First, the working principle analysis
Second, the performance optimization
1 , the degree of parallelism in the process of setting Shuffle: spark.sql.shuffle.partitions (SQLContext.setConf ()) 2 , the Hive data warehouse construction process, a reasonable set of data types, such as can be set to INT, do not set BIGINT. Reduce unnecessary memory overhead caused by data type. 3 , when writing SQL, try to give a clear column names, such as name the SELECT from Students. Do not write select * way. 4 , parallel processing of query results: the results Spark SQL query, if a large amount of data, such as more than 1000, then do not disposable collect () Driver to reprocessing. Using the foreach () operator, parallel processing of the query results. 5 , cache table: For a SQL statement that may be used more than once to the table, can be cached, use SQLContext.cacheTable (tableName), or DataFrame.cache () can be. Spark SQL will cache table column with memory storage format. Then Spark SQL columns can be scanned only need to use, and automatically optimize compression, to minimize memory usage and overhead GC. SQLContext.uncacheTable (tableName) may be removed from the cache table. With SQLContext.setConf (), provided spark.sql.inMemoryColumnarStorage.batchSize parameters (default 10000), may be configured to store the unit column. 6, Broadcast join table: spark.sql.autoBroadcastJoinThreshold, default 10485760 ( 10 MB). In the case of enough memory can be increased in size, it takes up when a parameter table of the join, the maximum is within what can be broadcast to optimize performance. 7 , tungsten plan: spark.sql.tungsten.enabled, default is true, automatic memory management. The most effective, in fact, the fourth point, cache table and join the broadcast table is also very good!
三、hive on spark
Hive On Spark Background:
sparkSQL and the Saprk ON Hive:
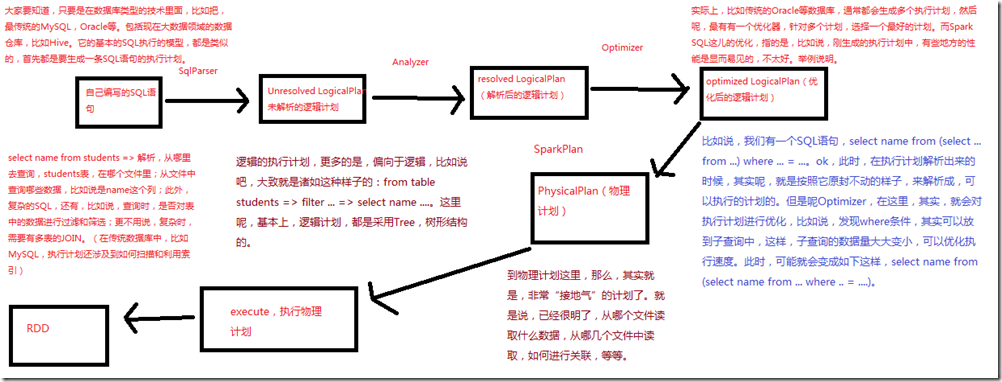
Hive is the big data field, the de facto standard SQL. The default is based on the underlying MapReduce implementation, but because MapReduce speed is relatively slow, so this year, after another out of the new SQL query engine.
Including Spark SQL, Hive On Tez, Hive On Spark and so on.
Spark SQL and Hive On Spark is not the same. Spark Spark SQL is developed out of their own for a variety of data sources, including Hive, JSON, Parquet, JDBC, RDD and so can execute the query,
a calculation based on Spark engine query engine. So it is a project of Spark, but provides a work function to execute a query against the Hive it. Spark suitable for use in the use of some large data application technology stack class System.
The Hive On Spark, is a project of the Hive, it means, not through MapReduce as a single query engine, but the Spark as the underlying query engine. Hive On Spark, applies only to Hive.
In the foreseeable future, likely to default Hive underlying MapReduce engine is switched from the Spark. It adapted to the original Hive data warehousing and statistical analysis Replace Spark engine, as a large company-wide statistical data analysis engine.
First look at the Hive basic principle:
Hive QL statement =>
parse => AST =>
generation logic execution plan => Operator Tree =>
optimized logic implementation plan => Optimized Operator Tree =>
generate physical implementation plan => Task Tree =>
To optimize the physical execution plan => Optimized the Task Tree =>
Optimized the Task Tree performing the optimization
calculation principle Hive On Spark has the following points:
1, the Hive Spark RDD table as to operate: this is no doubt
2, Hive primitive
for some operations for RDD, such as groupByKey, sortByKey and so on. Spark does not use the transformation operations and primitives. If you do, then that, then you need to re-implement a set of primitive Hive,
and if Hive adds new features, then have to implement the new Spark primitives. So choose Hive primitive packaging operation can be for the RDD.
3, new physical execution plan generation mechanism
using SparkCompiler logic implementation plan, namely Operator Tree, converted to Task Tree. Spark Task submitted for execution to the Spark. SparkTask packed DAG, DAG packaging SparkWork.
SparkTask calculated DAG SparkWork representation.
4, SparkContext life cycle
Hive On Spark will provide each user's session, such as the implementation of a SQL statement, create a SparkContext. But Spark is not allowed to create multiple SparkContext within a JVM.
Accordingly, it is necessary to start SparkContext each session in a separate JVM, which then communicates with a remote RPC by the JVM SparkContext.
5, local and remote operation mode
Hive On Spark offers two modes of operation, local and remote. If the Spark Master is set to local, such as set spark.master = local, so is the local mode,
SparkContext with the client running in a JVM. Otherwise, if the Spark Master is set to address the Master, then that remote mode, SparkContext starts in a remote JVM.
In remote mode, each user creates a Session SparkClient, SparkClient start RemoteDriver, RemoteDriver responsible for creating SparkContext.
Hive On Spark do some optimization:
1, the Map the Join
the Spark to join is the default SQL support the use of broadcast mechanism to broadcast to a small table on each node to perform the join. But the problem is that this will give a great deal of Worker Driver and memory overhead.
Because broadcast data to remain in Driver memory. So now take is, it seems like the MapReduce Distributed Cache mechanism, namely to improve the HDFS replica factor of replication factors,
to make the data has a backup on each compute node, so that data can be read locally.
2, Cache Table
for some scenes need to perform multiple operations on a table inside the Hive On Spark optimized, cache table about to multiple operations into memory, in order to improve performance. But the point to note here,
is not carried out automatically cache all cases will be. So, Hive On Spark There are many imperfections.
hive on spark environment to build
1、安装包apache-hive-1.2.1-bin.tar.gz 2、在/usr/local目录下解压缩 3、进入conf目录,mv hive-default.xml.template hive-site.xml,修改hive-site.xml <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://spark1:3306/hive_metadata_2?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse2</value> </property> 4、在conf目录下 mv hive-env.sh.template hive-env.sh vi ./bin/hive-config.sh export JAVA_HOME=/usr/java/latest export HIVE_HOME=/usr/local/apache-hive-1.2.1-bin export HADOOP_HOME=/usr/local/hadoop 5、cp /usr/share/java/mysql-connector-java-5.1.17.jar /usr/local/apache-hive-1.2.1-bin/lib 6、MySQL create database if not exists hive_metadata_2; grant all privileges on hive_metadata_2.* to 'hive'@'%' identified by 'hive'; grant all privileges on hive_metadata_2.* to 'hive'@'localhost' identified by 'hive'; grant all privileges on hive_metadata_2.* to ' Hive ' @ ' spark1 ' IDENTIFIED by ' Hive ' ; the flush privileges; . 7 , starting hive cli, / hive, error, Relative path. In Absolute the URI: $ {System: the java.io.tmpdir% 7D / $% 7Bsystem: % the user.name 7D create a folder: / Home / Grid / hive--Apache 1.2 . . 1 - bin / iotmp the Hive -site.xml all $ {system: java.io.tmpdir} to the above directory, It is recommended to use WinSCP hive-site.xml copy to the windows up, notepad ++ with this tool, to replace the text, more convenient. 8 , starting hive cli,. / Hive, continue error, Found class jline.Terminal, But interfaceexpected WAS CP / usr / local / hive--Apache 1.2 . . 1 -bin / lib / jline- 2.12 .jar / usr / local / hadoop / Share / hadoop / Yarn / lib the original old hadoop JLine - 0.9 . 94 .jar , rename or delete 9 , starting CLI Hive, / usr / local / hive--Apache 1.2 . . 1 -bin / bin / Hive, starts successfully used: Create Table Students. (name String , Age int ); Load the inpath local Data ' / usr / local / Spark-Study / Resources / students.txt ' INTO Students. Table; // use very simple Hive On Spark @Just set Hive execution engine with spark can set hive.execution.engine command // default is mr set hive.execution.engine = spark; // here, is completely set it to the URL Spark Master of the set = the Spark spark.master: // 192.168.1.107:7077 the SELECT * from Students;
Reproduced in: 46, the Spark SQL profiling and performance optimization works