Abstract
- Explains the "norm-based criterion" used in the previous work. It needs to be valid under two conditions:
1. The variance of the
norm should be large 2. The minimum value of the norm should be relatively small (I think this It's relatively easy to satisfy) - Proposed: Filter Pruning via Geometric Median (FPGM),
- Achieved good results on Cifai10 (feeling a bit low)
Introduction
-
The current pruning can be
divided into two categories: 1.weight pruning (resulting in unstructured sparseness)- learning compression algorithms for neural net pruning.
- Learning both weights and connections for efficient neural network.
2.filter pruning (what the article wants to say)
- Pruning networks using neuron importance score propagation.
- Pruning filters for efficient ConvNets.
-
Some current pruning methods based on size criteria (Figure 1a):
1. Pruning filters for efficient ConvNets.
2. Rethinking the smaller-norm-less-informative assumption in channel pruning of convolution layers
3. Soft filter pruning for accelerating deep convolutional neural networks.
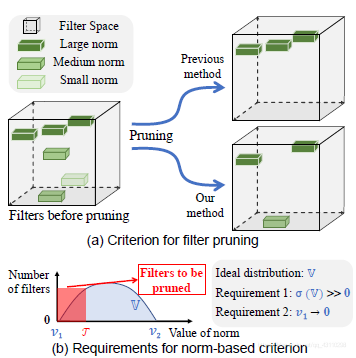
If this is effective, then the pruning of all layers will have the same impact on the whole. In addition, it also needs a threshold. This threshold can also be changed according to the layer, and the standard for determining the threshold can also be changed according to the layer.
-
The FPGM pruning algorithm proposed in this paper does not choose the maximum norm criterion, but chooses to calculate the GM of all filters to find the filter that is most easily replaced. Principle: A certain convolution kernel can be replaced by a similar linear.
RelatedWorks
- Weight Pruning
- learning compression algorithms for neural net pruning[11].
An iterative-based method that removes the weight less than the threshold each time - Learning both weights and connections for efficient neural network.
Minimize loss function
- Data Dependent Filter Pruning
- Starting from the statistical results of the next layer, pruning
- Data Independent Filter Pruning
Methodology
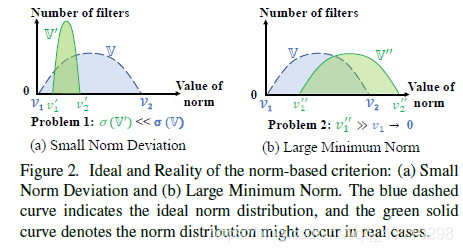
- Generally speaking, the true distribution is different from the hypothetical distribution.
In fact, the so-called real distribution here is also imagined, without experimenting. In addition, how do you ensure that each layer obeys unimodal rather than bimodal, or long-tailed distribution?
In addition, different models, different layers of the model, and even different inputs will cause the distribution to change