Why BlueStore
First, Ceph original FileStore needs compatible with various file systems under Linux, such as EXT4, BtrFS, XFS. In theory each file system implement POSIX agreement, but in fact, every file system has little "not-so-standard" place. Ceph achieved great emphasis on reliability, and thus need introduce different Walkaround Hack or for each file system; e.g. Rename not idempotent, and the like. The work is a big burden for the continuous development of Ceph.
Secondly, FileStore and build on top of Linux file systems. POSIX provides a very powerful, but most Ceph is not really needed; these features has become a drag on performance. On the other hand, some features of the Ceph file system implementation is not friendly, for example, the directory traversal order requirements, and so on.
On the other hand, the problem is double the Ceph log. To ensure the override power failure midway able to recover, as well as support in order to achieve things within a single OSD, the FileStore write path, Ceph first modify the data and metadata written to the log, the log after, then the data is written to the actual off disc position. This method log (WAL) database and file system standards to ensure the ACID method. But with the Ceph here, poses a problem:
Data is written twice, that is, to write the log double issue, which means that half of the Ceph at the expense of disk throughput.
- Ceph's FileStore done it again log, and Linux file system also has its own logging mechanism, in fact, the log is do it again.
- For new LSM-Tree-based storage such as RocksDB, LevelDB, since log data is itself organized according to, in fact, no longer a single additional WAL necessary.
- Exhibit better performance SSD / NVM storage medium. And different disk, Flash-based storage higher parallelism, need to be utilized. CPU processing speed is not progressively stored, thus requiring better use of multi-core parallel. Extensive use of storage queues, etc., easily lead to time-consuming complicated by competition, but also need to optimize. On the other hand, RocksDB there is good support for SSD and so on, it is BlueStore adopted.
In addition, the community had to FileStore the issue, with LevelDB for storage backend; convert KeyValue object store to store, instead of converting their files. Later, LevelDB store is not to promote open, mainstream or use FileStore. But the idea is the standing KeyValue, BlueStore RocksDB is used to store the metadata.
BlueStore overall architecture
Born bluestore is to solve their own filestore maintain a journal and also to write the file system need to zoom in on the problem, and filestore itself is not optimized for SSD, so bluestore compared to the filestore mainly do two core business areas:
- Remove journal, directly manage raw device
- For individually optimized SSD
bluestore overall structure as shown below:
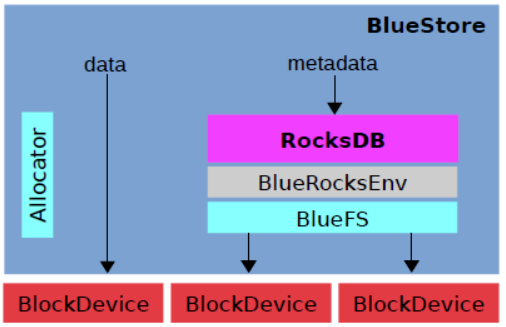
Achieved by Allocator (dispenser) management of the bare device, saves the data directly to the device; for the metadata using the same time save RocksDB, encapsulates the underlying self BlueFS for a docking apparatus and the bare RocksDB.
Module division
Core Module
- RocksDB: memory write-ahead log data object metadata, omap Ceph data, and metadata distributor ( distributor is responsible for determining the actual data to be stored somewhere )
- BlueRocksEnv: interactive interface with RocksDB
- BlueFS: small file system to address metadata, file space allocation and management and disk space, and realized rocksdb :: Env Interface (sst and storage RocksDB log files). Because rocksdb routine is run in the top of the file system, the following is BlueFS. It backend data storage layer, RocksDB BlueStore data and the real data block are stored in the same physical device
- BlockDevice (HDD / SSD): The actual physical data block devices, storage
rocksdb itself is based on the file system, not directly manipulate raw device. It associated processing system abstracted Env, the user can implement an interface. BlueRocksEnv is a class bluestore implemented inherits from rocksdb :: EnvWrapper, to provide a packaging system for the underlying rocksdb.
For interfacing BlueRocksEnv, to achieve a small file system BlueFS, implement only the interface rocksdb Env needed. All changes are recorded in the metadata BlueFS log, that is, for persistent BlueFS, metadata stored in the log. At system startup mount the file system, just log replay, we can all metadata are loaded into memory. BluesFS data and log files are saved to the bare block device through the device (BlueFS and BlueStore can share a raw device, can specify different device, respectively).
bluestore no local file system, taking over the bare device, using only one raw partition physical block devices HDD / SSD resides direct naked device I / O operations using linux aio in user mode. Since the operating system supports aio supported only directIO, so write to the BlockDevice written directly to disk, and need to be aligned in accordance with the page. There is a aio_thread its internal thread, used to check whether aio completed. After its completion, inform the caller via the callback function aio_callback.
Allocator module
Which is used to assign specific blocks of real memory used to store the current data object; bitmap using the same way to achieve the allocator, while using hierarchical level index to store a plurality of states, in this manner the memory consumption is relatively small, the average disk needs to 1TB probably ram space around 35M.
BlueStore module
Before storage engine filestore, the form of the object corresponding to the file system in the file, the default file size of 4MB, but in bluestore there has been no traditional file system, but to manage their own bare disc, thus the need for yuan data management object, is the corresponding Onode, Onode is a memory-resident data structures, persistence time will be saved to rocksdb in the form of kv.
The most commonly used memory write path BlueStore should be as short as possible, as simple as possible, so as to have the best performance, as soon as another exception processing path can be very complex. BlueStore design has the following features:
- Ceph is not required POSIX file system. Abandon it, try to implement a simple file system, dedicated to RocksDB use. This file system, called BlueFS
- Metadata stored in RocksDB in a positive manner KeyValue suitable. System does not require the data file, can be stored directly on raw block devices. What we need on a block device, in fact, it is a space divider (Allocator).
Another point, BlueStore different components can use different devices. E.g. RocksDB WAL files to configure NVRAM, a file with SST SSD, the data file with HDD, the program is flexible.
BlueStore metadata management
Before turning to writing path, take a look at how Ceph BlueStore manage metadata. The first question is how the object data structure is mapped to the disk ( the bottom is Ceph object storage, package storage block upwardly, file storage )?
Onode representing an object, the name is probably from the Linux VFS Inode followed them there. Onode permanent memory, in RocksDB to KeyValue form of persistence;
Onode comprising a plurality lextent, i.e. logic extent. Blob by mapping pextent, i.e. physical extent, mapped onto the physical area on the disk. Blob usually includes a plurality of pieces of data from the same object, but other objects may be referenced. Bnode after the object snapshot, a plurality of objects are used to share data. (Do not understand)
BlueStore write path
Write path includes the handling of affairs, but also answer how to solve BlueStore log double the problem.
First, Ceph transaction works only within a single OSD, multiple objects to ensure operations are performed ACID is mainly used to implement its advanced features. (Together Placement Group, similar to the Dynamo vnode, the hash maps to the same object within the group to a group) has a OpSequencer each PG, the PG sequential operation performed by the guarantee it. Things you need to write three categories:
(1) written to the newly allocated area. ACID consideration, because this write not overwrite existing data, even half-way off, because the metadata RocksDB not updated, do not worry ACID semantics are destroyed. Later visible metadata updates RocksDB after the data is written to do. Thus, the log is not required. After the data is written, the metadata updates are written RocksDB; RocksDB itself support transactions, metadata updates as RocksDB affairs submit.
(2) written to a new location in the Blob. Similarly, the log is not required.
(3) Deferred Writes (delayed write), only for overwriting (Overwrite) case. Can also be seen from the above, only you need to consider the override log problem. If the new write block size ratio (min_alloc_size) is smaller, which will then merge data and metadata written to the RocksDB, asynchronously after data move down the actual disk position; this is the log. If the new block is larger than the size of the write, then it is divided, one-piece part of the newly allocated block, the writing, i.e. by (1) treatment; insufficient press section (3) in the case treated.
Above the basic outlines of the writing process BlueStore. I can see how it is to solve the FileStore log double the problem.
First of all, there is no Linux file system, and there will be no extra Journaling of Journal issues. Then, most of the writing is written to a new location, but not overwritten, so they do not need to use the log; writing still occurs twice, the first time that data off the disk, and then is RocksDB transaction commits, but is no longer needed data contained in the log. Finally, incorporated into a small override log submitted, once finished to return to the user, the data move asynchronously after the actual position (small data into the log, which is common technique); large overwrite is divided piece portion treatment with Append-only mode, it bypasses the need for logs. At this point, it becomes a natural and normal treatment.
BlueFS architecture
BlueFS to design as simple as possible for the purpose, specifically to support RocksDB; RocksDB short or need a file system to work. BlueFS does not support the POSIX interface. Overall, it has these characteristics:
(1) the directory structure, BlueFS flat directory structure only, there is no hierarchical relationship tree; RocksDB for placing the db.wal /, db /, db.slow / file. These files can be mounted onto a different hard drive, e.g. db.wal / on NVMRAM; db / SST comprising thermal data on the SSD; db.slow / on disk.
(2) Data is written terms, BlueFS does not support the override, only support additional (Append-only). Block allocation coarse grain size, about 1MB. There are periodic garbage collection process is wasted space.
(3) Operation of the metadata recorded in the log, the log replay mount each time, to obtain the current metadata. Survival metadata in memory, and does not persist on the disk, such as a free block list need not be stored and the like. When the log is too large, it will be rewritten Compact.
If you ask why BlueStore more than doubled compared to FileStore can improve throughput, it may be more simple, more short write path; solve the problem of dual write, most of the data is no longer required to write it again in the log; borrow RocksDB treatment metadata, which implements the maturation of SSD optimizer good.
to sum up
BlueStore OSD biggest feature is directly manage raw disk devices, and the object data stored in the device. In addition there are many objects KV attribute information, before such information is in the extended attributes of a file or LevelDB among storage. In BlueStore, the information is stored in among RocksDB. RocksDB itself is required to run on the file system, and therefore in order to use the metadata storage RocksDB need to develop a simple file system (BlueFS).
BlueStore from design and implementation point of view, it can be understood as a file system under the user mode, while using RocksDB BlueStore to manage all the metadata, to simplify the implementation.
For the entire written data, the data is written directly to disk aio way, and then update the metadata RocksDB data objects, avoiding the first to write a log filestore after apply to twice the actual disk write disk. While avoiding redundant storage occupancy log metadata, because traditional file systems have their own internal logging and metadata management mechanism.
BlueStore actually implements a file system user mode. In order to achieve simple and uses RocksDB to implement all of the metadata BlueStore management, simplifying the implementation.
Advantages:
For the entire written data, the data is written directly to disk AIO way to avoid the first to write a log filestore after apply to twice the actual disk write disk.
For the IO random form, the WAL direct, direct write performance RocksDB KV store.