https://bbs.huaweicloud.com/blogs/112956
PUMA team belongs to all, reproduced, please declare, thank you.
kakfa large-scale clustering capabilities previously had to share, kafka as a message bus, in clustering capabilities to support cloud ten million tps thousands of nodes is very good, the paper industry performance bottlenecks continue to point multi-topic issue on a stand-alone (for example: https :? //yq.aliyun.com/articles/62832 spm = 5176.100239.blogcont25379.8.KMUH1L), a domestic cloud use RocketMQ, performance inflection point when mouthing kafka 64 partition performance comparison, for which we refused to accept the theory the measured data, a step by step to uncover the secret of the so-called stand-alone performance inflection point and solution.
1 Introduction
This paper analyzes the number of Kafka partitioning support case, through a series of tests and analyzes need to confirm whether the number of partitions is limited, and find solutions.
Developers reader of this article contains a distributed message bus system, testers, and application of the system of customer product
Hardware constraints: Server 2285 2
Software Constraints: None
2 demand background
Why should expand the number of Kafka partition it? The following main points:
- The relationship between the number of partitions of parallel message queue, the message sent is sent to the partition, each consumer can only start a thread for each partition to obtain data. Therefore, to ensure that the partition is the maximum degree of parallelism in the message queue.
- Message Bus require multi-service access, each business must create their own Topic and partitions, there must be demand for the number of queues (queue number included Topic and partitions)
- IM terminal has a demand is made similar to a micro-channel and Want as a chat tool. If you do use the message bus, then the requirements of each user is assigned a message queue for the queue, so that at least hundreds of millions to support the message queue, the current message queue can not fully support.
- When the message queue as a public cloud service providers, we analyze each user can monopolize a queue (partition or Topic), the same number of partitions will bring requirements.
It is these needs and we will cause the number of partition as a metric MQ. At the same time, some analysts from the Internet, Kafka supports up to 64 partitions on performance decline so badly, in order to verify and solve the problem of the number of zoning restrictions, we have analyzed this document.
3 analysis
3.1 Principle Analysis
3.1.1 Basic Concepts
3.1.1.1 Partition
Partition is one of the most important concepts in Kafka, according to the message transmission and reception are processed in units of a partition.

Several major role in the partition of the following:
1, the number of concurrent writing proportional to the number of partitions Producer (message sender) of the message to Server.
2, Consumer (news consumers) consume a certain degree of parallelism with the number of partitions Topic consistent, assuming that the number of partitions is 20, then the maximum degree of parallelism Consumer consumption is 20.
3, each of the Topic by the number of partitions composed of a fixed number, the number of partitions determines how much Topic number of single Broker can support, Topic number and determines the number of operational support.
Simply put, the number of partitions, file read and write the corresponding number there, each partition Kafka corresponds to a file:
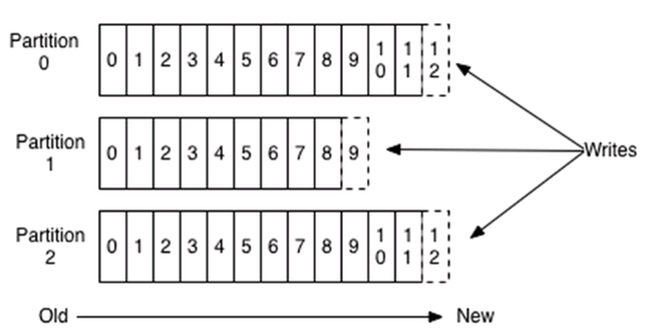
Each message is append to the Partition belonging to the order of writing to disk, so efficiency is very high, proven, sequential write disk memory efficiency is even higher than the random write, this is a very important guarantee for high-throughput Kafka.
3.1.1.2 Disk
When the message storage and caching, Kafka uses the file system.
Kafka's design is based on a very simple guiding principle: not to be stored in memory as much data when the data needs to be refreshed (flush) to the file system, but to do exactly the opposite. All data is immediately written to the log file system persistent but any call to refresh the data is not performed. Practical means to do so, the data is transferred to the OS kernel of the page cache, then sends the refreshed OS data to disk.
It was generally as "disk is very slow," so people are on persistent (persistent structure) structure can provide a plausible performance skeptical. In fact, compared with people's expectations, the disk can be said to be both slow and fast, depending on depending on the use of the disk. Design a good disk, and network structure can be as fast. In a RAID-5 disk array of six 7200rpm composed of SATA hard disks, write linear speed (linear write) is approximately 600MB / sec, but the random write is only 100k / sec, where the gap between the nearly 6,000 times.
Kafka was not created in memory buffer, and then to the disk write method, but uses the PageCache.
OS on read-write file system has done a lot of optimization, PageCache is one of the most important kind of method, a detailed description see chapter 3.1.2.
Directly PageCache has the following advantages:
1) reduce memory overhead: Java object memory overhead (overhead) is very large, often the target data storage memory occupied by more than twice.
2) Avoid GC problem: Java garbage collection in memory in the heap as growing data become increasingly clear, the cost of recycling spent will be growing.
3) Simple and reliable: OS will call all free memory as PageCache, and optimize on a lot: the pre-read-after-write, flush management, etc. These do not have to worry about the application layer, but is done automatically by the OS.
Because of these factors, the use of the file system and relies on PageCache page caching is better than their own to maintain a cache or something else structures in memory.
3.1.2 Analysis of reading and writing files
Kafka leveraging the Linux kernel Page Cache, no (explicit) with memory, with memory wins, there is no other home like you want while maintaining the data in memory, persistent worries of data - as long as enough memory, producers and consumers speed is not much difference on the reading and writing will take place in Page Cache in, there is no disk access synchronization.
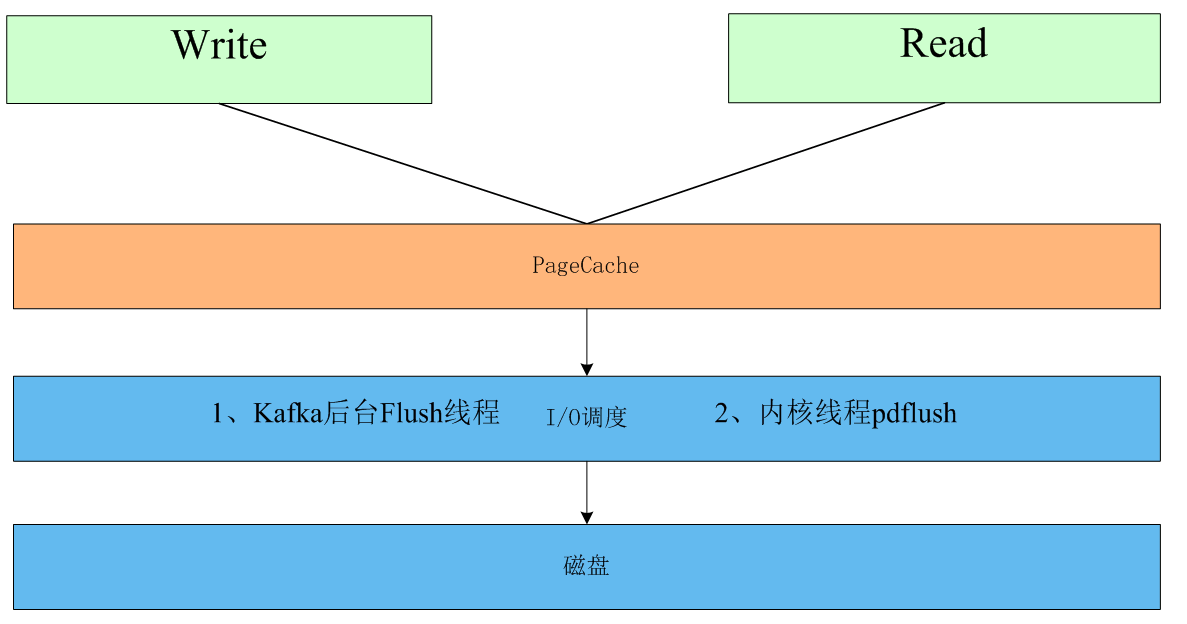
3.1.2.1 alley-oop to read and write
Linux has not always been the system memory used by the application to move to Page Cache, enter the command line free, or cat / proc / meminfo, "Cached" part is the Page Cache.
Page Cache中每个文件是一棵Radix树(基树),节点由4k大小的Page组成,可以通过文件的偏移量快速定位Page。
当写操作发生时,它只是将数据写入Page Cache中,并将该页置上dirty标志。
当读操作发生时,它会首先在Page Cache中查找内容,如果有就直接返回了,没有的话就会从磁盘读取文件再写回Page Cache。
可见,只要生产者与消费者的速度相差不大,消费者会直接读取之前生产者写入Page Cache的数据,大家在内存里完成接力,根本没有磁盘访问。
而比起在内存中维护一份消息数据的传统做法,这既不会重复浪费一倍的内存,Page Cache又不需要GC(可以放心使用大把内存了),而且即使Kafka重启了,Page Cache还依然在。
3.1.2.2 后台异步flush的策略
这是大家最需要关心的,因为不能及时flush的话,OS crash(不是应用crash) 可能引起数据丢失,Page Cache瞬间从朋友变魔鬼。
当然,Kafka不怕丢,因为它的持久性是靠replicate保证,重启后会从原来的replicate follower中拉缺失的数据。
内核线程pdflush负责将有dirty标记的页面,发送给IO调度层。内核会为每个磁盘起一条pdflush线程,每5秒(/proc/sys/vm/dirty_writeback_centisecs)唤醒一次,根据下面三个参数来决定行为:
- /proc/sys/vm/dirty_expire_centiseconds:如果page dirty的时间超过了30秒(单位是10ms),就
会被刷到磁盘,所以crash时最多丢30秒左右的数据。
- /proc/sys/vm/dirty_background_ratio:如果dirty page的总大小已经超过了10%的可用内存(cat
/proc/meminfo里 MemFree+ Cached - Mapped),则会在后台启动pdflush 线程写盘,但不影响
当前的write(2)操作。增减这个值是最主要的flush策略里调优手段。
- /proc/sys/vm/dirty_ratio:如果wrte(2)的速度太快,比pdflush还快,dirty page 迅速涨到 10%
的总内存(cat /proc/meminfo里的MemTotal),则此时所有应用的写操作都会被block,各自在自
己的时间片里去执行flush,因为操作系统认为现在已经来不及写盘了,如果crash会丢太多数据,
要让大家都冷静点。这个代价有点大,要尽量避免。在Redis2.8以前,Rewrite AOF就经常导致
这个大面积阻塞,现在已经改为Redis每32Mb先主动flush()一下了。
详细的文章可以看:http://www.westnet.com/~gsmith/content/linux-pdflush.htm
3.1.2.3 主动flush的方式
对于重要数据,应用需要自己触发flush保证写盘。
- 调用fsync() 和 fdatasync()
fsync(fd)将属于该文件描述符的所有dirty page的写入请求发送给IO调度层。
fsync()总是同时flush文件内容与文件元数据, 而fdatasync()只flush文件内容与后续操作必须
的文件元数据。元数据含时间戳,大小等,大小可能是后续操作必须,而时间戳就不是必须的。
因为文件的元数据保存在另一个地方,所以fsync()总是触发两次IO,性能要差一点。
- 打开文件时设置O_SYNC,O_DSYNC标志或O_DIRECT标志
O_SYNC、O_DSYNC标志表示每次write后要等到flush完成才返回,效果等同于write()后紧接一个fsync()或fdatasync(),不过按APUE里的测试,因为OS做了优化,性能会比自己调write() + fsync()好一点,但与只是write相比就慢很多了。O_DIRECT标志表示直接IO,完全跳过Page Cache。不过这也放弃了读文件时的Cache,必须每次读取磁盘文件。而且要求所有IO请求长度,偏移都必须是底层扇区大小的整数倍。所以使用直接IO的时候一定要在应用层做好Cache。
Kafka的默认机制中,fsync的间隔时间和消息个数都是最大值,所以基本上都是依赖OS层面的flush。
3.1.2.4 Page Cache的清理策略
当内存满了,就需要清理Page Cache,或把应用占的内存swap到文件去。有一个swappiness的参数(/proc/sys/vm/swappiness)决定是swap还是清理page cache,值在0到100之间,设为0表示尽量不要用swap,这也是很多优化指南让你做的事情,因为默认值居然是60,Linux认为Page Cache更重要。
Page Cache的清理策略是LRU的升级版。如果简单用LRU,一些新读出来的但可能只用一次的数据会占满了LRU的头端。因此将原来一条LRU队列拆成了两条,一条放新的Page,一条放已经访问过好几次的Page。Page刚访问时放在新LRU队列里,访问几轮了才升级到旧LRU队列(想想JVM Heap的新生代老生代)。清理时就从新LRU队列的尾端开始清理,直到清理出足够的内存。
Linux 提供了这样一个参数min_free_kbytes,用来确定系统开始回收内存的阀值,控制系统的空闲内存。值越高,内核越早开始回收内存,空闲内存越高。

3.1.2.5 预读策略
根据清理策略,Apache Kafka里如果消费者太慢,堆积了几十G的内容,Cache还是会被清理掉的。这时消费者就需要读盘了。
内核这里又有个动态自适应的预读策略,每次读请求会尝试预读更多的内容(反正都是一次读操作)。内核如果发现一个进程一直使用预读数据,就会增加预读窗口的大小,否则会关掉预读窗口。连续读的文件,明显适合预读。

3.1.2.6 调度层优化
IO调度层主要做两个事情,合并和排序。
合并是将相同和相邻扇区(每个512字节)的操作合并成一个,比如现在要读扇区1,2,3,那可以合并成一个读扇区1-3的操作。
排序就是将所有操作按扇区方向排成一个队列,让磁盘的磁头可以按顺序移动,有效减少了机械硬盘寻址这个最慢最慢的操作。
排序看上去很美,但可能造成严重的不公平,比如某个应用在相邻扇区狂写盘,其他应用就都干等在那了,pdflush还好等等没所谓,读请求都是同步的,耗在那会很惨。所有又有多种算法来解决这个问题,其中内核2.6的默认算法是CFQ(完全公正排队)。
3.1.3 原理分析结论
1、Kafka使用文件系统来交换消息,性能是否比使用内存来交换消息的系统要低很多?
在Apache Kafka里,消息的读写都发生在内存中(Pagecache),真正写盘的就是那条pdflush内核线程,根本不在Kafka的主流程中,读操作大多数会命中Pagecache,同时由于预读机制存在,所以性能非常好,从原理上有保证的。
2、 每个分区一个文件,那么多个分区会有多个文件同时读写,是否会极大的降低性能?
1) 首先,由于Kafka读写流程是发生在PageCache中,后台的flush不在主流程中触发,所以正常情况下理论上是没有影响的,除非PageCache占用内存过大,或是释放导致读写消耗Kafka进程的CPU时间。
2) 再次,文件都是顺序读写,OS层面有预读和后写机制,即使一台服务器上有多个Partition文件,经过合并和排序后都能获得很好的性能,不会出现文件多了变成随机读写的情况,但是当达到相当多的数量之后,也会存在一定的影响。
3) 当PageCache过大,大量触发磁盘I/O的时候,超过了/proc/sys/vm/dirty_ratio,Flush会占用各个应用自己的CPU时间,会对主流程产生影响,让主流程变慢。
3.2 性能测试
3.2.1 测试环境

同时启动消息发送和消费。

指标说明:
| TPS |
在客户端侧由代码统计的每秒发送和接收到的消息个数。 |
| wai |
系统因为io导致的进程wait。再深一点讲就是:这时候系统在做io,导致没有进程在干活,cpu在执行idle进程空转,所以说iowait的产生要满足两个条件,一是进程在等io,二是等io时没有进程可运行。 |
| %util |
使用iostat测试得到。Percentage of CPU time during which I/O requests were issued to the device (bandwidth utilization for the device). Device saturation occurs when this value is close to 100%。一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。 |
| IOPS |
该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。“一次传输”意思是“一次I/O请求”。多个逻辑请求可能会被合并为“一次I/O请求”。“一次传输”请求的大小是未知的。IOPS=reads+writes |
| reads |
在用例运行过程中,每秒读io的个数均值 |
| writes |
在用例运行过程中,每秒写io的个数均值 |
从流程来看,影响性能的几个主要点为:客户端,网络,服务器端CPU,内存,文件系统(磁盘)。
3.2.2 单硬盘测试
当系统只有一个硬盘的时候,所有的分区文件集中在一个磁盘上,测试数据如下:
从数据来看,cpu,内存,网络问题都不大。

随着分区数目的增加,吞吐量会下降。从图上来看,2000的分区下,生产者和消费者TPS下降幅度已经较大了。1000左右的分区TPS浮动不大。
备注:Consumer的TPS下降的原因,根据JProfile分析,主要是客户端问题,后面章节有专门分析。
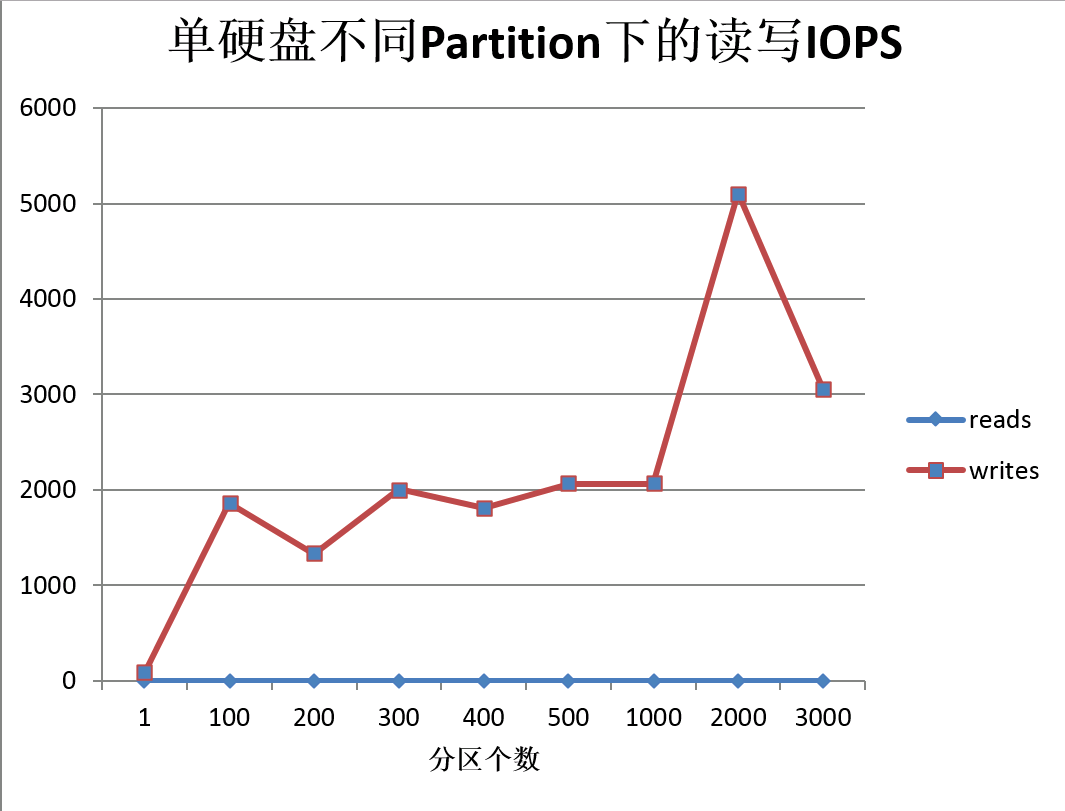
从磁盘的IOPS来看,超过1000之后,会急剧上升,3000之后因为TPS的下降,反而有所下降。
特别注意的是:读操作一直为0,证明基本上所有的Consumer消息都是从PageCache中获取的。
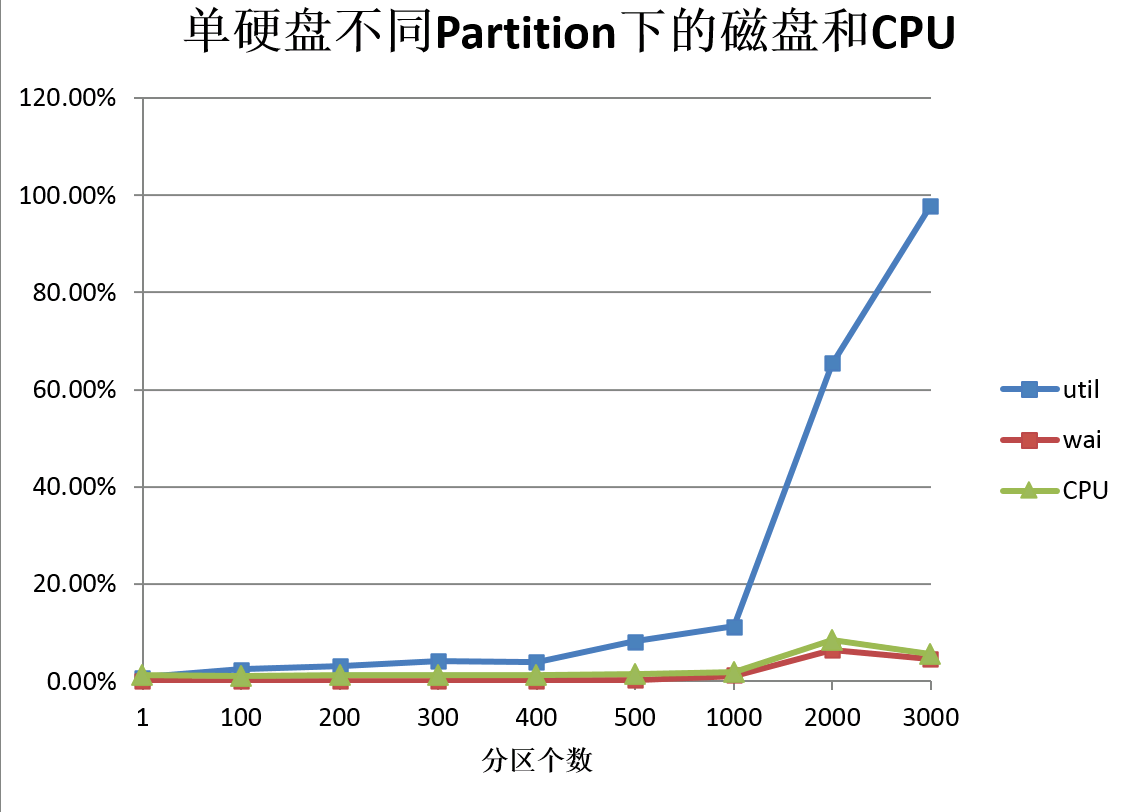
接下来,看一下util和wai,超过1000之后,util会急剧上升,到了3000左右,基本满负荷了。
这个和TPS是能对上的。
根据以上的测试数据,我们可以得到一个初步的结论:
1、 当分区超过了2000之后,util急剧上升,磁盘性能会成为瓶颈,导致Producer TPS下降。
2、 由于Read操作一直为0,证明磁盘对Consumer的影响不大。Consumer的TPS下降是客户端原因。(后面的章节给出证据)
建议:单台服务器单硬盘下,分区数量不超过2000,推荐值在1000以下。
3.2.3 多硬盘测试
启动8个磁盘,1个磁盘跑zookeeper和OS,其他7个磁盘分担所有的分区文件。
Util和IOPS是7个硬盘加起来的值,实际上每个硬盘的负荷是平均分担的。
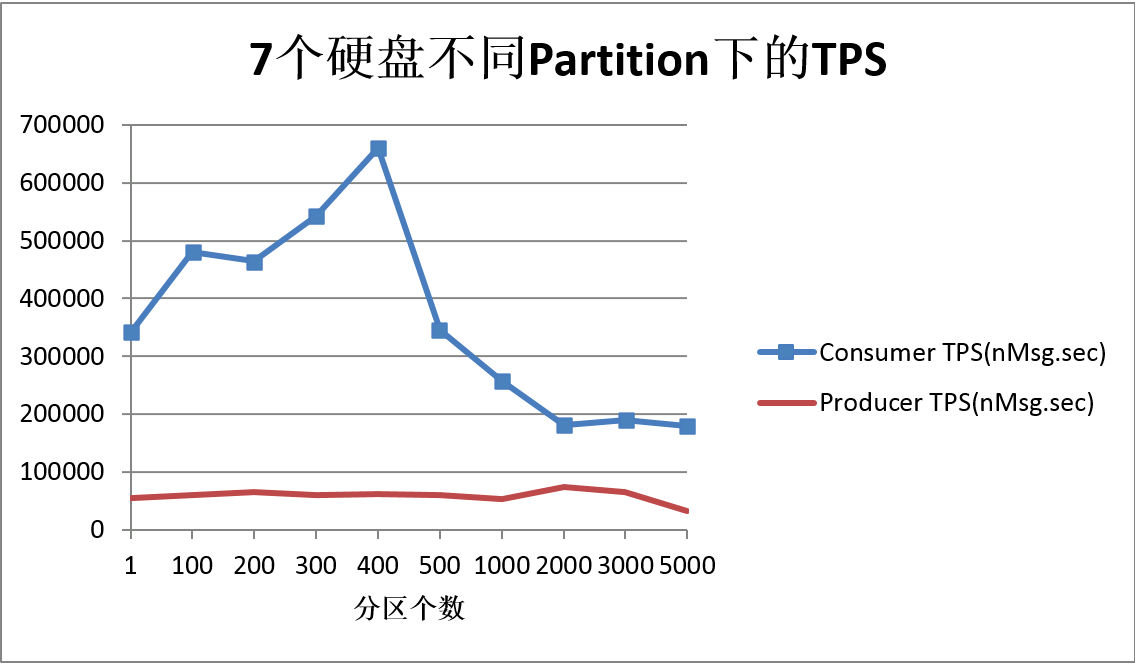
1、可以看到,3000分区下,Producer的TPS很平稳,实际上还要超过单硬盘下单分区的TPS。
证明追加硬盘的方法可以明显的提高TPS。
2、Consumer TPS,在多硬盘下其实和单硬盘是一致的,超过2000分区之后,一直都是18w左右。证明硬盘并不是Consumer的瓶颈。

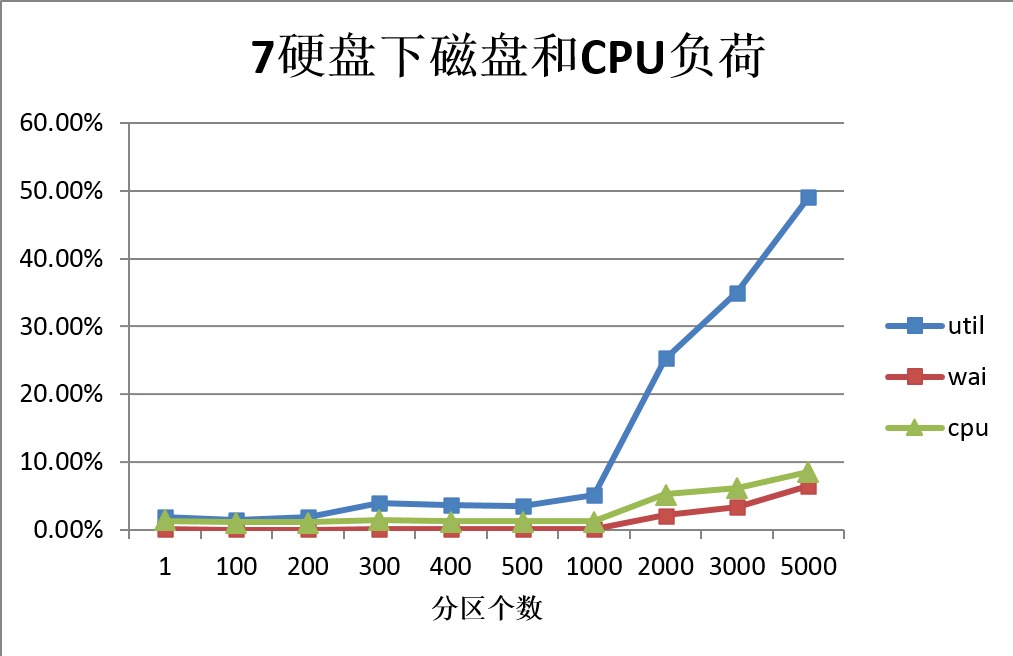
磁盘的IOPS和Util是随分区增加而增加的,但是实际上被7个硬盘平均分担,每个硬盘的负荷除以7之后很小了。
当分区达到5000之后,TPS会下降,但是磁盘负荷还远没有达到瓶颈。
CPU,网络,内存也同样没有问题。
3.2.4 客户端分析
3.2.4.1 Consumer客户端
Consumer客户端,使用的是Scala的客户端。
多硬盘,单分区下,JProfile如下:
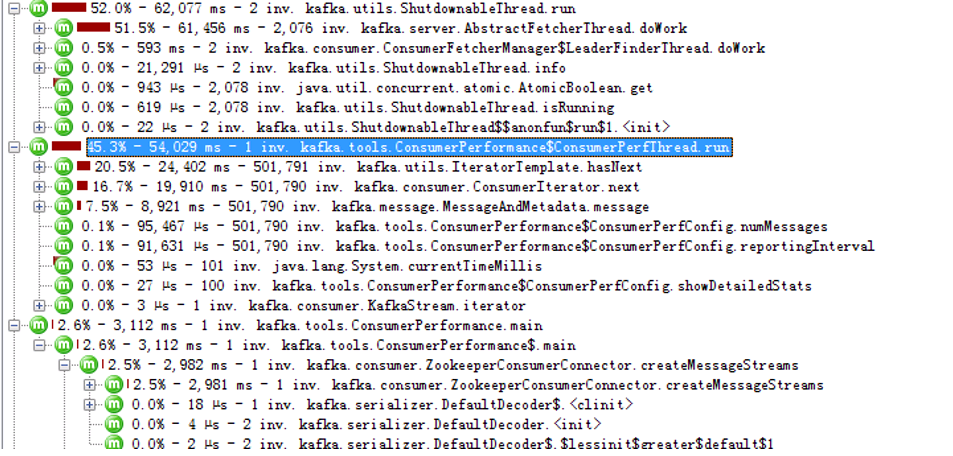
400分区如下:
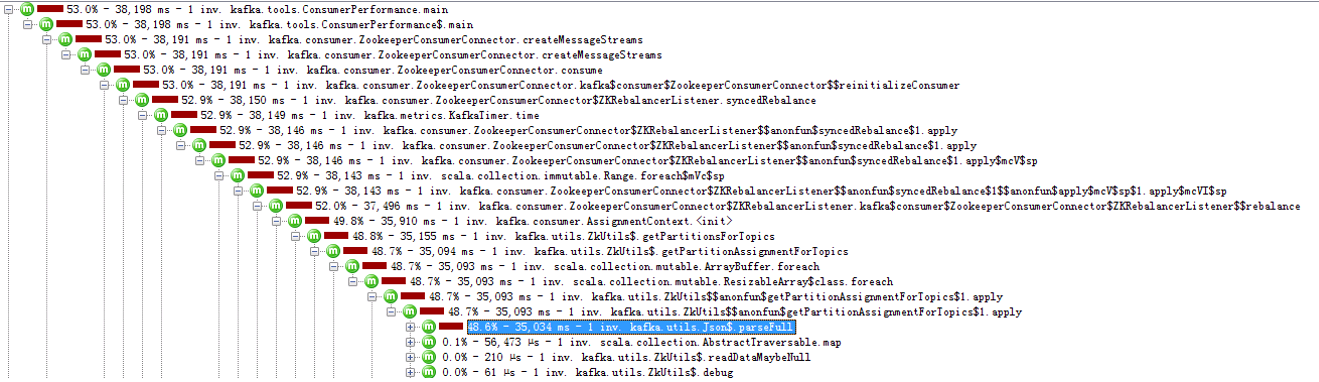
3000分区如下:
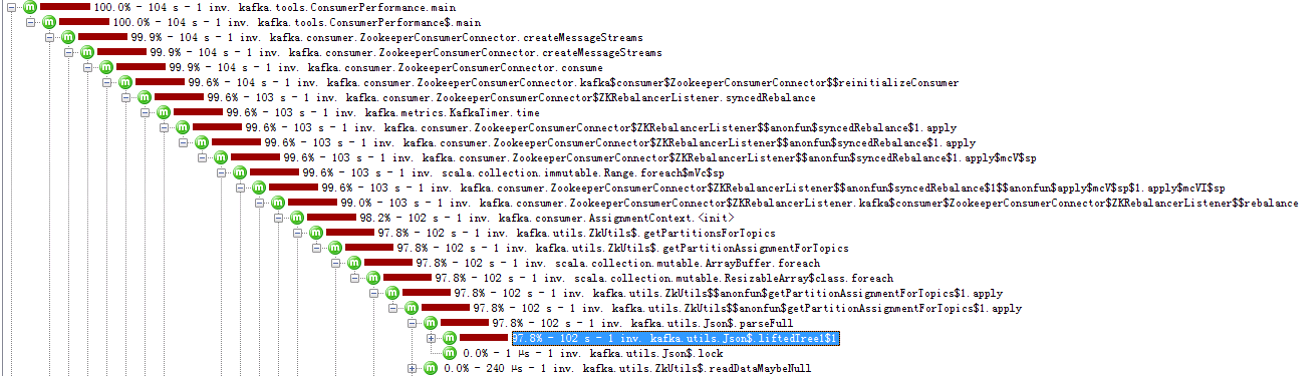
3000分区的时候,可以看到,97.8的cpu时间被用来执行了parseFull这个函数,这个函数是创建Streams的时候,对从zk获取的json文件进行解析,每次只执行一次。
但是由于分区越多,这个文件越大越复杂,导致执行时间非常长,影响了Consumer的TPS。
由于这个函数只执行一次,不会大量被执行,所以当Consumer运行时间越长,那么影响会越小。
3.2.4.2 Producer Scala客户端
最开始使用Scala客户端的测试,发现多分区下,大量的时间被消耗在日志打印参数的format函数上:
25分区:
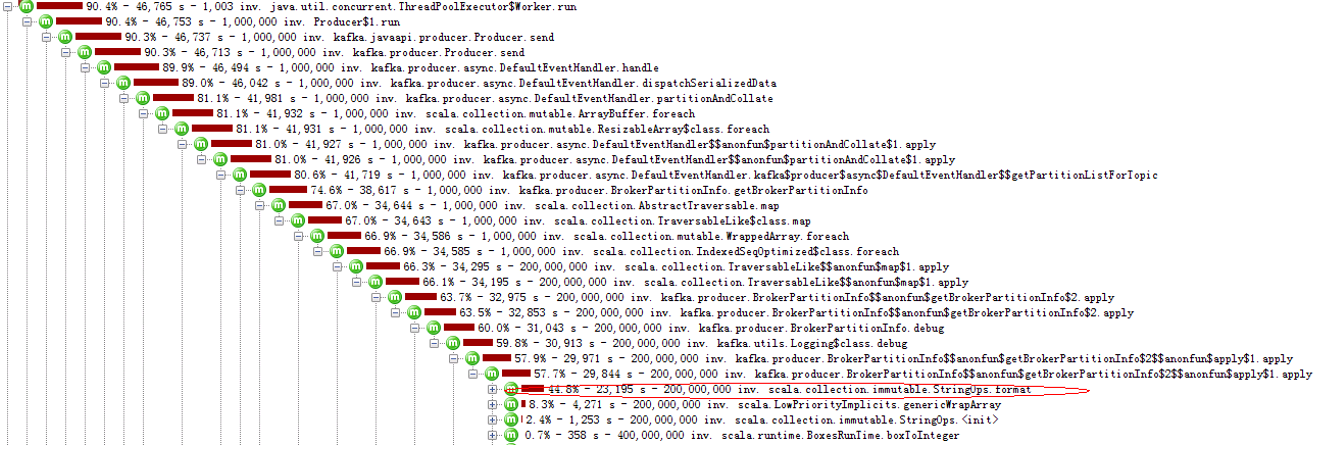
这里的代码,会在分个消息发送的时候,对分区的MAP循环执行如下的函数,这个代码里面会多次拼接字符串很耗时。
通过屏蔽日志打印函数,避免执行format,可以大大提升TPS:
partitionMetadata.map { m =>
m.leader match {
case Some(leader) =>
//debug("Partition [%s,%d] has leader %d".format(topic, m.partitionId, leader.id))
new PartitionAndLeader(topic, m.partitionId, Some(leader.id))
case None =>
//debug("Partition [%s,%d] does not have a leader yet".format(topic, m.partitionId))
new PartitionAndLeader(topic, m.partitionId, None)
}
}.sortWith((s, t) => s.partitionId < t.partitionId)
那两句debug信息打印注释掉,能大大的提升TPS。
估计还有其他的瓶颈点,之后我们将测试客户端切换到了java客户端。
3.2.4.3 Producer Java客户端
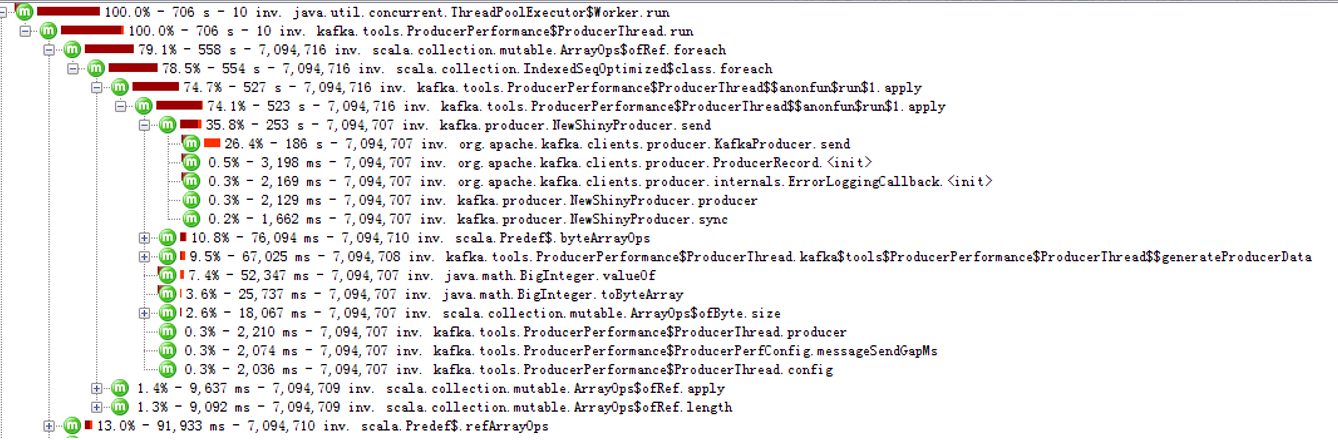
多硬盘一分区下,客户端的情况(ACK=1):
多硬盘5000分区下,Producer客户端(ACK=1):
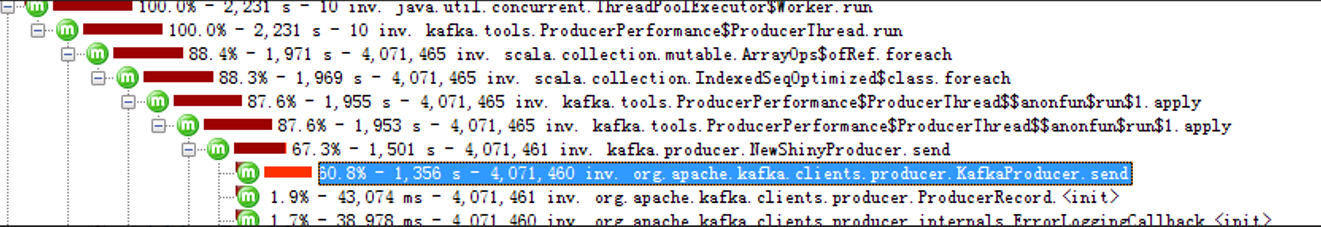
多硬盘5000分区下,Producer客户端(ACK=0)
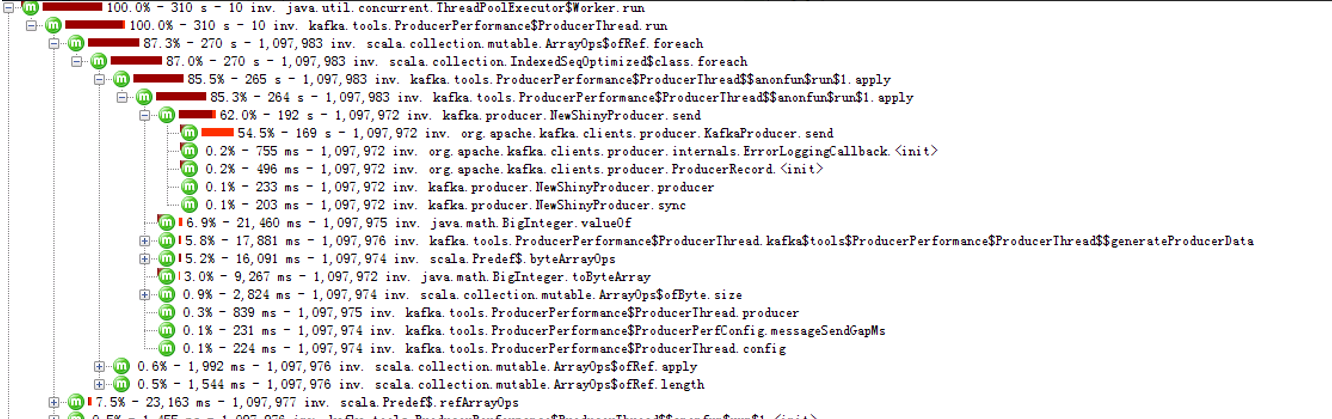
我们可以看到,分区数量越大,send函数耗时越长,5000分区下,耗时大半。
ACK=0的时候,客户端是不需要等待server的响应的,可以说基本上客户端的TPS和服务器端没有关系,但是,TPS照样降低,send照样消耗大量的时间。
所以,我们判断,多硬盘下,当分区达到5000以上的时候,瓶颈在客户端代码上,可以通过优化客户端代码来提升性能。
4 分析结论
4.1 结论
一、单Broker的分区,主要受以下几个方面的瓶颈限制:
1、 OS限制:Kafka代码中没有对分区做限制,但是分区数量受到OS的文件句柄的数量限制。可以用ulimit –a查看。需要调整该数目到一个较大的值。
2、 文件系统(磁盘刷盘):单硬盘下,磁盘IO和util会随着分区数目增大而增大,导致Kafka的性能会下降。
主要原因:
刷盘是一个很昂贵的操作,虽然OS提供了Group Commit和排序等优化机制,但是当分区数量太多之后,无法完全消除影响。每个分区写入是磁盘顺序写,但是多个分区同时顺序写入在操作系统层面变为了随机写入。
另外,当Pagecache的dirty数据达到一定限制之后,刷盘操作会阻塞应用的write操作,也会带来影响。
3、 客户端瓶颈:
通过追加硬盘可以解决单硬盘下的文件系统瓶颈。但是当达到5000以上,客户端会成为瓶颈。
这个是由于发送消息的时候需要获取Topic下的分区信息而产生的。
实际生产中,这个限制的影响应该不大,因为不会在1个Topic下划分太多的分区,而是会有多个Topic,每个Topic下有一些分区。测试的时候为了测试方便,采取了一种比较极端的测试方法(单个Topic下挂上数千的分区)。
当有需要的时候,也可以考虑优化。
建议分区数量:
1、单台服务器单硬盘下,推荐值1000,最好不超过2000。
2、单台服务器多硬盘下(7个),推荐值3000,最好不要超过5000。(当分区被分散到多个Topic的时候,这个值会更高,预计至少可以达到7000以上)。
二、集群(多节点)的分区限制:
理论上是随着节点增加而线性增加。但是实际还是受到Zookeeper的影响。节点最大支持数量估计在1w(zookeeper的限制)左右,那么整个集群分区的支持估计在百万左右(但是实际上受网络速度的影响,分区越大,存放在zookeeper的数据量越多等各种因素影响肯定会有个折扣)。
预计10w左右的分区支持问题不大。
1) 参考LinkedIn的Kafka集群部署规模:
http://www.slideshare.net/miguno/apache-kafka-08-basic-training-verisign

2) 在这篇文章中,提到曾经在单broker上使用了上万的分区。
http://www.confluent.io/blog/how-to-choose-the-number-of-topicspartitions-in-a-kafka-cluster/

4.2 社区意见参考
这里,kafka的committer有很明确的答复,基本上和我们验证的结果一致:
http://www.quora.com/How-many-topics-can-be-created-in-Apache-Kafka


有几个主要观点:
1、 Kafka的分区数量两个因素的影响:文件系统和zookeeper。
2、 实际应用中,分区数量不应该成为一个问题。分区的数量在实际中应该随着消费者数量扩展,不应该根据Data的特征来扩展。
4.3 解决方案
针对目前的几个瓶颈的解决方案如下:
1、 OS限制:通过调整Server的支持文件数目的句柄来解决。
2、 文件系统(磁盘刷盘):通过追加硬盘或追加Broker Node的方式来解决。
单个硬盘支持的分区数量推荐1000。多个硬盘:N*1000。
3、 客户端:当一个Topic下有过多的分区的时候(>3000),客户端预计会成为瓶颈。
如果有这种需求,可以考虑优化客户端来解决这里的瓶颈。
5 备注
5.1 参考资料
5.1.1 Cloudera配置Kafka的建议
http://blog.cloudera.com/blog/2015/07/deploying-apache-kafka-a-practical-faq/
非常好的实际经验。
http://blog.cloudera.com/blog/category/kafka/
是否应当为Kafka Broker使用 固态硬盘 (SSD)
实际上使用SSD盘并不能显著地改善 Kafka 的性能,主要有两个原因:
- Kafka写磁盘是异步的,不是同步的。就是说,除了启动、停止之外,Kafka的任何操作都不会去等待磁盘同步(sync)完成;而磁盘同步(syncs)总是在后台完成的。这就是为什么Kafka消息至少复制到三个副本是至关重要的,因为一旦单个副本崩溃,这个副本就会丢失数据无法同步写到磁盘。
- 每一个Kafka Partition被存储为一个串行的WAL(Write Ahead Log)日志文件。因此,除了极少数的数据查询,Kafka中的磁盘读写都是串行的。现代的操作系统已经对串行读写做了大量的优化工作。
如何对Kafka Broker上持久化的数据进行加密
目前,Kafka不提供任何机制对Broker上持久化的数据进行加密。用户可以自己对写入到Kafka的数据进行加密,即是,生产者(Producers)在写Kafka之前加密数据,消费者(Consumers)能解密收到的消息。这就要求生产者(Producers)把加密协议(protocols)和密钥(keys)分享给消费者(Consumers)。
另外一种选择,就是使用软件提供的文件系统级别的加密,例如Cloudera Navigator Encrypt。Cloudera Navigator Encrypt是Cloudera企业版(Cloudera Enterprise)的一部分,在应用程序和文件系统之间提供了一个透明的加密层。
Apache Zookeeper正成为Kafka集群的一个痛点(pain point),真的吗?
Kafka高级消费者(high-level consumer)的早期版本(0.8.1或更早)使用Zookeeper来维护读的偏移量(offsets,主要是Topic的每个Partition的读偏移量)。如果有大量生产者(consumers)同时从Kafka中读数据,对Kafka的读写负载可能就会超出它的容量,Zookeeper就变成一个瓶颈(bottleneck)。当然,这仅仅出现在一些很极端的案例中(extreme cases),即有成百上千个消费者(consumers)在使用同一个Zookeeper集群来管理偏移量(offset)。
不过,这个问题已经在Kafka当前的版本(0.8.2)中解决。从版本0.8.2开始,高级消费者(high-level consumer)能够使用Kafka自己来管理偏移量(offsets)。本质上讲,它使用一个单独的Kafka Topic来管理最近的读偏移量(read offsets),因此偏移量管理(offset management)不再要求Zookeeper必须存在。然后,用户将不得不面临选择是用Kafka还是Zookeeper来管理偏移量(offsets),由消费者(consumer)配置参数 offsets.storage 决定。
Cloudera强烈推荐使用Kafka来存储偏移量。当然,为了保证向后兼容性,你可以继续选择使用Zookeeper存储偏移量。(例如,你可能有一个监控平台需要从Zookeeper中读取偏移量信息。) 假如你不得不使用Zookeeper进行偏移量(offset)管理,我们推荐你为Kafka集群使用一个专用的Zookeeper集群。假如一个专用的Zookeeper集群仍然有性能瓶颈,你依然可以通过在Zookeeper节点上使用固态硬盘(SSD)来解决问题。
Kafka是否支持跨数据中心的可用性
Kafka跨数据中心可用性的推荐解决方案是使用MirrorMaker。在你的每一个数据中心都搭建一个Kafka集群,在Kafka集群之间使用MirrorMaker来完成近实时的数据复制。
使用MirrorMaker的架构模式是为每一个”逻辑”的topic在每一个数据中心创建一个topic:例如,在逻辑上你有一个”clicks”的topic,那么你实际上有”DC1.clicks”和“DC2.clicks”两个topic(DC1和DC2指得是你的数据中心)。DC1向DC1.clicks中写数据,DC2向DC2.clicks中写数据。MirrorMaker将复制所有的DC1 topics到DC2,并且复制所有的DC2 topics到DC1。现在每个DC上的应用程序都能够访问写入到两个DC的事件。这个应用程序能够合并信息和处理相应的冲突。
另一种更复杂的模式是在每一个DC都搭建本地和聚合Kafka集群。这个模式已经被Linkedin使用,Linkedin Kafka运维团队已经在 这篇Blog 中有详细的描述(参见“Tiers and Aggregation”)。
5.1.2 大数据领域的架构图
http://www.blogbus.com/navigating-logs/272257444.html
5.1.3 源代码High level分析
http://ju.outofmemory.cn/entry/124628
5.1.4 Kafka的配置推荐
http://bbs.chinacloud.cn/archiver/showtopic-29836.aspx
http://liyonghui160com.iteye.com/blog/2163899
5.1.5 Zookeeper的讨论
http://bbs.chinacloud.cn/archiver/showtopic-29836.aspx
重要的记录:
5.1.6 Kafka跨集群同步方案
http://jingyan.baidu.com/article/8065f87fea4d3a233124989f.html
http://tangzhaohui.net/post/524