REVIEW : knowledge about the process of map construction, "explain the whole process of bottom-up building knowledge map" basically covered up, what Amway, is excellent as a primer herein, this is not the original, the basic content from this (the original author If in doubt, contact deleted). Of course, the definition of the concept of mapping knowledge, no personal feeling is not completely uniform standards, the text classification and some views I do not entirely agree, there will be follow-up blog system set out my understanding and knowledge of the definition of related concepts map
“The world is not made of strings , but is made of things.”——辛格博士,from Google.
Mapping knowledge construction technologies include top-down and bottom-up two kinds. Wherein the top-down means is constructed by means of other websites Encyclopedia structured data source, and mode information extracted from the body of high-quality data, added to the knowledge base. And constructed from the bottom up, it is with a certain technical means to extract resources from the data disclosed acquisition mode, select the information with a higher degree of confidence, added to the knowledge base.
Mapping knowledge, semantic knowledge is structured for rapid concepts and their relationships described in the physical world, by the reduced data granularity level data from the document level, a large number of polymerization knowledge, in order to achieve fast response of knowledge and reasoning.
Current knowledge map has been widely used in industrial fields, such as Google Search field, Baidu search, eye in the sky LinkedIn economic spectrum, enterprise information in the field of social enterprise in the field of search patterns and so on.
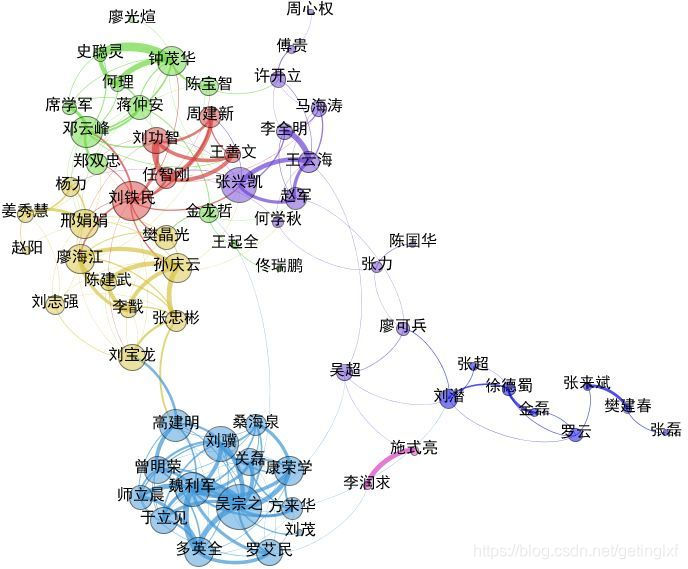
In the early technical development of the knowledge map, most of the participating companies and research institutions mainly top-down way of building basic knowledge, such as Freebase. With automatic knowledge extraction and processing technology continues to mature, the current mapping knowledge they use a bottom-up way of building, such as Google's Knowledge Vault and Microsoft Knowledge Base Satori.
1. Definitions
As the saying goes: "Man look at the face." Before our in-depth knowledge of maps, let's first look at what it looks like!
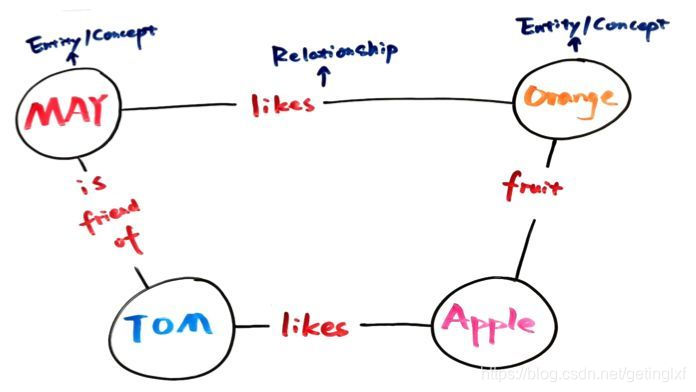
As shown, you can see if there is relationship between two nodes, they no one will be connected to the edges together, then this node, we called entity (entity), this edge between them, we are called relations (relationship).
The basic unit of knowledge map, is "entity (Entity) - entity (Entity) - relationship (Relationship)" core tuples, which is the mapping of knowledge.
2. The type of data storage and
Knowledge Mapping primitive data types in general have (three types of raw data is also on the Internet) into three categories:
- Structured data (Structed Data), such as relational databases
- Unstructured data, such as images, audio, video
- Semi-structured data such as XML, JSON, Encyclopedia of

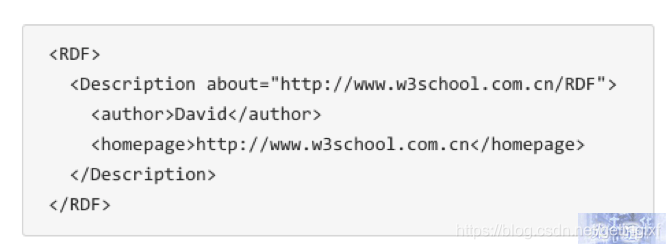
how to store it above these three data types? There are generally two options, one is to be stored with RDF (Resource Description Framework) format of such a specification is stored, and the like commonly used are Jena.
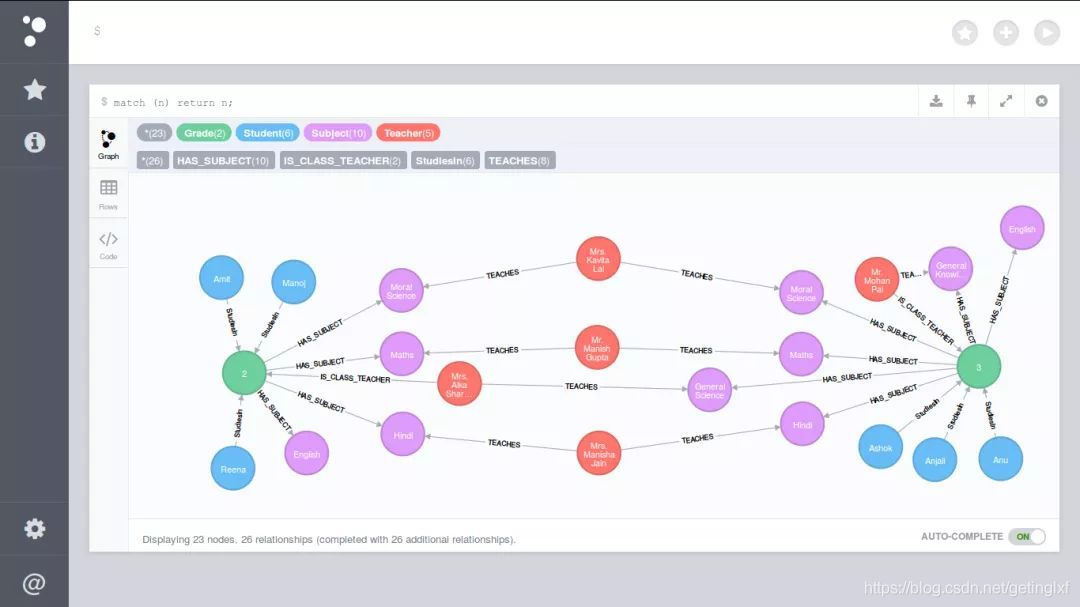
Another way is to use the map database for storage, and the like commonly used Neo4j.
Then you might ask me, not that you do a lot of triples, with a relational database to store is not the same thing.
Yes, with a relational database to store, especially storage simple knowledge map, technically is not in question.
But note that, once the mapping knowledge becomes complicated map database will be significantly higher than traditional relational data is stored in efficiency associated with the query. When we relate to 2,3 degrees associated with the query, the query efficiency of knowledge-based map will be higher than a few thousand times or even hundreds of times.
In addition, based on the design of the memory map will be very flexible, generally requires only local changes can be.
So if your data is large, it is recommended that directly map database to store.
3. Knowledge Mapping Architecture
Knowledge Mapping architecture can be divided into major:
- Logical Architecture
- Technology Architecture
3.1 Logical Architecture
在逻辑上,我们通常将知识图谱划分为两个层次:数据层和模式层。
- 模式层:在数据层之上,是知识图谱的核心,存储经过提炼的知识,通常通过本体库来管理这一层这一层(本体库可以理解为面向对象里的“类”这样一个概念,本体库就储存着知识图谱的类)。
- 数据层:存储真实的数据。
如果还是有点模糊,可以看看这个例子: - 模式层:实体-关系-实体,实体-属性-性值
- 数据层:比尔盖茨-妻子-梅琳达·盖茨,比尔盖茨-总裁-微软
3.2 技术架构
知识图谱的整体架构如图所示,其中虚线框内的部分为知识图谱的构建过程,同时也是知识图谱更新的过程。
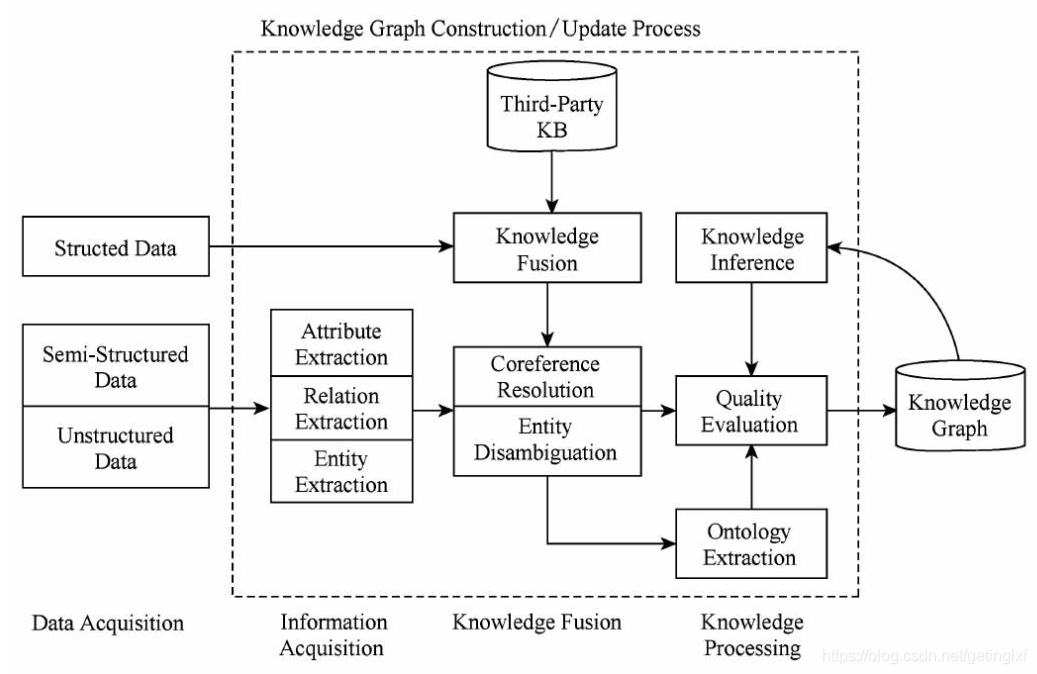
别紧张,让我们顺着这张图来理一下思路。首先我们有一大堆的数据,这些数据可能是结构化的、非结构化的以及半结构化的,然后我们基于这些数据来构建知识图谱,这一步主要是通过一系列自动化或半自动化的技术手段,来从原始数据中提取出知识要素,即一堆实体关系,并将其存入我们的知识库的模式层和数据层。
构建知识图谱是一个迭代更新的过程,根据知识获取的逻辑,每一轮迭代包含三个阶段:
- 信息抽取:从各种类型的数据源中提取出实体、属性以及实体间的相互关系,在此基础上形成本体化的知识表达;
- 知识融合:在获得新知识之后,需要对其进行整合,以消除矛盾和歧义,比如某些实体可能有多种表达,某个特定称谓也许对应于多个不同的实体等;
- 知识加工:对于经过融合的新知识,需要经过质量评估之后(部分需要人工参与甄别),才能将合格的部分加入到知识库中,以确保知识库的质量。
4. 构建技术
前面我们已经说过了,知识图谱有自顶向下和自底向上两种构建方式,这里提到的构建技术主要是自底向上的构建技术。
如前所述,构建知识图谱是一个迭代更新的过程,根据知识获取的逻辑,每一轮迭代包含三个阶段:
- 信息抽取:从各种类型的数据源中提取出实体、属性以及实体间的相互关系,在此基础上形成本体化的知识表达;
- 知识融合:在获得新知识之后,需要对其进行整合,以消除矛盾和歧义,比如某些实体可能有多种表达,某个特定称谓也许对应于多个不同的实体等;
- 知识加工:对于经过融合的新知识,需要经过质量评估之后(部分需要人工参与甄别),才能将合格的部分加入到知识库中,以确保知识库的质量,见下图
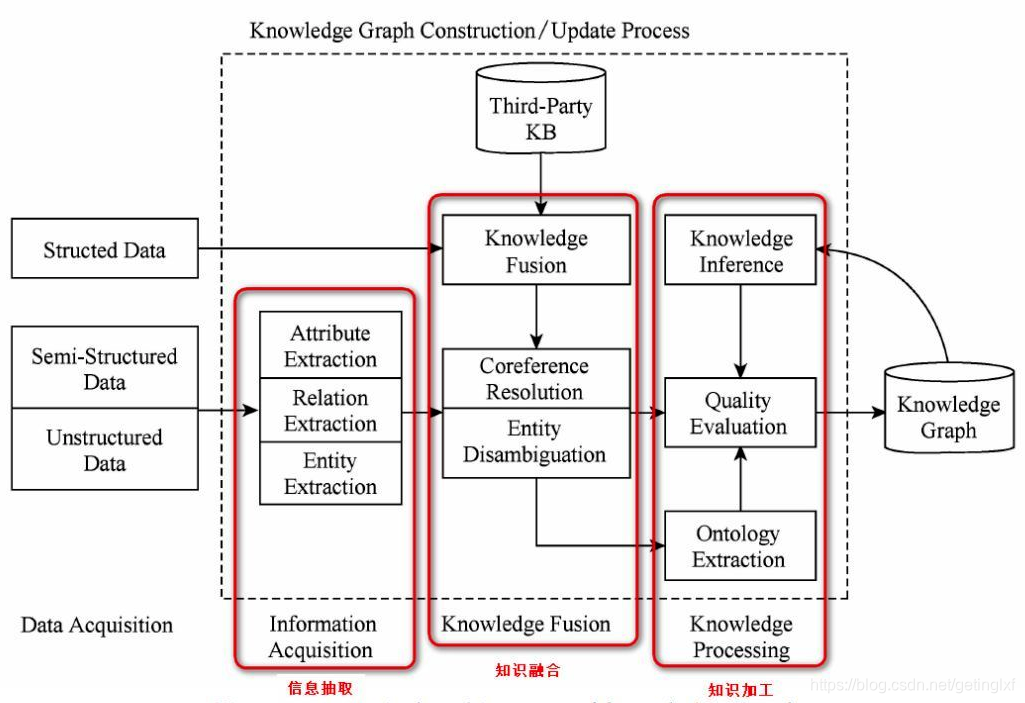
下面我们依次来对每一个步骤进行介绍。
4.1 信息抽取
信息抽取(infromation extraction)是知识图谱构建的第1步,其中的关键问题是:如何从异构数据源中自动抽取信息得到候选指示单元?
信息抽取是一种自动化地从半结构化和无结构数据中抽取实体、关系以及实体属性等结构化信息的技术。涉及的关键技术包括:实体抽取、关系抽取和属性抽取。
4.1.1 实体抽取
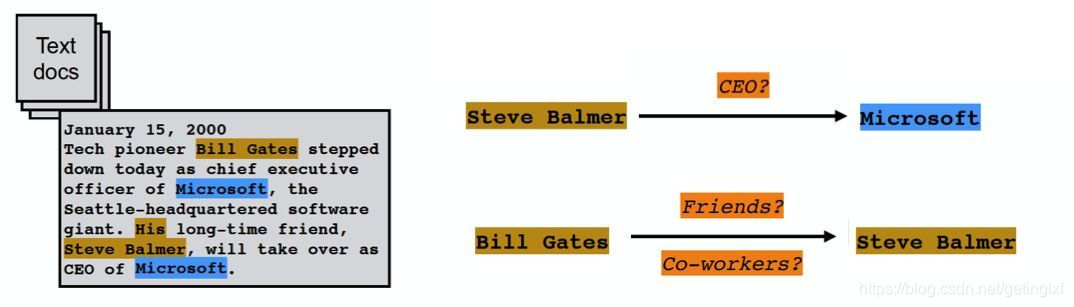
实体抽取,也称为命名实体识别(named entity recognition,NER),是指从文本数据集中自动识别出命名实体。
比如在下图中,通过实体抽取我们可以从其中抽取出三个实体——“Steve Balmer”, “Bill Gates”,和”Microsoft”。

实体抽取的研究历史主要是从面向单一领域进行实体抽取,逐步跨步到面向开放域(open domain)的实体抽取。
4.1.2 关系抽取
文本语料经过实体抽取之后,得到的是一系列离散的命名实体,为了得到语义信息,还需要从相关语料中提取出实体之间的关联关系,通过关系将实体联系起来,才能够形成网状的知识结构。这就是关系抽取需要做的事,如下图所示。
研究历史:
- 人工构造语法和语义规则(模式匹配)
- 统计机器学习方法(HMM、CRF)
- 基于特征向量或核函数的有监督学习方法
- 研究重点转向半监督和无监督
- 开始研究面向开放域的信息抽取方法
- 将面向开放域的信息抽取方法和面向封闭领域的传统方法结合
4.1.3 属性抽取
属性抽取的目标是从不同信息源中采集特定实体的属性信息,如针对某个公众人物,可以从网络公开信息中得到其昵称、生日、国籍、教育背景等信息。
研究历史:
- 将实体的属性视作实体与属性值之间的一种名词性关系,将属性抽取任务转化为关系抽取任务。
- 基于规则和启发式算法,抽取结构化数据
- 基于百科类网站的半结构化数据,通过自动抽取生成训练语料,用于训练实体属性标注模型,然后将其应用于对非结构化数据的实体属性抽取。
- 采用数据挖掘的方法直接从文本中挖掘实体属性和属性值之间的关系模式,据此实现对属性名和属性值在文本中的定位。
4.2 知识融合
通过信息抽取,我们就从原始的非结构化和半结构化数据中获取到了实体、关系以及实体的属性信息。
如果我们将接下来的过程比喻成拼图的话,那么这些信息就是拼图碎片,散乱无章,甚至还有从其他拼图里跑来的碎片、本身就是用来干扰我们拼图的错误碎片。
也就是说:
- 拼图碎片(信息)之间的关系是扁平化的,缺乏层次性和逻辑性;
- 拼图(知识)中还存在大量冗杂和错误的拼图碎片(信息)
那么如何解决这一问题,就是在知识融合这一步里我们需要做的了。知识融合包括2部分内容:
- 实体链接
- 知识合并
4.2.1 实体链接
实体链接(entity linking)是指对于从文本中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。
其基本思想是首先根据给定的实体指称项,从知识库中选出一组候选实体对象,然后通过相似度计算将指称项链接到正确的实体对象。
研究历史:
- 仅关注如何将从文本中抽取到的实体链接到知识库中,忽视了位于同一文档的实体间存在的语义联系。
- 开始关注利用实体的共现关系,同时将多个实体链接到知识库中。即集成实体链接(collective entity linking)
实体链接的流程:
- 从文本中通过实体抽取得到实体指称项;
- 进行实体消歧和共指消解,判断知识库中的同名实体与之是否代表不同的含义以及知识库中是否存在其他命名实体与之表示相同的含义;
- 在确认知识库中对应的正确实体对象之后,将该实体指称项链接到知识库中对应实体。
实体消歧是专门用于解决同名实体产生歧义问题的技术,通过实体消歧,就可以根据当前的语境,准确建立实体链接,实体消歧主要采用聚类法。其实也可以看做基于上下文的分类问题,类似于词性消歧和词义消歧。
共指消解技术主要用于解决多个指称对应同一实体对象的问题。在一次会话中,多个指称可能指向的是同一实体对象。利用共指消解技术,可以将这些指称项关联(合并)到正确的实体对象,由于该问题在信息检索和自然语言处理等领域具有特殊的重要性,吸引了大量的研究努力。共指消解还有一些其他的名字,比如对象对齐、实体匹配和实体同义。
4.2.2 知识合并
在前面的实体链接中,我们已经将实体链接到知识库中对应的正确实体对象那里去了,但需要注意的是,实体链接链接的是我们从半结构化数据和非结构化数据那里通过信息抽取提取出来的数据。
那么除了半结构化数据和非结构化数据以外,我们还有个更方便的数据来源——结构化数据,如外部知识库和关系数据库。
对于这部分结构化数据的处理,就是我们知识合并的内容啦。一般来说知识合并主要分为两种:
- 合并外部知识库,主要处理数据层和模式层的冲突
- 合并关系数据库,有RDB2RDF等方法
4.3 知识加工
经过刚才那一系列步骤,我们终于走到了知识加工这一步了!
感觉大家可能已经有点晕眩,那么让我们再来看一下知识图谱的这张架构图。
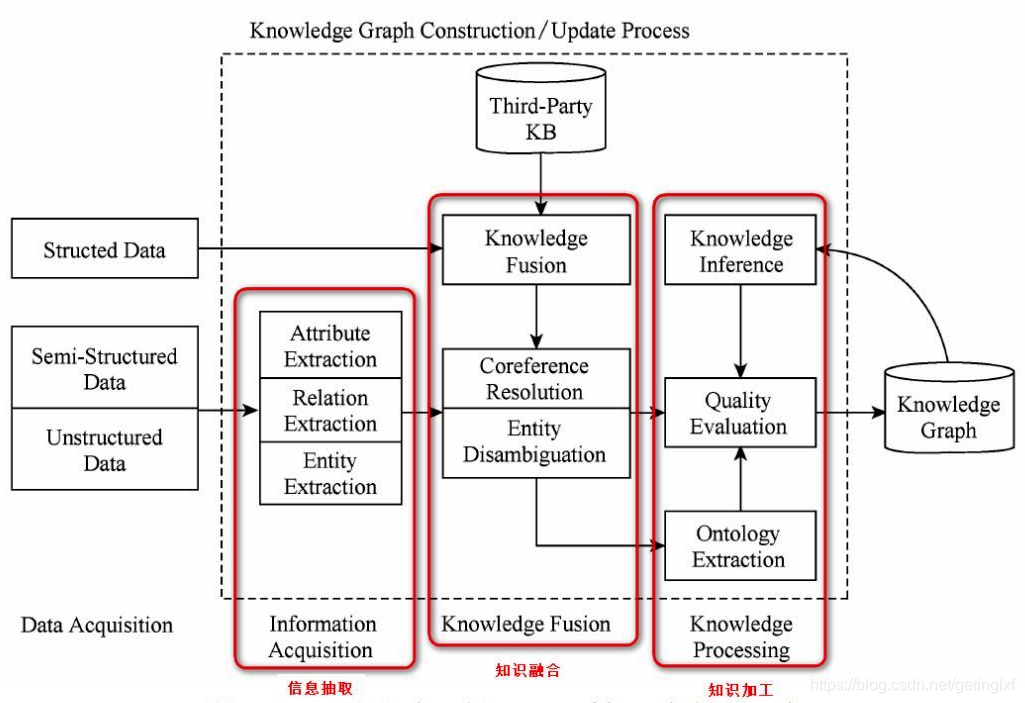
在前面,我们已经通过信息抽取,从原始语料中提取出了实体、关系与属性等知识要素,并且经过知识融合,消除实体指称项与实体对象之间的歧义,得到一系列基本的事实表达。
然而事实本身并不等于知识。要想最终获得结构化,网络化的知识体系,还需要经历知识加工的过程。知识加工主要包括3方面内容:本体构建、知识推理和质量评估。
4.3.1 本体构建
本体(ontology)是指公认的概念集合、概念框架,如“人”、“事”、“物”等。
本体可以采用人工编辑的方式手动构建(借助本体编辑软件),也可以以数据驱动的自动化方式构建本体。因为人工方式工作量巨大,且很难找到符合要求的专家,因此当前主流的全局本体库产品,都是从一些面向特定领域的现有本体库出发,采用自动构建技术逐步扩展得到的。
自动化本体构建过程包含三个阶段:
- 实体并列关系相似度计算
- 实体上下位关系抽取
- 本体的生成
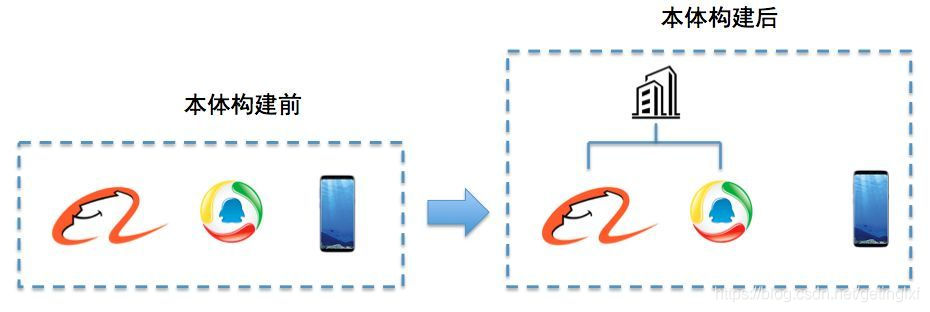
比如对下面这个例子,当知识图谱刚得到“阿里巴巴”、“腾讯”、“手机”这三个实体的时候,可能会认为它们三个之间并没有什么差别,但当它去计算三个实体之间的相似度后,就会发现,阿里巴巴和腾讯之间可能更相似,和手机差别更大一些。
这就是第一步的作用,但这样下来,知识图谱实际上还是没有一个上下层的概念,它还是不知道,阿里巴巴和手机,根本就不隶属于一个类型,无法比较。因此我们在实体上下位关系抽取这一步,就需要去完成这样的工作,从而生成第三步的本体。
当三步结束后,这个知识图谱可能就会明白,“阿里巴巴和腾讯,其实都是公司这样一个实体下的细分实体。它们和手机并不是一类。”
4.3.2 知识推理
在我们完成了本体构建这一步之后,一个知识图谱的雏形便已经搭建好了。但可能在这个时候,知识图谱之间大多数关系都是残缺的,缺失值非常严重,那么这个时候,我们就可以使用知识推理技术,去完成进一步的知识发现。比如在下面这个例子里:
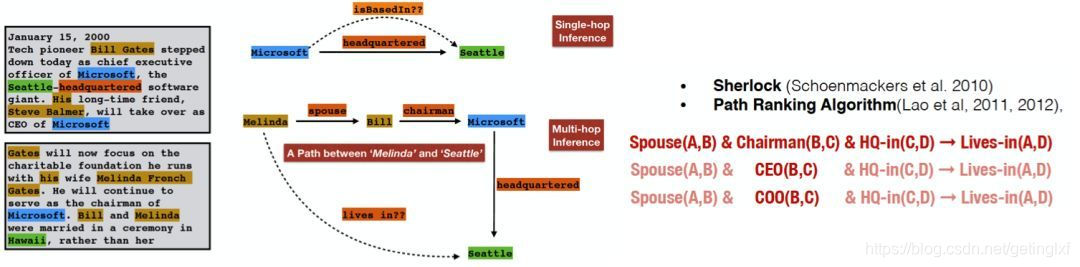
我们可以发现:如果A是B的配偶,B是C的主席,C坐落于D,那么我们就可以认为,A生活在D这个城市。
根据这一条规则,我们可以去挖掘一下在图里,是不是还有其他的path满足这个条件,那么我们就可以将AD两个关联起来。除此之外,我们还可以去思考,串联里有一环是B是C的主席,那么B是C的CEO、B是C的COO,是不是也可以作为这个推理策略的一环呢?
当然知识推理的对象也并不局限于实体间的关系,也可以是实体的属性值,本体的概念层次关系等。比如:
- 推理属性值:已知某实体的生日属性,可以通过推理得到该实体的年龄属性;
- 推理概念:已知(老虎,科,猫科)和(猫科,目,食肉目)可以推出(老虎,目,食肉目)
这一块的算法主要可以分为3大类,基于逻辑的推理、基于图的推理和基于深度学习的推理。
4.3.3 质量评估
质量评估也是知识库构建技术的重要组成部分,这一部分存在的意义在于:可以对知识的可信度进行量化,通过舍弃置信度较低的知识来保障知识库的质量。
好啦,在质量评估之后,你是不是想说,妈耶知识图谱终于构建完毕了。终于可以松一口气了。
好吧,实不相瞒,知识图谱这个宝宝目前虽然我们构建成功了。
但是!你家宝宝不吃饭的啊!你家宝宝不学习的啊!
所以,让我们冷静一下,乖乖进入知识更新这一步……
4.4 知识更新
从逻辑上看,知识库的更新包括概念层的更新和数据层的更新。
概念层的更新是指新增数据后获得了新的概念,需要自动将新的概念添加到知识库的概念层中。
数据层的更新主要是新增或更新实体、关系、属性值,对数据层进行更新需要考虑数据源的可靠性、数据的一致性(是否存在矛盾或冗杂等问题)等可靠数据源,并选择在各数据源中出现频率高的事实和属性加入知识库。
知识图谱的内容更新有两种方式:
- 全面更新:指以更新后的全部数据为输入,从零开始构建知识图谱。这种方法比较简单,但资源消耗大,而且需要耗费大量人力资源进行系统维护;
- 增量更新:以当前新增数据为输入,向现有知识图谱中添加新增知识。这种方式资源消耗小,但目前仍需要大量人工干预(定义规则等),因此实施起来十分困难。
5. 知识图谱的应用
好了!终于终于!知识图谱的构建方式我们就此结束了!
为了让大家不立刻弃疗,让我们来看看知识图谱能做到什么,以及目前已经做到了什么~
- 智能搜索——也是知识图谱最成熟的一个场景,自动给出搜索结果和相关人物
- 构建人物关系图,查看更多维度的数据
- 反欺诈:这主要有两部分原因,一个是反欺诈的数据来源多样,结构化和非结构化,二是不少欺诈案件会涉及到复杂的关系网络
- 不一致性验证(类似交叉验证)——关系推理
- 异常分析(运算量大,一般离线)
- 静态分析:给定一个图形结构和某个时间点,从中去发现一些异常点(比如有异常的子图)。
- 动态分析:分析其结构随时间变化的趋势。(假设短时间内知识图谱结构的变化不会太大,如果它的变化很大,就说明可能存在异常,需要进一步的关注。会涉及到时序分析技术和图相似性计算技术。)
- 失联客户管理 挖掘出更多的新联系人,提高催收的成功率。
……
In fact, the application of knowledge map is far more than that. In my opinion, this world is a huge knowledge maps, numerous entities relations, the past two years the industry's huge demand for map database, knowledge map also reflects this.
references
[1] bottom-up map of the whole process of building knowledge
