For dual-write cache and database that there is data consistency problems. For data consistency demanding business scenarios, we usually choose to use distributed transactions (2pc, paxos, etc.) to ensure strong data consistency between the cache and the database, but the complexity of distributed transactions with the occupation of resources question, so that the treatment can cause system performance degradation. For data consistency requires not so high business scenarios for distributed transaction processing mode will seem not so necessary. For this reason, in general, the requirements for data consistency is not so high business scenarios, will choose to use the cache-aside-pattern scheme to ensure between the cache and the database, the final consistency of the data, the following article is to introduce and organize the contents of the cache-aside-pattern scheme.
For the data in the cache, we propose three objectives :
- As far as possible not in the database of old data into the cache
- Allows the presence of data in the cache data in the database a short time inconsistency
- Data in the cache data present in the database inconsistent data time should be as short
For dual-write cache issue with the database, nothing less than " CRUD " these four processes, then take into account the concurrent " read, write, read and write ", all possible combinations are not many. For this reason, we can be an exhaustive description of the way the program uses.
check:
For finding the data, process the program data and the cpu lookup process is consistent, the process is as follows:
- First find the data in the cache, the cache hit when the data is returned when the search ends.
- When there is no cache hit, find the database on the database to find out the relevant data is processed, after the relevant data into the cache, the search ends.
Which diagram is as follows:
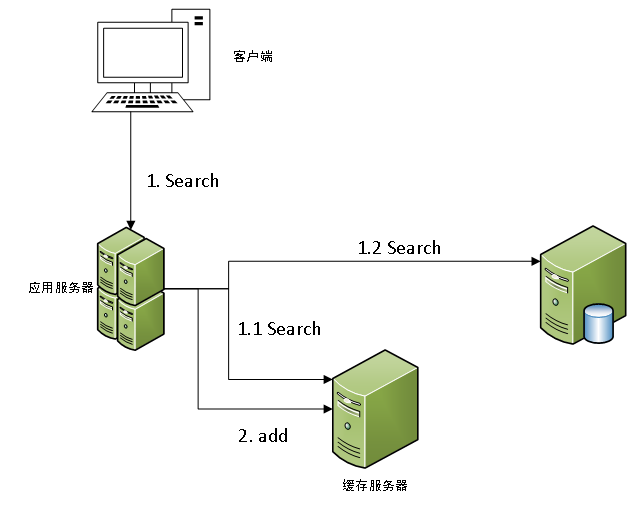
In consideration of high concurrent queries case, the process is, as shown FIG.

当客户端1、客户端2、....、客户端n查询同一数据,且该数据不存在于缓存中时,所有的客户端请求都会去访问数据库,此时会出现缓存击穿的情况,对于缓存击穿的相关问题及解决方案,我们留到下一篇文章再进行讲解。
增:
对于新增数据的情况,我们将数据直接添加进数据库中,且不将新增的数据加载入缓存中,其过程如下示意图所示:

在考虑高并发之时,其过程如下示意图所示:

通过示意图,我们了解到,当采用该种方式新增数据时,在并发情况下,并未出现与我们的目标相违背的问题。
删:
当需要对数据进行删除时,我们有两种删除的方案可供选择。
第一种: 先删除缓存中的数据,再删除数据库中的数据
第二种: 先删除数据库中的数据,再删除缓存中的数据
我们对这两种方案分别进行分析:
先删缓存:
对于先删除缓存中的数据,后删除数据库中的数据这种方案,其示意图如下:
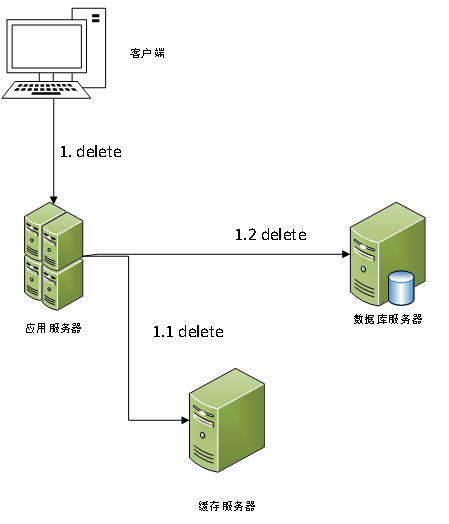
考虑进高并发的情况,当存在读请求和删除数据的请求并发时,由于网络的不可靠和延时问题,其可能出现如下示意图所示的情况:

通过示意图我们了解到,存在着缓存中缓存进已删除的旧数据的情况,这违背了我们提出的第一个目标。
那么,先删除数据库中的数据的情况呢?会出现这样的问题吗?我们接着分析。
先删数据库:
对于先删除数据库中的数据,后删除缓存中的数据这种方案,其示意图如下。
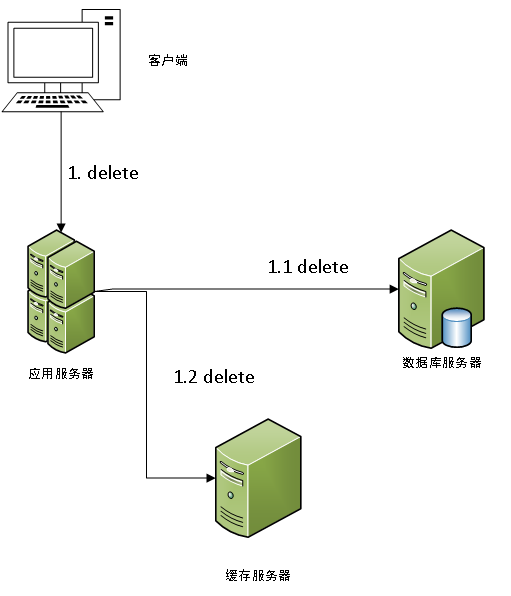
同样考虑进高并发的情况,当存在读请求和删除数据的请求并发时,其发生的情况如下示意图所示:

此时,并未出现与我们的目标相违背的问题。综上,我们在删除数据时,应选择先删除数据库中的数据再删除缓存中的数据的这一方案。
但是该方案仍存在着问题。我们再往下思考,当删除了缓存中的相关数据,此时来了大量读取该数据的请求。这时,就会导致“缓存穿透”问题的出现(该问题同样在下一篇文章中进行讲解)。
改:
当需要对数据进行变更的时候,我们有三种方案可供选择。
第一种: 先更新数据库,后更新缓存
第二种: 先删除缓存,后更新数据库
第三种: 先更新数据库,后删除缓存
我们对这三种方案逐一进行分析。
先更新数据库,后更新缓存:
对于先更新数据库,后更新缓存这种方案,其示意图如下:
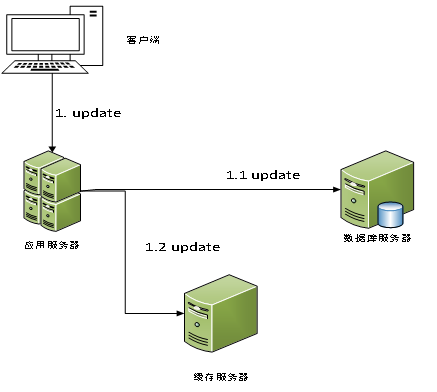
考虑高并发的情况,当存在两个更新操作的并发请求时,由于网络的延时问题,其可能会出现如下这种情况:

由上述示意图可知,当存在两个更新操作时,其有将数据库中的旧数据存入缓存中的情况,这违背了我们的第一个目标。那么,有没有办法解决呢?答案是有的,借助乐观锁的相关思想,我们可以给每个数据加上一个版本号,当数据要存入缓存时,比较一下数据的版本号即可。到目前为止,更新了数据库中的相关数据之后,再更新缓存中的数据这个方案看起来是可以的,但是这个方案存在着一个问题,就是需要去更新缓存中的数据,更新缓存中的数据这个操作会影响系统的性能。特别是在写多读少,且缓存的数据不是直接从数据库中存入,而是经过计算之后再进行缓存的业务场景中时,对系统性能造成的影响会更加明显。为此我们可以借助“懒加载”的思想,在更新数据之时,将缓存中的数据进行删除,等到需要用到的时候,才将数据加载进缓存中。下面我们将讨论在更新时删除缓存的两个可能的方案。
先删除缓存,后更新数据库:
对于先删除缓存,后更新数据库的方案,其示意图如下:
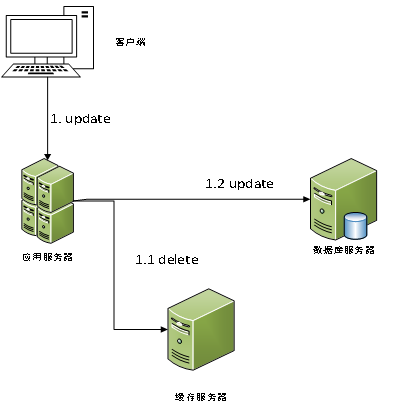
考虑高并发的情况,当存在读请求和更新请求并发的情况,由于存在网络延时,其可能出现如下示意图中的情况:

由示意图中的情况可知,在读写并发的情况下,其存在着将数据库中的旧数据存入缓存中的问题。这违背了我们的第一个目标。
先更新数据库,后删除缓存:
For the first case of the database update, delete the cache, which is shown in the following diagram:
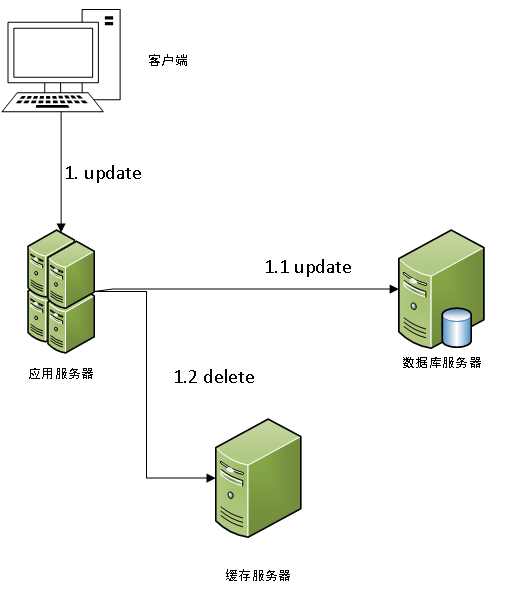
Concurrent consideration, when there is concurrent read request and an update request, and the data in the cache at this time exactly failure, plus delay due to network problems, there is a possibility where a schematic as shown below will appear.

It is seen from the schematic, when a failure happens to the data cache, there may be a possibility that it is stored in the database cache, the old data. However, the probability of this happening is relatively low, because the conditions so that this kind of situation appears more "harsh", just you need the data in the cache of failure, and require "read" slower than "write." But under normal circumstances, "write" is slower than "read", since write operations generally involve related operations database lock.
In summary, after comparing the three programs mentioned above, in the case of changed data, we used to update the database, delete the cache mode.
