Abstract
Filter (filter) is the most effective method of pruning convolutional neural network acceleration and compression. In this work, we propose pruning algorithm called global filters Gate Decorator, which is output by a common channel CNN module multiplied by a scaling factor (ie gate, the code for g) to be conversion. When the scale factor is set to 0, corresponding to delete the corresponding filter. We use the Taylor expansion function to estimate the loss due to the change in the scale factor set to zero caused, and to estimate the importance of using the Taylor expansion sorted global filters. Then we come to prune the network by removing unimportant filter. After the trimming, all of the scale factors will be incorporated into the original module, and therefore does not introduce special operation or structure. In addition, we propose an iterative pruning framework called Tick-Tock, in order to improve the accuracy of pruning. A large number of experiments demonstrate the effectiveness of our approach. For example, we implemented on ResNet-56 the most advanced pruning proportion, 70% reduction of Flops, but without significant loss of accuracy. For ResNet-50 on ImageNet, our model trim 40% reduction in FLOPs, than the baseline model extra 0.31% of the top-1 precision. Using a variety of datasets, including CIFAR-10, CIFAR-100, CUB-200, ImageNet ILSVRC-12 and PASCAL VOC 2011.
1 Introduction
In recent years, we have witnessed remarkable achievements in CNNs many computer vision tasks [40,48,37,51,24]. In the strong support of modern gpu, CNN models can be designed to be larger and more complex in order to get better performance. However, a large number of computing and storage consumption will hinder the deployment of the most advanced models on resource-constrained devices such as mobile phones or the Internet of Things devices. Mainly from three constraint [28]: 1) the model size. 2) memory running. 3) calculate the number of operations. In the widely used VGG-16 [39] model as an example. The model parameters have as many as 138 million, consumes more than 500MB of storage space. In order to deduce a memory to store the intermediate output image is 224 × 224 resolution, the model needs to 16 billion floating point arithmetic (FLOPS) and additional runtime 93MB, which is a heavy burden for the low-end equipment is. Therefore, network compression and acceleration method has aroused great interest.
Recent studies on model compression and acceleration can be divided into four categories: 1) quantify [34,55,54]. 2) fast convolution [2,41]. 3) low rank approximation [7,8,50]. 4) filtering pruning [1,30,15,25,28,33,56,52]. In these methods, a filter pruning (also known as channel prune) and its significant advantages attracted much attention. First, the filter is a general pruning technique can be applied to various types of CNN model. Second, the filter does not change the model trim design, which makes it very easy with other compression and acceleration techniques combined. In addition, the network does not require special hardware or software to achieve accelerated after pruning.
Neural pruning was first proposed by Optimal Brain Damage (OBD) [23,10], which LeCun et al found that some neurons can be deleted, but will not cause significant loss of accuracy. For CNNs, we prune the network layer filter, so we prune this technology called a filter (FIG. 1).
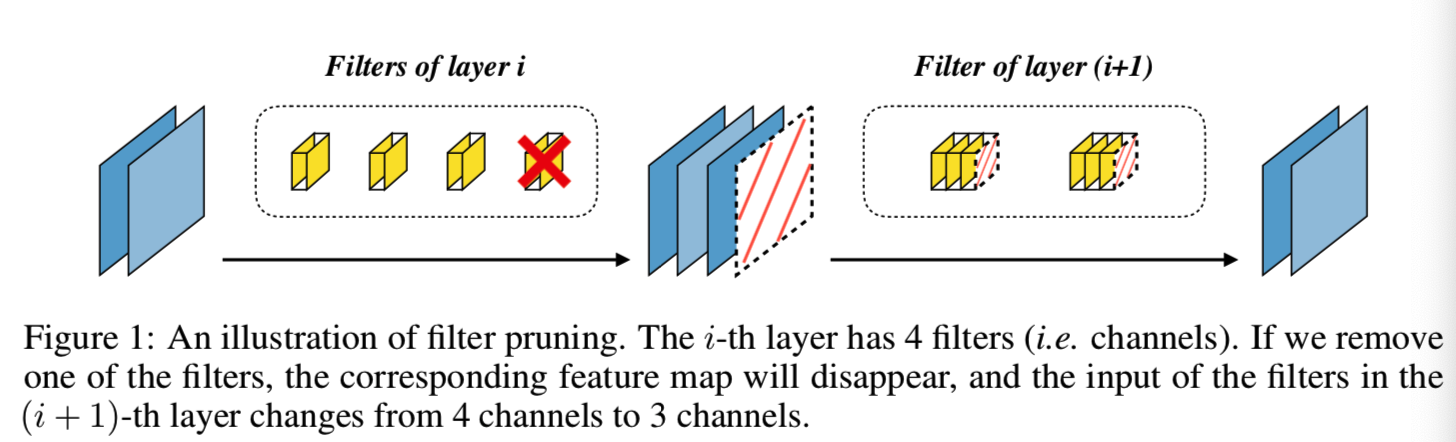
Research on pruning filter may be divided into two categories: 1) layer by layer pruning [30,15,56]. 2) Global pruning [25,28,33,52]. Layer by layer pruning method is to remove every layer of a particular filter, until certain conditions are met, then the characteristics of the layer to minimize the reconstruction error. However, the filter layers of pruning is very time consuming, especially for deep network. In addition, each layer need to set a predefined proportion pruning, which eliminates the ability of neural structure search filter pruning algorithm, we will discuss in Section 4.3. On the other hand, the global pruning method to delete unimportant filter, no matter what level they are. Global filter advantage is that we do not need to prune pruning ratio set for each layer. In the case given the overall goal of pruning, the algorithm will reveal the optimal network structure found. The key global pruning method is to solve the problem of global filter order of importance (GFIR, , Ltd. Free Join filter Importance Ranking problem ) .
In this paper, we propose a new global filter pruning method, which consists of two parts: The first part is GFIR Gate Decorator algorithm used to resolve the problem. The second frame is Tick-Tock prune, prune to improve accuracy. In particular, we show how the Gate Decorator applied Batch Normalization [19], and calls the module revised Gate Batch Normalization (GBN). It should be noted that the module is converted by the Gate Decorator is designed to meet the temporary purpose of pruning designed . To the model given a pre-trained, we will convert BN module GBN, then trim. When the trim, we will change back to normal GBN BN . Thus, the need to introduce special operations or structures. A large number of experiments demonstrate the effectiveness of the method. We realize the ResNet-56 on [11] the most advanced pruning proportion, 70% reduction of Flops, but without significant loss of accuracy. In [4] the ImageNet, we reduced Flops 40% of ResNet-50 [11], while increasing the top-1 of 0.31% accuracy. Our contribution can be summarized as follows:
We propose a global pruning filter pipeline, which consists of two parts: part GFIR Gate Decorator algorithm used to resolve the problem, the other is used to increase the Tick-Tock prune pruning frame accuracy. In addition, we propose a group pruning pruning techniques to solve the constraint (Constraint Pruning) problems encountered when using ResNet [11] Such a structure has a shortcut network network pruning.
(b) The results show that our method is superior to the most advanced methods. We have extensively studied the nature of the algorithm and the GBN Tick-Tock framework. Further evidence of the global filtering pruning methods can be seen as a task-driven network structure search algorithm.
2 Related work
Filter Pruning. Filter pruning is a very accelerated CNNs of promising solution. Many inspiring works to eliminate these filters by their importance assessed. Proposed convolution kernel [25] size, [17] and the like zero mean percentage activation function (the APOZ) heuristic metrics (Heuristic metric). Luo et al [30], and He et al [15] used to select Lasso regression characterized in that the lower layer of the filter minimum reconstruction error. On the other hand, Yu et al [52] to optimize the final reconstruction error responsive layer and spread the importance score of each filter. Molchanov, who uses Taylor to assess the impact of the loss of function of the final filter. Another type of training network works under certain restrictions, to eliminate some of the filters or in which the discovery redundancy. Zhuang et al perception by applying additional loss of recognition of pre-training model to fine-tune and filter helps retain the ability to identify and obtain good results. However, the perception of loss recognition is designed for classification tasks, which limits the scope of its use. Liu et al [28] and Ye et al. [49] The scale factor applied to each filter, the loss is increased training sparse constraints. Ding et al proposed a new optimization method, by training a plurality of filters to achieve the same values, the redundant filter is then removed safely. These methods need to start training model, which is very time-consuming for large data sets.
Methods OTHER . Network quantization method compressed by reducing the number of different parameter values. 32-bit floating point quantized parameter ternary or binary (ternary). But these aggressive quantitative policy is usually accompanied by a loss of accuracy. [55, 54] showed that when using appropriate quantitative strategy, quantify network and even beyond the full precision network. In recent years, a new convolution design. Chen et al., Designed a convolution unit OctConv a plug and play, according to the frequency mixing unit factoring feature map. Experimental results show that, OctConv accuracy of the model can be improved while reducing the amount of calculation. Low rank decomposition [7,8,5] approximate weights of the network with a plurality of low-rank matrix. Another popular network to accelerate the research was to explore the network architecture design. Many computing architectures efficiency [16,36,53,32] have been proposed for mobile devices. These networks are designed by a human expert. In order to combine the advantages of the computer to automatically search for the neural structure (NAS) recently it has attracted widespread attention. Many studies have been proposed, including those based on reinforcement learning [57], based on gradient [47,27], [35] Based on the method of evolution. It is worth noting that the method Gate Decorator our proposed algorithm described in this section are orthogonal ( Orthogonal ). That is, Gate Decorator these methods may be combined with, and processing to achieve higher compression rates.
3 Method
In this section, we first introduce Gate Decorator (GD) GFIR to solve the problem. And show how to apply to GD Batch Normalization [19]. Then, we propose an iterative pruning framework called Tick-Tock, with better precision pruning. Finally, we introduce a set of constraints pruning pruning techniques to solve problems encountered when using shortcuts (ie resnet network, etc.) for network pruning.
3.1 Problem Definition and Gate Decorator
Formally, so L (X, Y; θ) denotes a training model loss function, wherein input data X, Y is the respective tag, [theta] is a parameter of the model. We denote the set of all network filters with K. Filter Trim is to select a subset of the filter k⊂K, remove them from the network parameters corresponding to θ K - . We note that the left side of the parameter [theta] k + that is, after pruning the rest of the parameters, we have [theta] k + ∪θ k - = [theta]. In order to minimize the increase of loss, we need to carefully select k by solving the following optimization problem:
![]()
Which, || k || 0 is the number of elements of k, a simple solution to this problem is to try all possible k and choose the best to minimize the impact of the loss. But it is necessary to calculate K || || 0 Ci = [Delta] L | L (X-, the Y); [theta]) -L (X-, the Y); [theta] K + ) | trimmed to complete iteration, this is not feasible deep model, which has tens of thousands of filters. To solve this problem, we propose Gate Decorator to effectively assess the importance of the filter.
Suppose wherein the mapping output z k is the filter, we let z be multiplied by a scale factor φ∈R training and z = φz used for further calculations. When the gate φ is zero, which is equivalent to the filter trimmer k. Using the Taylor expansion, we can evaluate about pruning ΔL. First, for convenience of notation, we have the equation (2) can be rewritten [Delta] L, of the formula Ω comprising X, Y and all of the model parameters except φ. Thus L [Omega] ([Phi]) is a unary function wrt φ.
![]()
Then using Taylor expansion formula L In Equation (3) and (4) [Omega] (0)

Connecting equations (2) and (4) can be obtained:
![]()
R 1 is a Lagrange remainder we ignore this one because it requires a lot of computing. Now, we can based on the equation (5) GFIR solving problems, back-propagation process, this problem is easily calculated. Each filter K I ∈ K, we use equations (6) are calculated [Theta] ([Phi] I ), i.e., the importance score of the filter, D is the training set:
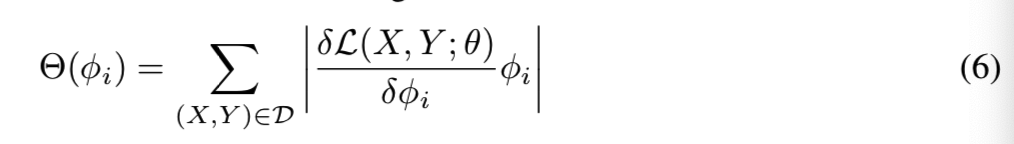
In particular, we applied to the Gate Decorator Batch Normalization [19] in, and used in our experiments. We will block the revised Gate Batch Normalization called GBN. We chose BN module for two reasons: 1) BN layer in most cases follow the convolution layer. Thus, we can easily find the corresponding relationship between the filter and the characteristics of BN layer mapping. 2) We can use the scaling factor γ BN in the rankings provide clues to φ (For more information, see Appendix A):

GBN is defined in Equation (7), φ⃗ φ is a vector, c is Z in channel size:
![]()
Also, do not use the network BN, we can also be applied directly to the Gate Decorator convolution. Gated convolution defined in Appendix B:

3.2 Tick-Tock Pruning Framework
In this section, we introduce an iterative pruning pruning framework to improve the accuracy of the frame is called Tick- tock (FIG. 2).
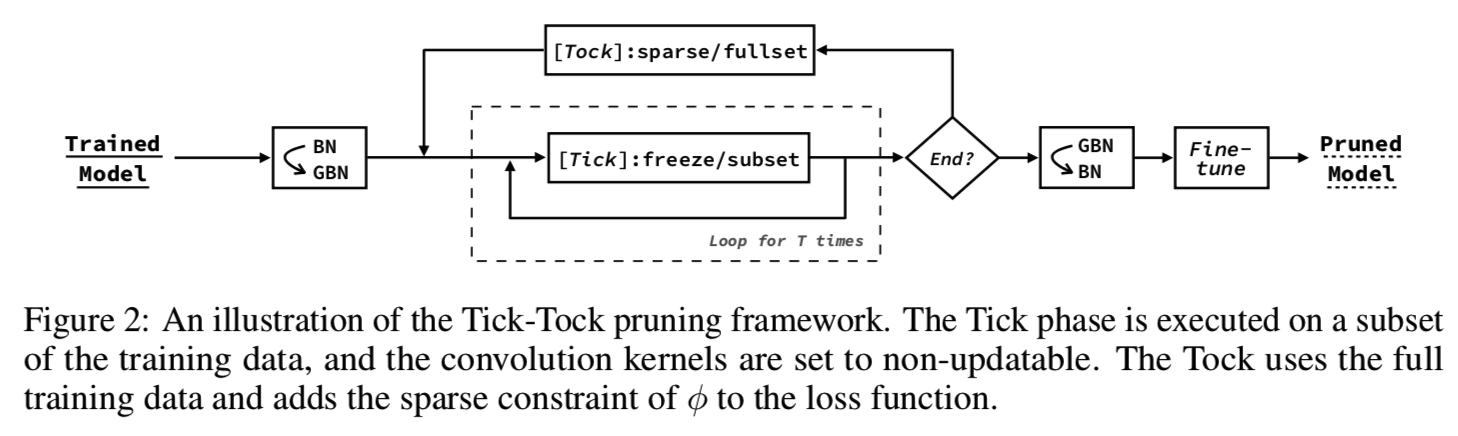
Tick steps designed to obtain the following goals:
1) Acceleration pruning
2) calculate the importance score of each filter Θ
3) Trim caused by internal covariates shift until repair issues [19]
In Tick stage, each epoch we use a subset of training data to train the model, we allow only linear gate φ and last layer is updated , in order to avoid excessive concentration occurs in the small to fit the data. Θ calculated importance score propagation backward in accordance with equation (6) . After the training, we use all the importance scores Θ sort of filter, and delete the least important part of the filter.
Tick阶段可以重复T次,直到进入Tock阶段。Tock阶段的目的是对网络进行微调,以减少由于删除过滤器而导致的错误积累。除此之外,对φ的稀疏约束将添加到训练期间的损失函数中,这有助于揭示了不重要的过滤器和计算Θ更准确。Tock中使用的损失函数如式(8)所示:
![]()
最后,我们对修剪后的网络进行微调以获得更好的性能。Tock步骤和Fine-tune步骤有两个不同之处:1)Fine-tune通常比Tock训练更多的epochs。2)Fine-tune不向loss函数添加稀疏约束。
3.3 Group Pruning for the Constrained Pruning Problem
ResNet[11]及其变体[18、46、43]包含shortcut连接,它将元素明智地添加到由两个剩余块生成的特征映射上。如果我们单独对每一层的过滤器进行修剪,可能会导致shortcut连接中特征映射的不对齐。
若干解决办法被提出。[25,30]绕过这些麻烦的层,只修剪残差块的内层。[28,15]在每个残差块的第一个卷积层之前插入一个额外的采样器,不修剪最后一个卷积层。然而,避免麻烦层的方法限制了修剪比例。此外,采样器解决方案为网络添加了新的结构,这将引入额外的计算延迟。
为了解决这一问题,我们提出了组剪枝的方法:将由纯shortcut connection 连接的GBNs分配给同一组。纯shortcut connection是侧支上没有卷积层的快捷方式,如图3所示:
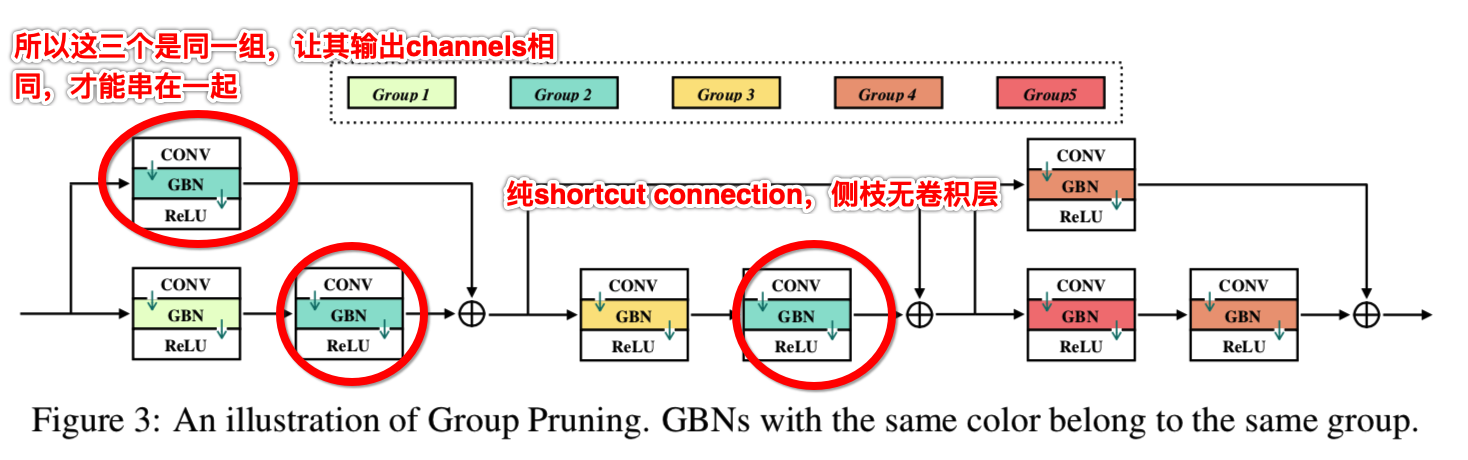
一个组可以被看作是一个虚拟的GBN,它的所有成员共享相同的修剪模式。一个组中过滤器的重要性分数是其成员的总和,如等式(9)所示:

g是在组G中GBN成员之一,在组G中所有成员中排名第j的过滤器的重要性分数定义为Θ(φjG)。
3.4 Compare to the Similar Work.
PCNN [33] also uses Taylor GFIR to solve the problem.
Gate Decorator and PCNN proposed differs in three ways:
1) Since there is no scale factor is introduced, on PCNN characterized by their degree of importance of the Taylor polynomial FIG summing the evaluation of the filter element of the first order of each score, which accumulates estimation error.
2) due to lack of scale factor, PCNN not use sparse constraint. However, according to our experiments, sparse constraint plays an important role in improving the accuracy of pruning.
3) scores for standardized cross-layer PCNN is necessary, but for Gate Decorator is not. This is because the method PCNN used to calculate the degree of importance of the accumulated score, which can lead to scale with the size of the features of FIG fractional cross-layer changes. We gave up the score standardization, because our ratings are globally comparable, standardized to introduce a new estimate of the error.
4 Experiments
Omission
5 Conclusion
In this work, we propose three components to serve the purpose of the global filter trimmed:
1) Gate Decorator to address global filter Sort importance (GFIR) problem.
2) Tick-Tock frame, improving the accuracy of trimming.
3) group pruning pruning method to solve the constraint problem.
We prove the global filter pruning method can be seen as a task-driven network structure search algorithm. A large number of experiments show that this method superior to some of the most advanced filtering pruning methods.