HashMap which involves a lot of knowledge, basic skills may be more comprehensive study of the interviewer, you want to get a good offer, this is a step, but the sill, then I use the most simple language to bring everyone opened HashMap mystery.
A: HashMap node
HashMap is a collection, the collection of key-value pairs, with each node in the source Node <K, V> represents
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
...
}
Node is an internal class, key here is a bond, value is a value, next point to the next element, it can be seen in the HashMap element is not a simple key-value pair, further comprising a reference to the next element.
Two: HashMap data structure
HashMap data structure array + (red-black tree or list), the figure:
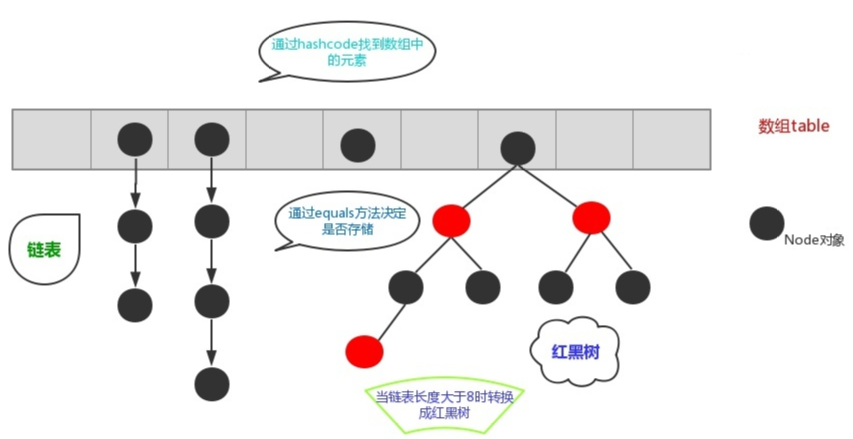
Why use this structure to store the elements?
An array of features: high efficiency query, insert, delete low efficiency.
List of features: low query efficiency, high insertion deleted efficiency.
Use HashMap infrastructure plus an array (or list red-black tree) is the perfect solution to the problem of arrays and linked lists, making the query and insert, delete efficiency are high.
Three: Process HashMap storage elements
There is such a piece of code:
The HashMap <String, String> Map = new new the HashMap <String, String> ();
map.put ( "Andy", "Mei" );
map.put ( "Cheung", "Big S");
Now I want the key to "Andy", "Sherry" is stored in map:
The first step: calculate the key "Andy" a hashcode, this value is used to locate the element To stored in what position in the array.
What is the hashcode? There is a method in Object class:
public native int hashCode();
The method uses native modification, it is a local method, the method is the so-called local non-java code, the code is usually written in c or c ++, java can go in to call it. Calling this method generates an int type integer, we call it hash code, hash code and call it object address and content.
Features hash code is:
For if the same object has not been modified (using the equals compare returns true) then whenever the hashcode values are the same.
For two objects if their equals returns false, then their hashcode value may also be equal.
Hashcode understand how we look hashcode targeting elements to be stored where the array, the array length and by a hashcode value we can get the modulo index storage element. Andy's hashcode to 20,977,295 array will have a length of 16 is stored in the array index% 16 = 20977295 where 1.
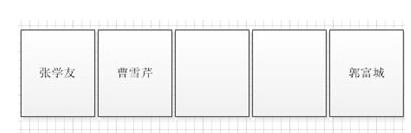
It can be divided into two cases:
1. 数组索引为1的地方是空的,这种情况很简单,直接将元素放进去就好了。
2. 已经有元素占据了索引为1的位置,这种情况下我们需要判断一下该位置的元素和当前元素是否相等,使用equals来比较。
如果使用默认的规则是比较两个对象的地址。也就是两者需要是同一个对象才相等,当然我们也可以重写equals方法来实现我们自己的比较规则最常见的是通过比较属性值来判断是否相等。
如果两者相等则直接覆盖,如果不等则在原元素下面使用链表的结构存储该元素。
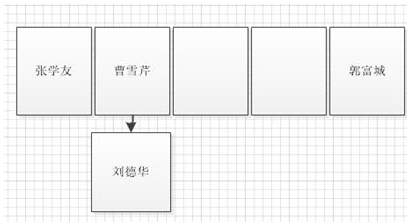
每个元素节点都有一个next属性指向下一个节点,这里由数组结构变成了数组+链表结构,红黑树又是怎么回事呢?
因为链表中元素太多的时候会影响查找效率,所以当链表的元素个数达到8的时候使用链表存储就转变成了使用红黑树存储,原因就是红黑树是平衡二叉树,在查找性能方面比链表要高.
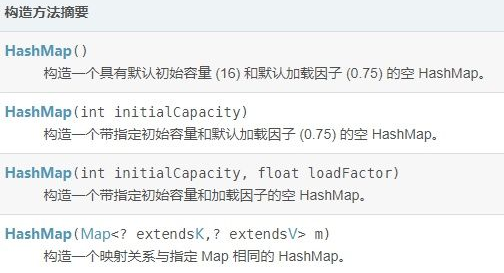
四:HashMap中的两个重要的参数
HashMap中有两个重要的参数:初始容量大小和加载因子,初始容量大小是创建时给数组分配的容量大小,默认值为16,用数组容量大小乘以加载因子得到一个值,一旦数组中存储的元素个数超过该值就会调用rehash方法将数组容量增加到原来的两倍,专业术语叫做扩容。在做扩容的时候会生成一个新的数组,原来的所有数据需要重新计算哈希码值重新分配到新的数组,所以扩容的操作非常消耗性能。
创建HashMap时我们可以通过合理的设置初始容量大小来达到尽量少的扩容的目的。加载因子也可以设置,但是除非特殊情况不建议设置。