Import SYS Import the codecs Import tensorflow TF AS # 1. parameters. # Reads the path of the checkpoint. 9000 represents the training program is stored in step 9000 checkpoint. = CHECKPOINT_PATH " F: \\ \\ attention_ckpt the TEMP-9000 " # model parameters. Must be consistent with the model parameters during training. 1024 = HIDDEN_SIZE # hidden layer of scale LSTM. = 2 DECODER_LAYERS # decoder LSTM structure layers. = 10000 SRC_VOCAB_SIZE # source language vocabulary size. 4000 = TRG_VOCAB_SIZE # target language vocabulary size. = True SHARE_EMB_AND_SOFTMAX #Sharing parameters between the word and the vector layer Softmax layer. # Glossary file SRC_VOCAB = " F: \\ \\ 201806-TensorFlowGoogle GitHub TensorFlowGoogleCode \\ \\ \\ en.vocab Chapter09 " TRG_VOCAB = " F: \\ \\ 201806-TensorFlowGoogle GitHub TensorFlowGoogleCode \\ \\ \\ Chapter09 zh.vocab " # vocabulary <sos> and <eos>'s ID. In the decoding process need <sos> input as a first step, and the check # whether <eos>, it is necessary to know the ID of two symbols. =. 1 SOS_ID EOS_ID = 2
# 2. NMT model definitions and decoding step. # Define NMTModel class to describe the model. class NMTModel (Object): # in the model initialization function defined in the model to use variables. DEF the __init__ (Self): # LSTM structure definition encoder and decoder is used. = self.enc_cell_fw tf.nn.rnn_cell.BasicLSTMCell (HIDDEN_SIZE) self.enc_cell_bw = tf.nn.rnn_cell.BasicLSTMCell (HIDDEN_SIZE) self.dec_cell = tf.nn.rnn_cell.MultiRNNCell ([tf.nn.rnn_cell.BasicLSTMCell (HIDDEN_SIZE ) for _ in the Range (DECODER_LAYERS)]) # source and target languages are defined word vector. = tf.get_variable self.src_embedding ( " src_emb", [SRC_VOCAB_SIZE, HIDDEN_SIZE]) self.trg_embedding = tf.get_variable("trg_emb", [TRG_VOCAB_SIZE, HIDDEN_SIZE]) # 定义softmax层的变量 if SHARE_EMB_AND_SOFTMAX: self.softmax_weight = tf.transpose(self.trg_embedding) else: self.softmax_weight = tf.get_variable("weight", [HIDDEN_SIZE, TRG_VOCAB_SIZE]) self.softmax_bias = tf.get_variable("softmax_bias", [TRG_VOCAB_SIZE]) def inference(self, src_input): # While input is only one sentence, but because dynamic_rnn asked to enter a batch of forms, so here # input finishing the sentence for the size of the batch 1. = tf.convert_to_tensor src_size ([len (src_input)], DTYPE = tf.int32) src_input = tf.convert_to_tensor ([src_input], DTYPE = tf.int32) src_emb = tf.nn.embedding_lookup (self.src_embedding, src_input) with tf.variable_scope ( " encoder " ): # use bidirectional_dynamic_rnn configured encoder. This step is the same as with the training. enc_outputs, enc_state = tf.nn.bidirectional_dynamic_rnn (self.enc_cell_fw, self.enc_cell_bw, src_emb, src_size, DTYPE = tf.float32) # The two outputs are combined into a LSTM tensor. = tf.concat enc_outputs ([enc_outputs [0], enc_outputs [. 1]], -1 ) with tf.variable_scope ( " Decoder " ): # define attentional mechanisms used by the decoder. = tf.contrib.seq2seq.BahdanauAttention attention_mechanism (HIDDEN_SIZE, enc_outputs, memory_sequence_length = src_size) # encapsulated self.dec_cell Recurrent Neural Networks and attention to the decoder with a higher level of Recurrent Neural Networks. = tf.contrib.seq2seq.AttentionWrapper attention_cell (self.dec_cell, attention_mechanism, attention_layer_size = HIDDEN_SIZE) # Set the maximum number of steps for decoding. This is to avoid problems with infinite loop in extreme cases. = 100 MAX_DEC_LEN with tf.variable_scope ( " Decoder / RNN / attention_wrapper" ): # Using a sentence of variable length stored TensorArray generated. Init_array = tf.TensorArray (DTYPE = tf.int32, size = 0, dynamic_size = True, clear_after_read = False) # fill the first word <sos> as the input to the decoder. init_array = init_array.write (0, SOS_ID) # call attention_cell.zero_state build the initial state of the cycle. circulation state comprising # hidden states loop neural network, save the resulting sentence TensorArray, and the recording-decoder # number of steps . an integer sTEP init_loop_var = (attention_cell.zero_state (= the batch_size. 1, DTYPE = tf.float32), init_array, 0) # cycling conditions of tf.while_loop: # loop until the output of the decoder <eos>, or the maximum number of steps so far. DEFcontinue_loop_condition (State, trg_ids, STEP): return tf.reduce_all (tf.logical_and (tf.not_equal (trg_ids.read (STEP), EOS_ID), tf.less (STEP,-MAX_DEC_LEN. 1 ))) DEF loop_body (State, trg_ids , the sTEP): # read the word last step output, and read it word vector. = trg_input [trg_ids.read (the STEP)] trg_emb = tf.nn.embedding_lookup (self.trg_embedding, trg_input) # call attention_cell computing step forward. dec_outputs, next_state = attention_cell.call (State = State, Inputs = trg_emb) # is calculated for each possible output word corresponding logit, logit and select the maximum value as word # This step is output. = tf.reshape Output (dec_outputs, [-1 , HIDDEN_SIZE]) logits = (tf.matmul (Output, self.softmax_weight) + self.softmax_bias) NEXT_ID = tf.argmax (logits, Axis =. 1, output_type = tf.int32 ) # trg_ids word saw this output state of the write cycle. = trg_ids.write trg_ids (+ STEP. 1 , NEXT_ID [0]) return next_state, trg_ids, STEP. 1 + # perform tf.while_loop, return to the final state. State, trg_ids, STEP = tf.while_loop (continue_loop_condition, loop_body, init_loop_var) return trg_ids.stack ()
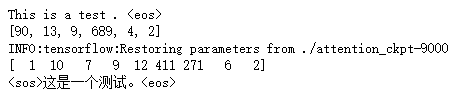
# 3. translate a test sentence. DEF main (): # recurrent neural network model used in the definition of training. tf.variable_scope with ( " nmt_model " , received Reuse Reuse = None): Model = NMTModel () # define test sentences. = test_en_text " This IS A Test. <EOS> " Print (test_en_text) # The English vocabulary, sentence into the test word ID. codecs.open with (SRC_VOCAB, " R & lt " , " UTF-. 8 " ) AS f_vocab: src_vocab = [w.strip () for W in f_vocab.readlines ()] src_id_dictDict = ((src_vocab [X], X) for X in Range (len (src_vocab))) test_en_ids = [(src_id_dict [token] IF token in src_id_dict the else src_id_dict [ ' <UNK> ' ]) for token in test_en_text.split ()] Print (test_en_ids) # establish FIG calculation required for decoding. = output_op model.inference (test_en_ids) sess = tf.Session () Saver = tf.train.Saver () saver.restore (sess, CHECKPOINT_PATH) # read the translation. = output_ids sess.run (output_op) Print (output_ids) # according to Chinese glossary, translating results into Chinese characters. codecs.open with (TRG_VOCAB, " R & lt " , " UTF-. 8 " ) AS f_vocab: trg_vocab = [w.strip () for W in f_vocab.readlines ()] output_text = '' .join ([trg_vocab [X] for the X- in output_ids]) # output translation. Print (output_text.encode ( ' UTF8 ' ) .decode (sys.stdout.encoding)) sess.close () IF the __name__ =="__main__": main()