityAgg": {
"terms": {
"field": "city",
"size": 10
}
}
}
}
2.1.2 DSL implements Metrics aggregation
Example: Get the maximum value (max), minimum value (min), average value (avg), etc. of user ratings for each brand.
#聚合
GET /hotel/_search
{
"size": 0,
"aggs": {
"cityAgg": {
"terms": {
"field": "city",
"size": 10,
"order": {
"scoreAgg.avg": "desc" //根据评分score的平均值进行降序排序
}
},
"aggs": {
"scoreAgg": {
//对按city聚合后的子聚合,也就是分组后对每组分别计算
"stats": {
//聚合类型,这里stats可以计算min、max、avg等
"field": "score" //聚合字段,这里是score
}
}
}
}
}
}
2.2 Using RestHighLevelClient request
2.2.1 RestHighLevelClient implements aggregation
For the case in 2.1.1, use JAVA to implement:
public List<HotelBo> countListByCity() {
SearchRequest request = new SearchRequest(Constants.HOTEL_INDEX);
request.source().size(0);
//组装DSL聚合语句,按照city进行聚合查询
request.source().aggregation(AggregationBuilders.terms("cityAgg").field("city").size(20));
List<HotelBo> hotelBos = new ArrayList<HotelBo>();
try {
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
log.info("请求返回结果:{}", response);
Aggregations aggregations = response.getAggregations();
//解析结果,获取Bucket中的数据
Terms terms = aggregations.get("cityAgg");
List<? extends Terms.Bucket> buckets = terms.getBuckets();
for (Terms.Bucket bucket : buckets) {
HotelBo hotelBo = new HotelBo();
hotelBo.setCity(bucket.getKey().toString());
hotelBo.setTotal((int) bucket.getDocCount());
hotelBos.add(hotelBo);
}
log.info("hotelbos:{}", hotelBos);
} catch (IOException e) {
e.printStackTrace();
}
return hotelBos;
}
The running results are shown in the figure below:

2.2.2 RestHighLevelClient implements multi-condition query
//根据条件查询list
public Page queryListByParams(QueryParams queryParams) {
SearchRequest searchRequest = new SearchRequest(Constants.HOTEL_INDEX);
Page page = new Page();
page.setPageNo(queryParams.getPageNo());
page.setPageSize(queryParams.getPageSize());
//
buildParams(queryParams, searchRequest);
Integer start = 0;
if (queryParams.getPageNo() != null && queryParams.getPageSize() != null) {
start = (queryParams.getPageNo() - 1) * queryParams.getPageSize();
}
page.setStart(start);
searchRequest.source().from(start);
if (queryParams.getPageSize() != null) {
searchRequest.source().size(queryParams.getPageSize());
} else {
searchRequest.source().size(10);
}
SearchHits hits = null;
TotalHits totalHits = null;
try {
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("result:{}", response);
hits = response.getHits();
totalHits = hits.getTotalHits();
} catch (IOException e) {
e.printStackTrace();
}
page.setTotal(totalHits.value);
log.info("总数为total:{}", totalHits);
List<Hotel> lists = new ArrayList<Hotel>();
SearchHit[] hitsList = hits.getHits();
for (SearchHit documentFields : hitsList) {
String sourceAsString = documentFields.getSourceAsString();
log.info("查询结果:{}", sourceAsString);
if (StringUtils.isNotBlank(sourceAsString)) {
Hotel hotel = JSON.parseObject(sourceAsString, Hotel.class);
Object[] sortValues = documentFields.getSortValues();
if (sortValues.length != 0) {
hotel.setDistance(sortValues[0].toString());
}
lists.add(hotel);
}
}
page.setData(lists);
return page;
}
The query parameters are as follows:
@Data
public class QueryParams {
private Integer pageSize;
private Integer pageNo;
//关键字
private String keyWord;
//所在城市
private String city;
//酒店名称
private String hotelName;
//酒店最低价
private Double minPrice;
//酒店最高价
private Double maxPrice;
//排序方式,asc:升序,desc:降序
private String sortBy;
//星级
private String starName;
//位置,附近的人
private String location;
}
The test query results based on name and star rating are as follows:
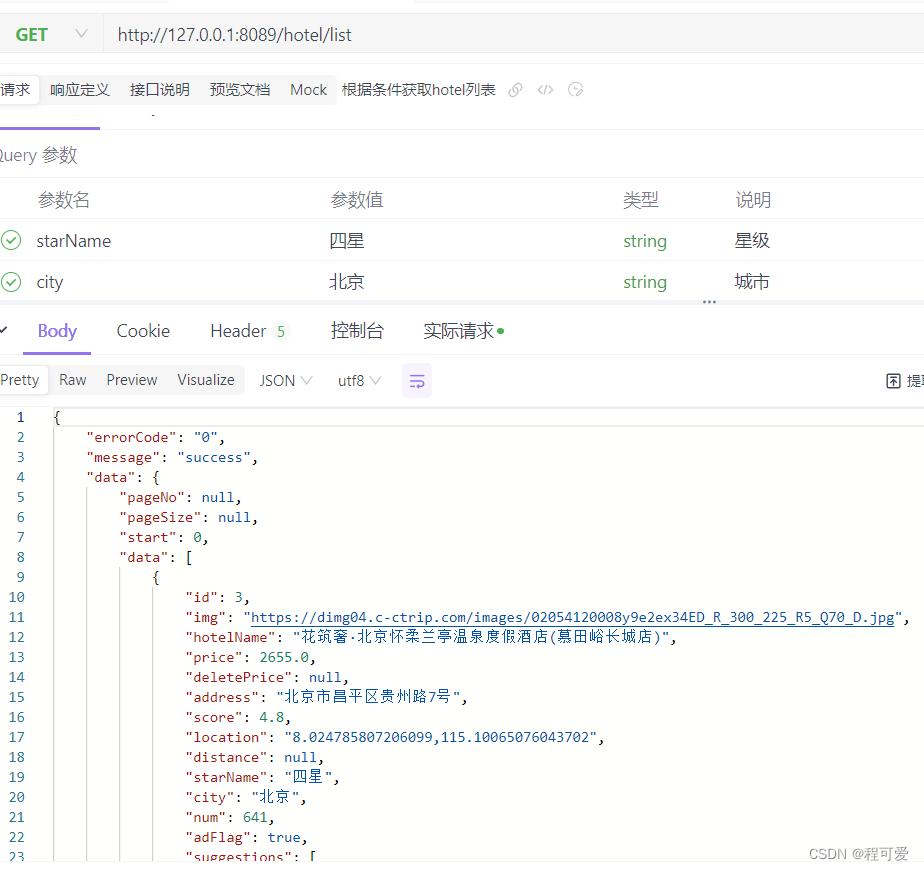
Please refer to the appendix for specific code and test data.
2.2.3 elasticsearch word segmenter
The word segmenter in elasticsearch consists of three parts: character filters, tokenizer, and tokenizer filter. The main functions of each part are as follows:
- character filters: Preprocess text (delete characters, replace characters);
- tokenizer: Cut the text into terms according to certain rules, and keywords are not divided into words;
- tokenizer filter: further process the entries output by the tokenizer, such as case conversion, synonym processing, and pinyin processing.
2.2.3 es implements pinyin automatic completion search
To achieve completion based on letters, the document must be segmented according to Pinyin. Pinyin word segmentation plug-in can be obtained from github. The installation method is the same as the IK word segmenter, which is divided into three steps:
(1) Download the corresponding version of the Pinyin word segmentation package and upload it to the plugin directory of elasticsearch;
(2) Decompress the installation package;
( 3) Restart elasticsearch.
After successful installation, test through Restful API. The request method is as follows:
POST /_analyze
{
"text": ["中国万岁"],
"analyzer": "pinyin"
}
If the following results appear, the Pinyin word segmenter is successfully installed:
{
"tokens" : [
{
"token" : "zhong",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 0
},
{
"token" : "zhgws",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 0
},
{
"token" : "hua",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 1
},
{
"token" : "guo",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 2
},
{
"token" : "wan",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 3
},
{
"token" : "sui",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 4
}
]
}
The request to customize the Pinyin tokenizer through the Restful API is as follows:
#自定义分词器
PUT /pinyin_test
{
"settings": {
"analysis": {
"analyzer": {
//拼音分词器名称
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
//拼音分词器的一些配置
"filter": {
"py": {
"type": "pinyin",
"keep_full_pin": false,
"keep_joined_full_pinyin": false,
"keep_original": true,
"limit_first_letter": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
//mapping指定哪个字段需要使用拼音分词器
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
//搜索时采用ik_smart分词器
"search_analyzer": "ik_smart"
}
}
}
}
After the creation is successful, use the following Restful API request to test:
POST /pinyin_test/_analyze
{
"text": ["中国万岁"],
"analyzer": "my_analyzer"
}
If the following results appear, it indicates that the tokenizer is successfully created:
{
"tokens" : [
{
"token" : "zhong",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "guo",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中国",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "zg",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "wan",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "sui",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "万岁",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "ws",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "wan",
"start_offset" : 2,
"end_offset" : 3,
"type" : "TYPE_CNUM",
"position" : 4
},
{
"token" : "万",
"start_offset" : 2,
"end_offset" : 3,
"type" : "TYPE_CNUM",
"position" : 4
},
{
"token" : "w",
"start_offset" : 2,
"end_offset" : 3,
"type" : "TYPE_CNUM",
"position" : 4
},
{
"token" : "sui",
"start_offset" : 3,
"end_offset" : 4,
"type" : "COUNT",
"position" : 5
},
{
"token" : "岁",
"start_offset" : 3,
"end_offset" : 4,
"type" : "COUNT",
"position" : 5
},
{
"token" : "s",
"start_offset" : 3,
"end_offset" : 4,
"type" : "COUNT",
"position" : 5
}
]
}
Elasticsearch provides the Completion Suggester query to implement the completion function. This query will match the terms starting with the user input content and return it. In order to improve the efficiency of completion queries, there are some constraints on the types of fields in the document: the fields participating in the completion query must be of completion type.
PUT /pinyin_test
{
"mappings": {
"properties": {
"name":{
"type": "completion"
}
}
}
}
For example, search based on keywords:
GET /hotel/_search
{
"suggest": {
"titleSuggest": {
"text": "h",
"completion": {
"field": "suggestions", //suggestions是根据city与hotelName组合的快速搜索数组
"skip_duplicates":true,
"size":10
}
}
}
}
The code for data query using RestHighLevelClient is as follows:
public List<String> searchByPinyin(String string) {
SearchRequest searchRequest = new SearchRequest(Constants.HOTEL_INDEX);
//进行根据输入拼音进行关键字匹配
searchRequest.source().suggest(new SuggestBuilder().addSuggestion("suggestions", SuggestBuilders.completionSuggestion("suggestions").prefix(string).skipDuplicates(true).size(10)));
List<String> lists = new ArrayList<String>();
try {
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Suggest suggest = response.getSuggest();
Suggest.Suggestion<? extends Suggest.Suggestion.Entry<? extends Suggest.Suggestion.Entry.Option>> titleSuggest = suggest.getSuggestion("suggestions");
String name = titleSuggest.getName();
log.info("name:{}",name);
for (Suggest.Suggestion.Entry<? extends Suggest.Suggestion.Entry.Option> options : titleSuggest.getEntries()) {
log.info("options:{}",options);
List<? extends Suggest.Suggestion.Entry.Option> options1 = options.getOptions();
for (Suggest.Suggestion.Entry.Option option : options1) {
log.info("option1:{}",option);
lists.add(option.getText().toString());
}
}
} catch (IOException e) {
e.printStackTrace();
}
return lists;
}
2.3 ElasticSearch data synchronization
In a production environment, elasticSearch is mainly used to provide data query functions, and data storage work is mainly saved by a relational database. Therefore, how to keep the relational database and elasticsearch data consistent becomes the key. This article takes mysql as an example to analyze three ways of data synchronization between mysql and elasticsearch:
2.3.1 Synchronous call

As shown in the figure above, the synchronous call is that when adding or modifying data, the data will be stored in mysql through the management service. After the database is successfully stored, the search service (operation es) will be called to update the data to elasticsearch. The entire process will be called synchronously. The advantage of this method is that the data is updated in real time and can be synchronized quickly. The disadvantage is that when data is updated frequently, the data storage time will be affected by elasticsearch performance. Once elasticsearch has a problem, subsequent data may not be stored in the database.
2.3.2 Use message intermediate for synchronization
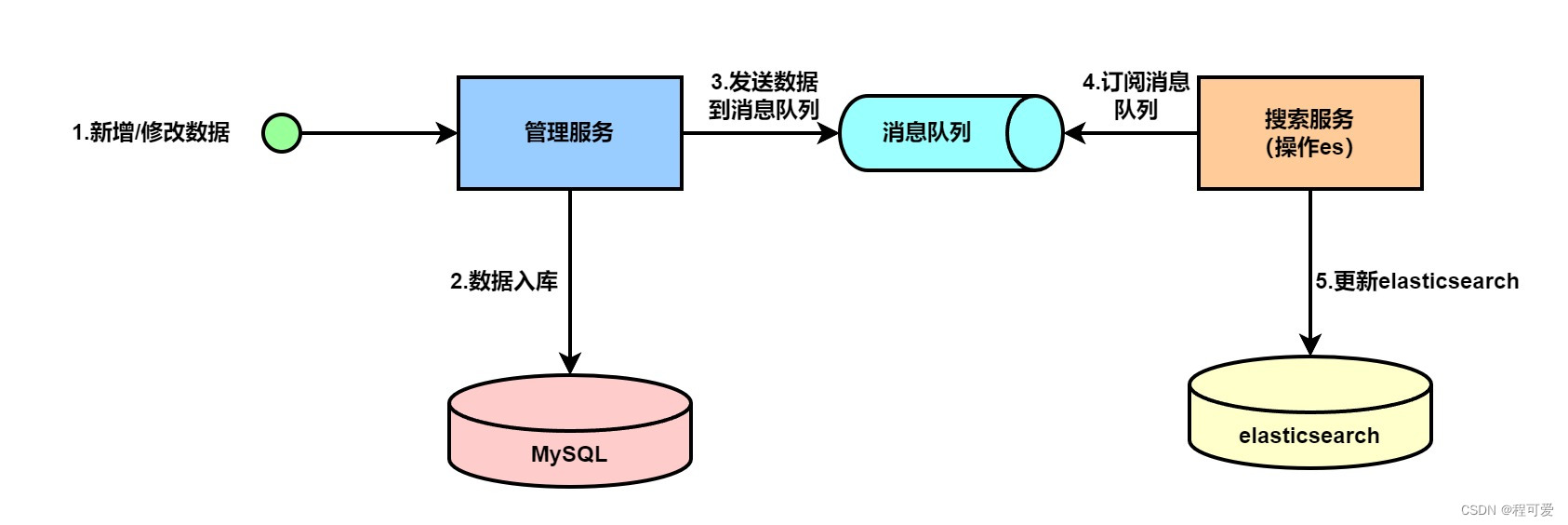
The difference between using message middleware for synchronization and the first solution is that a message queue is added between the management service and the search service. After the management service stores the data into mysql, it then sends the data to the message queue. The search service subscribes Message queue, obtain the change data, and then update it to elasticsearch. The advantage of this method is to decouple data updates to mysql and elasticsearch so that the two do not affect each other. The disadvantage is that the real-time performance of data synchronization is lower than that of solution one.
2.3.3 Use canal for data synchronization

To use canal for data synchronization, mysql needs to enable the binlog log. When data is added, deleted, or modified, canal will obtain data change information based on the binlog log and push the change information to the search service. The search service determines the data operation type and synchronizes it to elasticsearch. The advantage of this method is that data synchronization efficiency will be higher than using middleware, but the disadvantage is that it will consume MySQL performance.
2.4 ElasticSearch cluster
Stand-alone ElasticSearch will face two problems:
(1) Mass data storage problem: To solve this problem, the index library can be logically divided into N shards and stored in multiple nodes;
(2) Single point of failure problem: Back up sharded data on different nodes (replica);
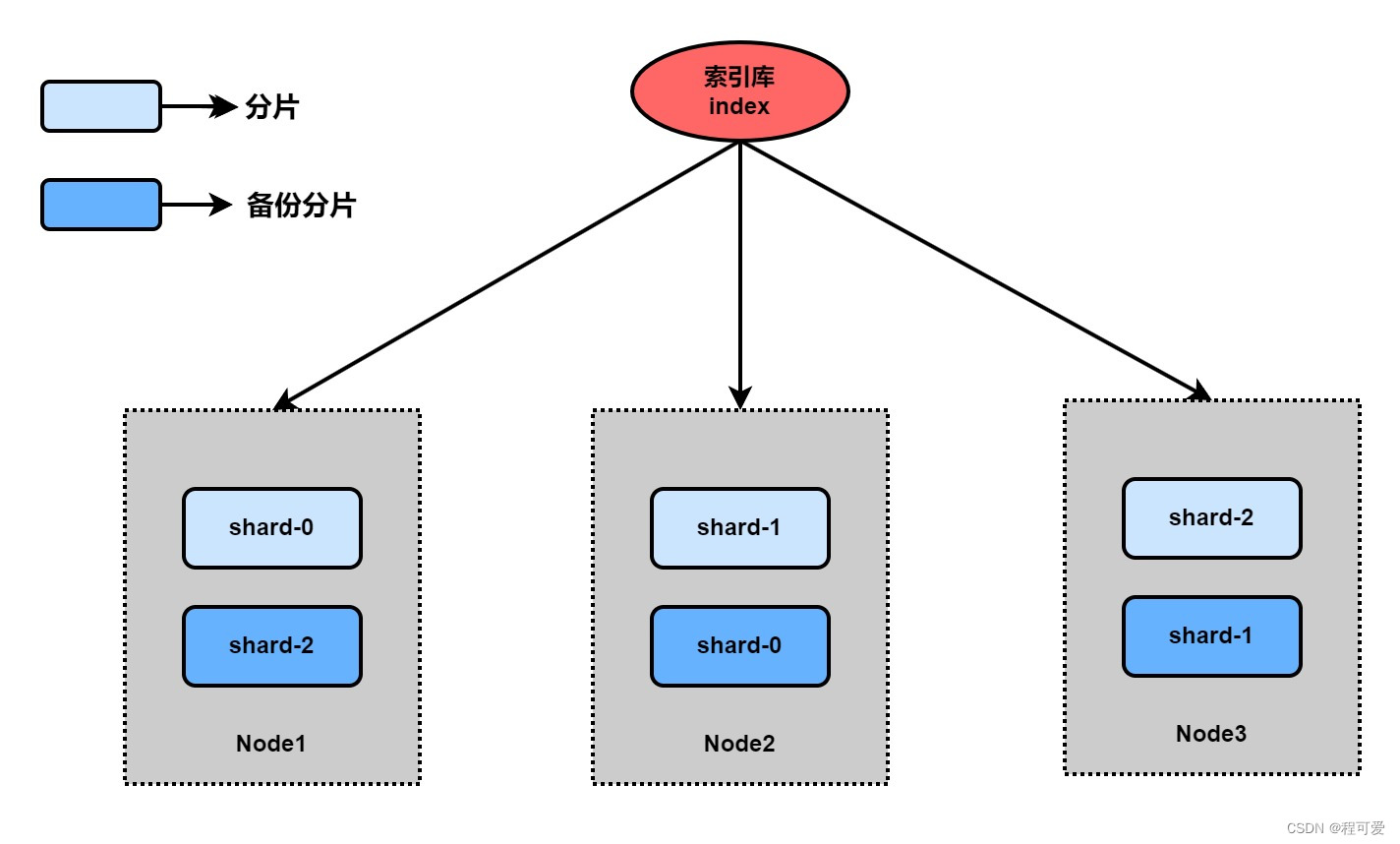
Taking the above three machines as an example, shard-2 is backed up on machine 1, shard-0 is backed up on machine 2, and shard-1 is backed up on machine 3. Even if machine 1 hangs up, machine 2 and machine 3 also include Complete shard-0, shard-1, shard-2 data.
3. Summary
1. Aggregation must have three elements: aggregation name, aggregation type, and aggregation field;
2. Aggregation configurable attributes include: size (specify the number of aggregation results), order (specify Aggregation result sorting method), field (specify aggregation field);
3. The Pinyin word segmenter is suitable for use when creating an inverted index, but cannot be used when searching;
4. References
1.https://docs.spring.io/spring-data/elasticsearch/docs/current/reference/html
2.https://www.bilibili.com/video/BV1LQ4y127n4
3.https://www.elastic.co/guide/en/elasticsearch/reference/6.0/search-aggregations-bucket-datehistogram-aggregation.html
5. Appendix
1.https://gitee.com/Marinc/nacos.git