Use Scrapy grab e-books
Reptile ideas
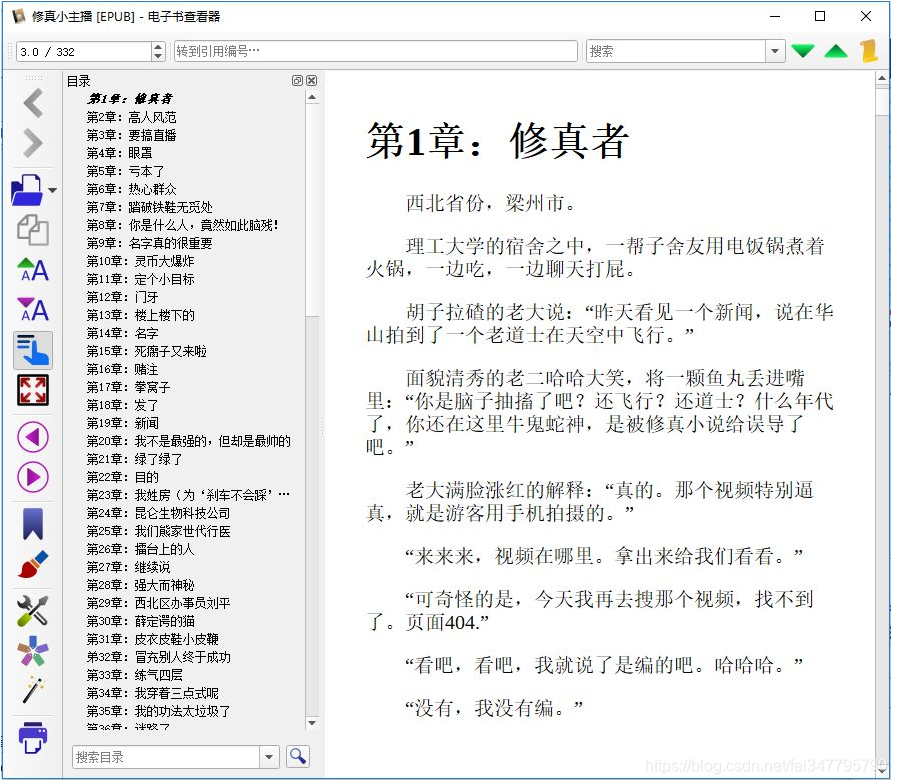
How to fetch data, we first look at where to take to open the "little comprehension anchor" of the page, as follows:
there is a directory tab, click on the tab to see the directory, using the element browser viewing tool, we can locate catalog and related information of each chapter, based on the information that we can crawl to a specific page:
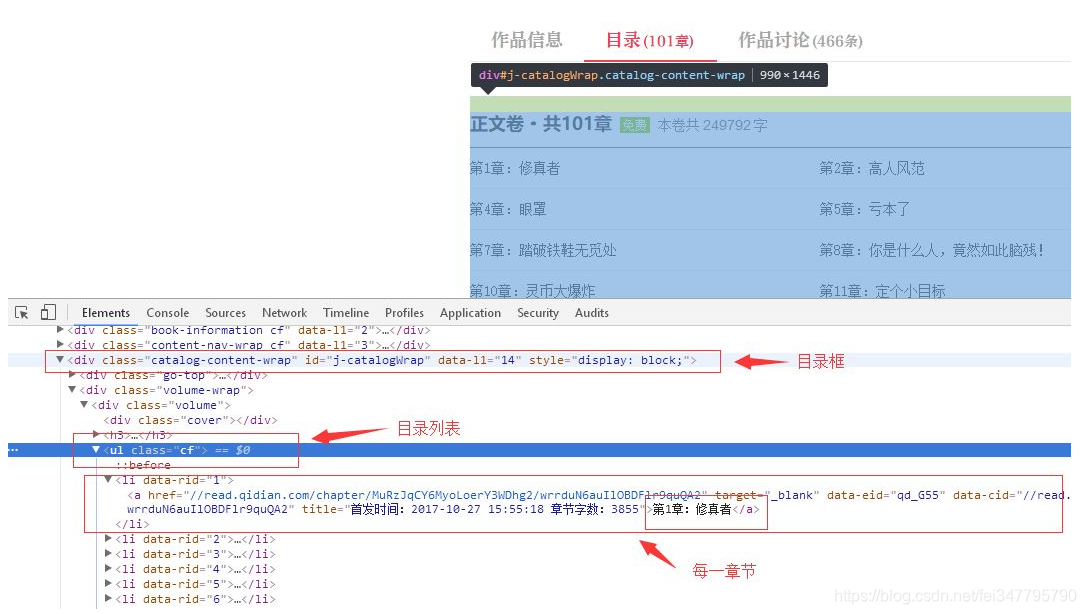
obtaining chapter address
Now we open xzxzb.py file is reptiles we just created:
# -*- coding: utf-8 -*-
import scrapy
'''
更多Python学习资料以及源码教程资料,可以在群821460695 免费获取
'''
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['http://qidian.com/']
def parse(self, response):
pass
start_urls is the directory address, crawler will automatically crawl the address, then the result is processed in the following parse. Now we have to write code to handle directory data, the first climb of the novel take home, get a directory listing:
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
pass
DOM data acquisition pages, there are two ways, one is to use CSS selectors, another is the use of XML xPath query.
Here we use xPath, knowledge of your own learning, look at the code above, we first get through the directory box ID, get a class cf get a directory listing:
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
Next, traversing a child node, and the li tag href attribute query a child node, the final print:
for page in pages:
url = page.xpath('./child::a/attribute::href').extract()
print url
In this way, we can say crawling chapter path of the small reptile was written, use the following command to run xzxzb reptiles see the results:
scrapy crawl xzxzb
This time our program might look like this error:
…
ImportError: No module named win32api
…
You can run the following statement:
pip install pypiwin32
Screen output is as follows:
> ...
> [u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/wrrduN6auIlOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Jh-J5usgyW62uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5YXHdBvg1ImaGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/fw5EBeKat-76ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/KsFh5VutI6PwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/-mpKJ01gPp1p4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MlZSeYOQxSPM5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/5TXZqGvLi-3M5j8_3RRvhw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/sysD-JPiugv4p8iEw--PPw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/xGckZ01j64-aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/72lHOJcgmedOBDFlr9quQA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/cZkHZEYnPl22uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/vkNh45O3JsRMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ge4m8RjJyPH6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Y33PuxrKT4dp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/MDQznkrkiyXwrjbX3WA1AA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/A2r-YTzWCYj6ItTi_ILQ7A2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Ng9CuONRKei2uJcMpdsVgA2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/Q_AxWAge14pMs5iq0oQwLQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/ZJshvAu8TVVp4rPq4Fd4KQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/hYD2P4c5UB2aGfXRMrUjdw2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/muxiWf_jpqTgn4SMoDUcDQ2']
[u'//read.qidian.com/chapter/MuRzJqCY6MyoLoerY3WDhg2/OQQ5jbADJjVp4rPq4Fd4KQ2']
> ...
Crawling chapter path of the small reptile was written, but our aim is not only to this, we are going to use these addresses to crawl content:
Chapter page analysis
我们接下来分析一下章节页面,从章节页面我们要获取标题和内容。
如果说章节信息爬取使用的 parser 方法,那么我们可以给每一个章节内容的爬取写一个方法,比如:parser_chapter,先看看章节页面的具体情况:
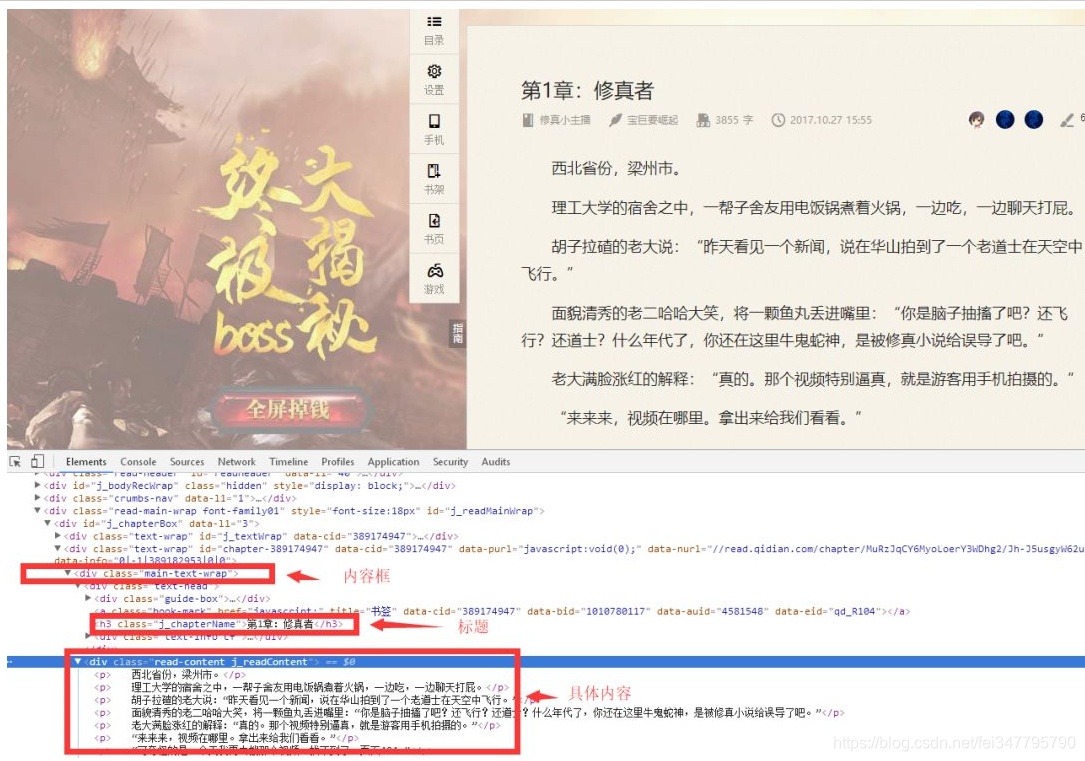
可以看到,章节的整个内容在类名为 main-text-wrap 的 div 标签内,标题是其中类名为j_chapterName的 h3 标签,具体内容是类名为read-content j_readContent的 div 标签。
试着把这些内容打印出来:
# -*- coding: utf-8 -*-
import scrapy
class XzxzbSpider(scrapy.Spider):
name = 'xzxzb'
allowed_domains = ['qidian.com']
start_urls = ['https://book.qidian.com/info/1010780117/']
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
yield response.follow(url, callback=self.parse_chapter)
pass
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
print title
# print content
pass
上一步,我们获取到了一个章节地址,从输出内容来看是相对路径,因此我们使用了yield response.follow(url, callback=self.parse_chapter),第二个参数是一个回调函数,用来处理章节页面,爬取到章节页面后我们解析页面和标题保存到文件。
next_page = response.urljoin(url)
yield scrapy.Request(next_page, callback=self.parse_chapter)
scrapy.Request 不同于使用 response.follow,需要通过相对路径构造出绝对路径,response.follow 可以直接使用相对路径,因此就不需要调用 urljoin 方法了。
注意,response.follow 直接返回一个 Request 实例,可以直接通过 yield 进行返回。
数据获取了之后是存储,由于我们要的是 html 页面,因此,我们就按标题存储即可,代码如下:
def parse_chapter(self, response):
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s.html' % (title)
with open(filename, 'wb') as f:
f.write(content.encode('utf-8'))
pass
至此,我们已经成功的抓取到了我们的数据,但还不能直接使用,需要整理和优化。
数据整理
首先,我们爬取下来的章节页面排序不是很好,如果人工去排需要太多的时间精力;另外,章节内容包含许多额外的东西,阅读体验不好,我们需要优化内容的排版和可读性。
我们先给章节排个序,因为目录中的章节列表是按顺序排列的,所以只需要给下载页面名称添加一个顺序号就行了。
可是保存网页的代码是回调函数,顺序只是在处理目录的时候能确定,回调函数怎么能知道顺序呢?因此,我们要告诉回调函数它处理章节的顺序号,我们要给回调函数传参,修改后的代码是这样的:
'''
更多Python学习资料以及源码教程资料,可以在群821460695 免费获取
'''
def parse(self, response):
pages = response.xpath('//div[@id="j-catalogWrap"]//ul[@class="cf"]/li')
for page in pages:
url = page.xpath('./child::a/attribute::href').extract_first()
idx = page.xpath('./attribute::data-rid').extract_first()
# yield scrapy.Request('https:' + url, callback=self.parse_chapter)
req = response.follow(url, callback=self.parse_chapter)
req.meta['idx'] = idx
yield req
pass
def parse_chapter(self, response):
idx = response.meta['idx']
title = response.xpath('//div[@class="main-text-wrap"]//h3[@class="j_chapterName"]/text()').extract_first().strip()
content = response.xpath('//div[@class="main-text-wrap"]//div[@class="read-content j_readContent"]').extract_first().strip()
# print title
# print content
filename = './down/%s_%s.html' % (idx, title)
cnt = '<h1>%s</h1> %s' % (title, content)
with open(filename, 'wb') as f:
f.write(cnt.encode('utf-8'))
pass
Sigil make use of e-books
Html file to load
To create ePub e-books, we first Sigil to load our crawl files into the program, the Add File dialog box, we select all the files:
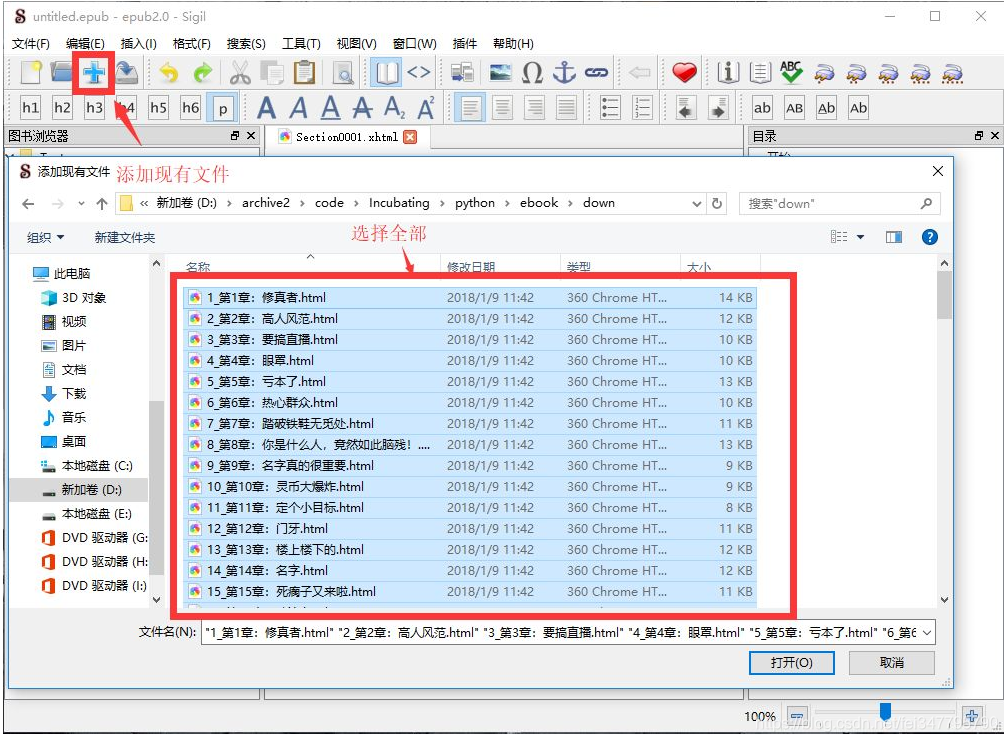
make directory
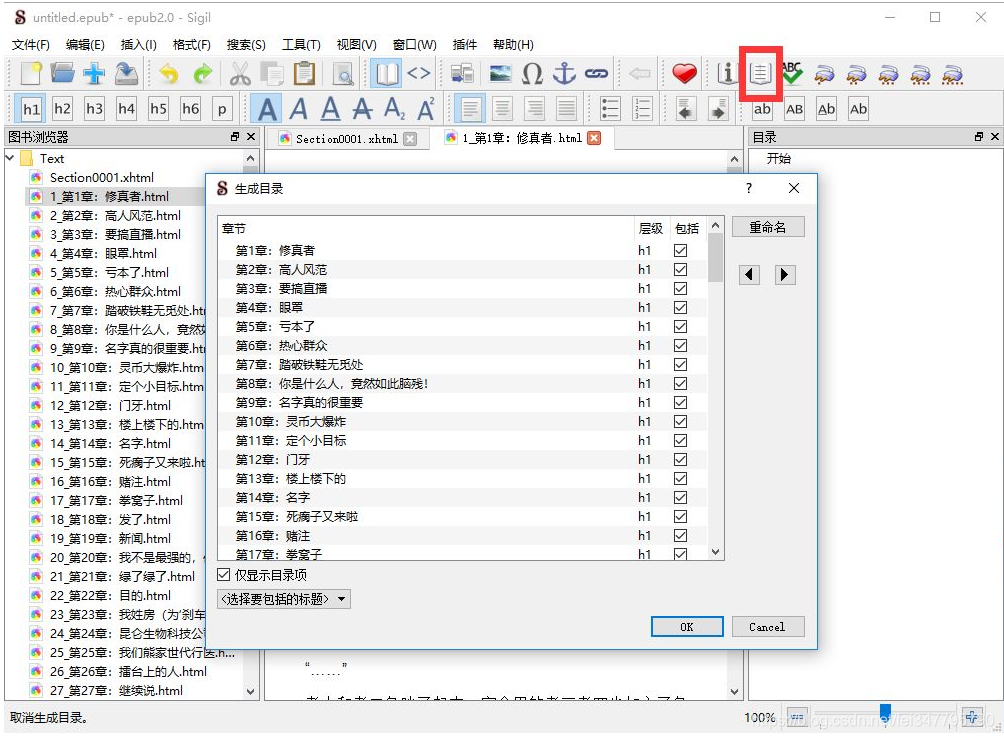
H in the presence of HTML tags file, click the button to generate a table of contents can be automatically generated table of contents, we've automatically add a h1 tag in the data front crawl:
create a cover
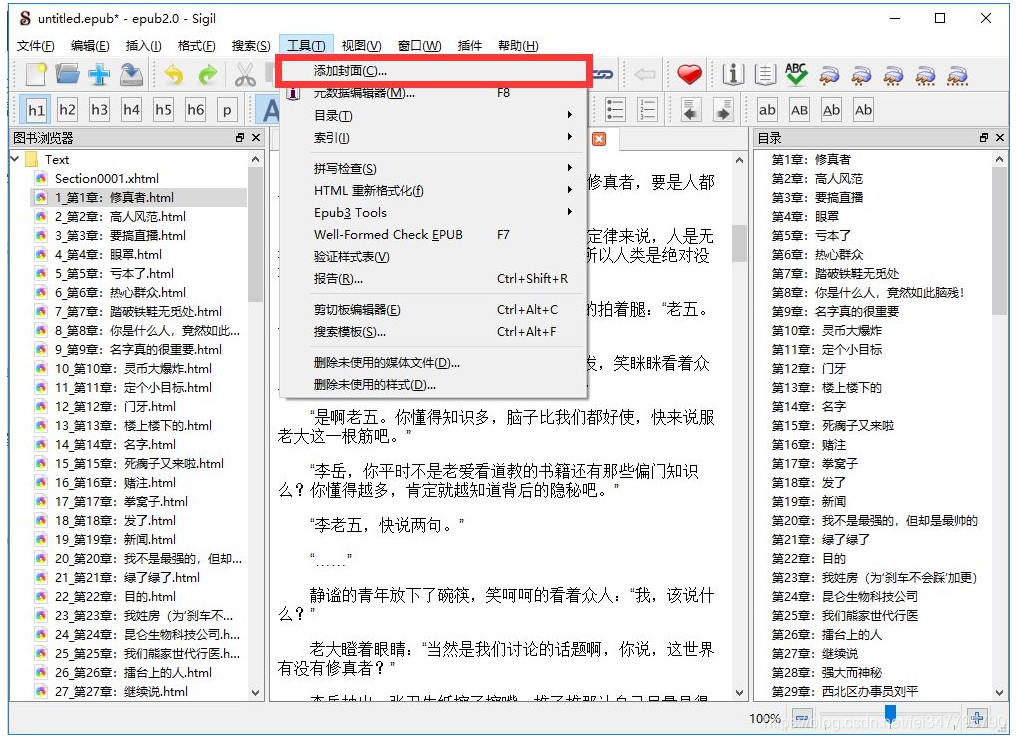
on the cover of nature is HTML, you can edit, you can crawl from page , on the left we all realize it.