Web crawler (also known as web spider, web robot, in the middle of FOAF community, more often called web Chaser), in accordance with a certain rule, the program automatically crawl the World Wide Web information or script
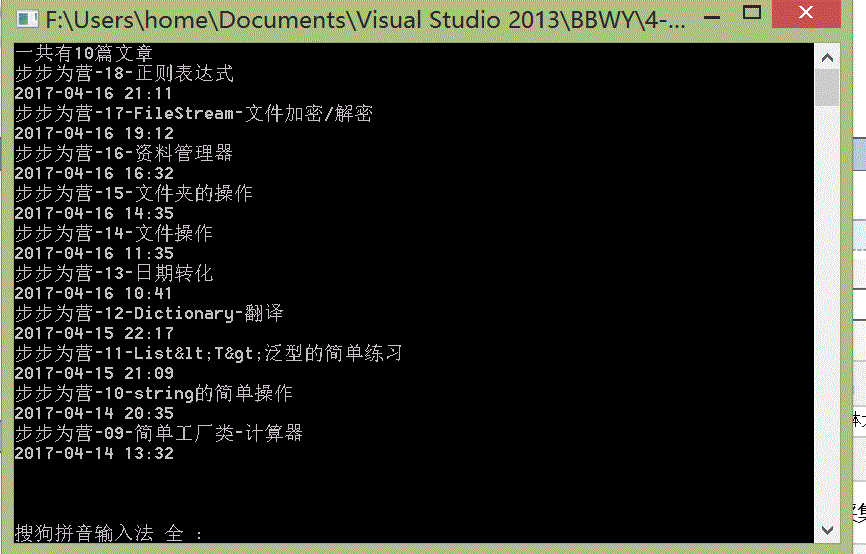
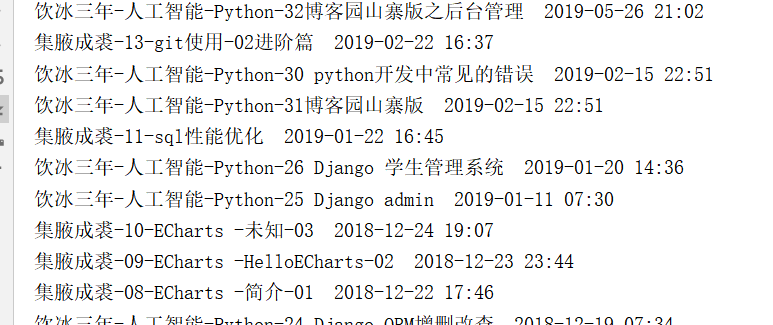
Example 1: a long time ago, with C # regular expressions wrote a small function, it is to get the number of your own written blog and title and writing time, and now we use this python to achieve this function again
https://www.cnblogs.com/YK2012/p/6722402.html


import requests from bs4 import BeautifulSoup for i in range(1,20): response = requests.get(url='http://www.cnblogs.com/YK2012/default.html?page='+str(i)) response.encoding = response.apparent_encoding soup = BeautifulSoup(response.text,features="html.parser") target = soup.find_all(name='div', attrs={"class":'day'}) for entity in target: title = entity.find('a','postTitle2') desc = entity.find('div', 'postDesc') print(title.text.strip(),desc.text[10:27])
The central idea: to get the URL, get requests, analyze data
Example Two: Automatically login GitHub, and project information
import requests from bs4 import BeautifulSoup import lxml from bs4.element import Tag # 1:访问登录页面,获取authenticity_token i1 = requests.get("https://github.com/login") soup1 = BeautifulSoup(i1.text, features='lxml') token = soup1.find(name='input', attrs={'name': 'authenticity_token'}) authenticity_token = token.get('value ' ) ga_id = soup1.find (attrs = { ' name ' : ' octolytics-Dimension-ga_id ' }) C1 = i1.cookies.get_dict () i1.close () # Print (' token ', authenticity_token) Print (C1) # 2 remove the token password and user name, user authentication sent form_data = { " authenticity_token " : authenticity_token, " UTF8 " : "" , " the commit " : " Sign in " , "login": "[email protected]", 'password': '90opl;./()OPL:>?', 'ga_id': '470285644.1573810874', 'webauthn-support': ' supported', 'webauthn-iuvpaa-support': ' unsupported', 'required_field_3d5b': '', 'timestamp': ' 1573811914069 ' , ' timestamp_secret ' : ' 2787f62a778139ef3be7fdea96b5f867e9e08b8976ecc07bb4869748d930cabd ' } I2 = requests.post ( ' https://github.com/session ' , Data = form_data, Cookies = C1) C2 = i2.cookies.get_dict () C1. Update (c2) Print ( ' If nothing else, so that the login is successful! ' ) i3 = requests.get ( ' https://github.com/settings/repositories ' , Cookies = c1) soup3= BeautifulSoup(i3.text, features='lxml') list_group = soup3.find(name='div', class_='js-collaborated-repos') for child in list_group.children: if isinstance(child, Tag): project_tag = child.find(name='a', class_='mr-1') size_tag = child.find(name='span',class_='text-small') temp = " Project:% s (% s); path item:% S " % (project_tag.get ( ' the href ' .), Size_tag.get_text () Strip () [0:. 8 ] .strip (), project_tag.string ,) Print (the TEMP)
GitHub charade: time you log in passing the token.
