To teach the basic concepts of decision tree, the principle of classification and regression trees, tree represents the ability of decision tree training algorithm to find the best split of principle, mark the leaf nodes of the value of the property and lack of alternative split decision tree pruning algorithms, decision trees.
Very intuitive and easy to understand machine learning algorithms, in line with most people's intuitive thinking, because a lot of time to make decisions in life is to do with this decision tree structure.
Outline:
The basic concepts of
classification and regression tree
training algorithm
to find the best split
attribute the lack of alternative division
overfitting pruning and
experimental aspects of
practical application
basic concepts:
① tree is a hierarchical data structure, genealogy, the book is a directory tree structure.
② tree is a recursive structure, each child node of the tree, with its root is also a tree, so that many algorithms inside the tree is to use recursion to achieve.
There is a special tree called a binary tree, only a maximum of two children nodes left child node and the right child node, it is easy to implement programming each node in the tree when the programming is to use pointers to achieve, non-binary reserved how much storage space the child node pointer of well established, so the programming is generally used when a binary tree.
Non-leaf node, called the decision node, the leaf node is the result of the decision. Decision tree can be used for classification, it can also be used for return.
For example, a doctor may also use a decision tree to determine, the decision tree is a tree rule when he studied and summarized many years of experience, it is that some physical feature vector of indicators, such as body temperature, the number of white blood cells, red blood cell count and many more.
The entire machine learning and pattern recognition inside features two types, one is categorical characteristics, is not comparable size, such as whether there is real estate license, and second numerical characteristics are comparable size, such as how much income.
Decision Tree entire decision process is starting from the root, in order to get a feature comparison, the daily life of this decision rule is artificial summed up, the decision tree is a machine learning algorithm, and this artificial decision is fundamentally different, While the tree is determined, which is obtained through training, given a set of samples ((X . 1 , Y . 1 ), (X 2 , Y 2 ), ...), a set of rules that automatically learn to do prediction, Videos rectangular internal node Videos oval leaf node.
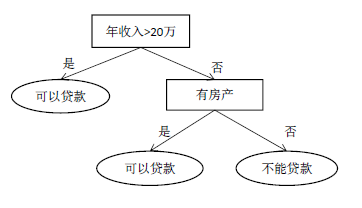
Rule-based decision tree is a method of prediction using a nested set of rules, at decision node into a branch based on the determination result, this operation is repeated until reaching the leaf node obtained prediction result. These rules are obtained through training, rather than artificially developed.
Decision node: at these nodes require a judgment to determine which branch enters, as compared with a feature set and a threshold value. Decision node must have two children, it is an internal node.
Leaf node: represent the final result of the decision, no child nodes. For classification problems, the leaf node is stored in the category label.
Classification and Regression Trees:
A decision tree is a hierarchical structure, it can be given a number of levels for each node. Number of the root node is level 0, the number of levels of hierarchy parent child node number plus one. The depth of the tree is defined as the maximum number of levels of all nodes, the number of levels also expressed the need for the number of comparisons.
Typically there is a decision tree ID3, C4.5, CART (Classification and Regression Tree, classification and regression trees), etc., which differ (training algorithm tree) structure (binary or multi-tree) tree construction algorithm with tree after a good training, predictive algorithms are the same, namely the determination results from root to leaf nodes.
CART classification and regression tree is a binary tree, supports both classification problems, can also be used for regression problems. ID3, C4.5 is a very old machine learning algorithm of.
Mapping function is piecewise linear classification tree partitioning the multidimensional space, i.e. parallel with the hyperplane space be segmented to each axis: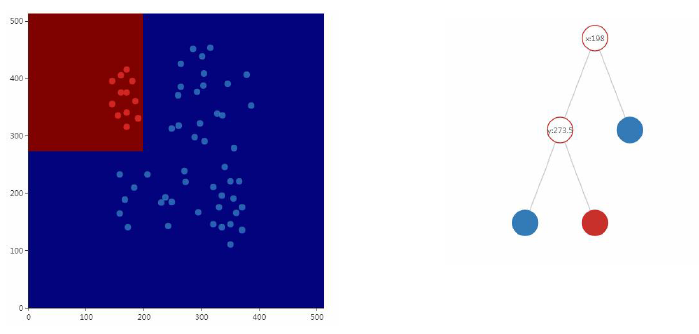
Regression tree mapping function is a piecewise constant function (segment score simple function is piecewise constant function, takes a constant value within a certain range), the decision tree is a piecewise linear function rather than a linear function having a non-linear modeling capabilities.
As long as the divided fine enough, piecewise constant function can be any function to approximate any given closed interval accuracy, a decision tree can be fit to the data of arbitrary complexity theoretically. The very fine spatial points, as the integral calculus as a constant value in between is replaced with a cell with a step function is a continuous function in place of any of the specified precision can be achieved, as long as sufficient finely divided on it, that is a decision tree can be fit to the data of arbitrary complexity in theory. In theory very good, implement unsatisfactory, will face the curse of dimensionality, high spatial dimension of time points is very small, then the back would be too fit, generalization performance would drop dramatically, although theoretically possible, but the actual operation when accuracy is not high.
For classification problems, as long as there is not the same place two samples, tree deep enough, then it can divide repeatedly put all the training sample set the correct classification. For classification problems, if the depth of the decision tree is large enough, it can all samples correctly classified training sample set.
Training algorithm:
Prediction Algorithm: starting from the root, repeated determination rule stored inside the tree nodes, decided to enter the left or right subtree subtree until you reach the leaf node to obtain the predicted results. The core issue is how this tree set up? Is obtained through training, training is based (for a supervised machine learning algorithms, it is based on common error on the training set is minimized), that is to say, let the decision tree training samples are as correct as possible classification, then the tree is a good tree.
Decision tree training depends on which question: is a recursive tree structure, the tree is recursive established. First is how to establish the root, root, find a split rule with all sample training (training time is called splitting rule, when the forecast called decision rules), the sample set into two, and then use the first subset the train left the decision tree, the second sub-set of training the right decision tree, so that you can create a tree out, this is a recursive structure.
There are several issues:
① each decision node which component should choose to do judgment? This determination will be a training sample set into two, and then about two subsets configured subtrees.
② determine what the rules are? Into the left sub-tree branch when that is what the conditions are met. For numeric variables to look for a split judgment threshold, below the threshold into the left sub-tree, or into the right subtree. For categorical variables it is necessary to determine a subset division, the value of the feature set is divided into two disjoint subsets, wherein if the value belongs to the first subset proceeds left subtree, or into the right sub tree.
③ when to stop dividing, the leaf node to node? For classification problems, stop when the node samples are of the same type; for regression problems, if the node takes its training samples are the same value, then it instead of all the samples with this value, there is no error, stop dividing. However, this may result in excessive node of the tree, the depth is too large, over-fitting problems. To prevent over-fitting, one approach is to stop dividing nodes when the number of samples is less than a threshold value, and the other is when the tree reaches a specified depth is not allowed to grow up.
④ how to give the category labels or return value for each leaf node? When the sample is divided into categories which reaches a leaf node or imparting i.e. what real values.
A total of several issues, one is a recursive division, the core is how to find an optimal splinter, is in training after a sample set by dividing let out of the tree to create a set of samples classified as possible will return. The second is when to stop dividing. Third, set the value for the number of suitable leaf node. A total of leaf nodes, internal nodes in both cases, the overall depth and some other tree control, which constitute the core of decision tree algorithm training.
Recursive splitting process
1. The sample set used to establish a root node, a decision rule to find the set of samples D split into two portions D1 and D2, while the root node is set decision rule
2. Recursive established sample set D1 left subtree
3. sample set D2 recursive establish the right subtree
4. If you can no longer divide, put the node labeled leaf node, as well as its assignment, the training process in this step would cease, and then go back to train other nodes
Find the best division: