One, reptiles
Defined Web Crawler: Automatically crawl program information on the Internet or script
(A) reptiles can solve the problem
- Cold start problem solving
- Basic search engine
- Build knowledge map, help build machine learning knowledge maps
- You can produce a variety of goods parity software, trend analysis
Second, Spoken reptiles sum 聚焦 Reptilia
The usage scenario, the web crawler and crawler focusing divided into general crawler.
(One)-class Reptilia
search engine
- The main components of a search engine
General reptiles: After crawling down the entire internet page, save it locally. (Did not do data cleaning)
common reptiles crawling pages in order, we need to url of the site, but the search engine can search for all pages. So common reptiles url will involve all pages.
How search engines get url:- Submit URL to the new site search engine initiative
- Set up a new site outside the chain on other sites (in the range of search engines as possible)
- Search engines and DNS resolution service providers (such as DNSPod etc.) cooperation, the new domain will be quickly crawl.
- All engines workflow:
- Step one: crawl pages
- It was added to a common crawler by url to be crawling queue url, content for web crawling.
- Step Two: Data storage:
- Save the Web page crawling down to the local. This process there will be some de-emphasis operation. If the contents of a page most repeated, search engines may not be saved.
- The third step: Pretreatment
- Extract the text
- Chinese word
- Eliminate noise (such as copyright notice text, navigation, ads, etc.)
- Index processing
- Step four: Set your site's ranking, provide for the use of search services (PageRank value)
- Step one: crawl pages
- Search engine limitations:
- Search engines can only crawl original page, but the page content is 90% useless.
- Search engines can not meet the different industries, the specific needs of different people.
- General reptiles crawling text messages only, for additional information videos, documents, audio, pictures, etc. can not be crawled.
- Only keyword-based query, not based on semantic query.
(B) focusing crawler
Focused Crawler: will the content filtering process in the implementation of web crawling, crawling and try to ensure that only information relevant to the needs of the page.
Second, reptiles preparations
(A) robots protocol
robots protocol: crawler exclusion criteria.
Role: tell the search engines can crawl that content, which can not climb
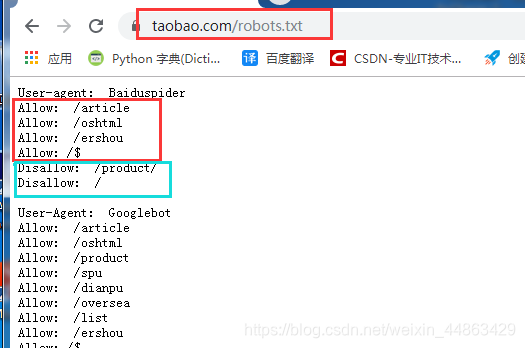
(B) Site Map sitmap
What's in the next site map, you can view the page
https://help.bj.cn/
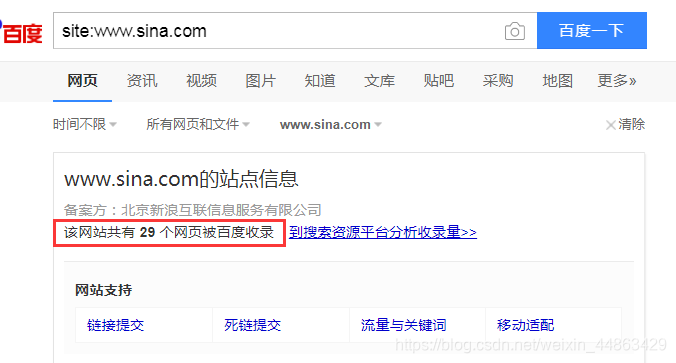
(C) the estimated size of the site
Use a search engine, Baidu in using the site: domain name
(D) identify the site using what technology
installation
pip install builtwith
在python的交互模式下输入:
import builtwith
builtwith.parse('http://www.maoyan.com')
(E) need to know who is the owner of the site
安装python-whois:pip install python-whois
在python交互模式下输入:
import whois
whois.whois('http://www.sina.com.cn')
Three, http and https
(A) What is the http protocol?
http: hypertext transfer protocol
Constraint specification was released and receive html page
https: http security office, adding ssl layer at http
(B) the number of the port
http port 80
https port number is 443
Characteristics (III) http protocol
- Application layer protocol
- Connectionless: each request is independent
- http 1.1 adds a connection: keep-alive, the head of said connecting clients and servers is a long connection
- Stateless: each time the client can not request a recording request status. I.e. no communication between two requests.
- cookie and session state can help record
(D) url: Uniform Resource Locator
Why you can locate any resource on the Internet through the url?
http://ip:port/path
-
ip: Positioning Computer
-
port: Port number - to enter the computer from the Internet
-
path: the path to find the corresponding resource in the computer
# There are three special symbols
-? Request parameter
& - & connection with the request parameters- Anchor: At the request url, specify the location of the page jump anchor
-
基本格式:
scheme://host[:port#]/path/…/[?query-string][#anchor]
scheme:协议(例如:http, https, ftp)- host:服务器的IP地址或者域名
- port:服务器的端口(如果是走协议默认端口,缺省端口80)
- path:访问资源的路径
- query-string:参数,发送给http服务器的数据
- anchor:锚(跳转到网页的指定锚点位置)
在python中,有一个模块可以帮助我们解析url。
代码:
from urllib import parse
url = 'http://localhost.com:8080/index.htmusername="zhangsan"&password="123"'
print(parse.urlparse(url))
输入内容:
ParseResult(
scheme='http',
netloc='localhost.com:8080',
path='/index.htm',
params='',
query='',
fragment='')
(五)http工作过程
1.地址解析,将url解析出对应的内容:
scheme:协议(例如:http, https, ftp)
host:服务器的IP地址或者域名
port:服务器的端口(如果是走协议默认端口,缺省端口80)
path:访问资源的路径
query-string:参数,发送给http服务器的数据
anchor:锚(跳转到网页的指定锚点位置)
2.封装http请求数据包
3.封装成TCP包,建立TCP连接(TCP的三次握手)
- TCP握手协议
- 第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
SYN:同步序列编号(Synchronize Sequence Numbers) - 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
- 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据
- 第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
4.客户端发送请求
5.服务器发送响应
6.服务器关闭TCP连接
(六)当在浏览器输入一个url,为什么可以加载出一个页面?
为什么在抓包的过程中,请求了一个url,会出现很多的自愿请求
- 当我们在浏览器输入一个url,客户端会发送这个url对应的一个请求到制定服务器获取内容;
- 服务器收到这个请求,解析出对应的内容,之后将内容封装到响应里面发送给客户端;
比如index.html页面 - 当客户端拿到这个html页面,会查看这个页面中是否有css、js、image等url,如果有,在分别进行请求,获取到这些资源;
- 客户端会通过html的语法,将获取到的所有内容完美的显示出来。
(七)客户端请求
- 组成:请求行、请求头部、空行、请求数据四个部分组成
- 请求方法get/post
- get方法:
get,通过服务器上请求参数来获取资源,?后面是请求参数,用&拼接,不安全,传输参数大小受限 - post请求:
post,向服务器传递封装在请求实体里的数据,可以传递更多内容,安全 - get和post的区别:
- get是从服务器获取内容,post是向服务器传递内容
- get不安全,因为参数拼接在url后面。post比较安全,因为参数是放在实体里
- get传参他笑受限,post不受限
- get方法:
- 重要的请求头:
- User-Agent:客户端请求标识
- Accept:(传输文件类型)允许传入的文件类型
- Referer:表名产生请求的网页来自于哪个url,用户是从该Referer页面访问到当前请求的页面
- cookie (cookie):在做登录的时候需要封装这个头
- Content-Type (POST数据类型)
- 发送POST请求时,需要特别注意headers的一些属性:
- Content-Length: 144; 是指发送的表单数据长度为144,也就是字符个数是144个
- X-Requested-With:XMLhttpReauest; 表示ajax异步请求
(八)服务响应
- 组成:状态行,响应头,空行,响应正文。
- 重要响应头:
- Content-Type: text/html; charset = UTF-8; 告诉客户端,资源文件的类型,还有字符编码
- 状态码:
- 100 ~ 199: the server indicates successful reception section request to the client to continue to submit a request to complete the remaining process
- 200 ~ 299: denotes server successfully received the request and has completed the entire process. Common 200 (OK request was successful)
- 300 to 399: In order to complete the request, customers need to further refine the request. For example: requested resource has been moved to a new address, commonly 302 (requested page has been transferred to a new temporary url), 307 and 304 (cache resources)
- 400 to 499: the client's request for errors, common 404 (server can not find the page requested), 403 (server refuses access, access is not enough -DDos)
- 500 ~ 599: the server error occurs, commonly 500 (request was not completed server encounters unforeseen circumstances.)