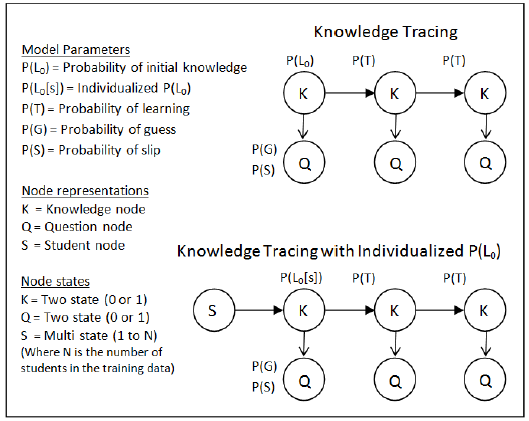
1. "T: Modeling Indivdualization in a Bayesian Networks Implementation od Konwledge Tracing" (personalized Bayesian network modeling knowledge tracked)
1. This goal: to explain students a priori knowledge of increasingly data, should be able to achieve a better fit and more accurate models to predict student data.
Knowledge Track model: the assumption that all students share the same initial priori knowledge does not allow a priori information for each student are combined.
This paper model: knowledge of a modification of the tracking model, by allowing specifying multiple parameters prior knowledge to increase its versatility, and let the Bayesian network parameter values to determine which students belong to a priori information in the unknown.
2.The Prior Per Student model(PPS模型)
PPS model only personalized attention prior knowledge of the parameters, the difference between KT model that can represent a priori knowledge of different parameters for each student, KT model is a special case each student a priori model. By adding a student node to personalize first value.
3. Experiment
The initial value of the learning rate parameter and the slide is guessing the random set to 0.0. To 0.9. Data sets for each question, answer the last question out, after being used to train parameters, using the EM algorithm to learn parameters to predict the performance of students. Students answer the last question of probability is calculated and saved for comparison with the actual answer.
The method of setting the initial value of the personalized paper focuses on two aspects: how to set (a) setting an initial value of personalized (b) personalized initial value is fixed or adjustable or EM parameter learning process.
(1) personalized initial value to a random value: EM tunable parameters in the learning process, other parameters such as
(2) students for the first time set a personalized answer to the initial value based on: student correctly answered the first question, personalized initial value is set to 1 minus a special guess (guess), if the wrong answer to the first one problem, were set to a particular value of slip (slip). The reason for using a special slip value and guess, because these values must be used before learning parameters. As used herein, a particular guess slip value 0.15 and 0.1. Other non-customized parameters are set to the average of the first answer, at a fixed premise personalized parameters, the non-personalized parameters are allowed to adjust. This method is called "cold start heuristic"
(3) set up personalized initial value based on the global accuracy: Suppose Student correlated with the next set of questions in a question set, skill or from a correlation between the presence of a skill. This assumption Policy closest model, the model assumes that each student has a transcendental value, this value on all the skills are the same. Correct percentage of students complete set of all the questions (in addition to the problem of prediction sets). Students who complete only problem is predicted, he personalized the initial value personalized initial worth of the average of other students. Personalized initial value is fixed, non-personalized initial value is adjustable.
result
The correlation between the calculated real answer to the last question and answer forecast (Correlation). The results showed that more than PPS model KT model. Percent correct heuristic strategy in question 42 sets, a set of 33 questions than KT model.

4. answer sequence analysis
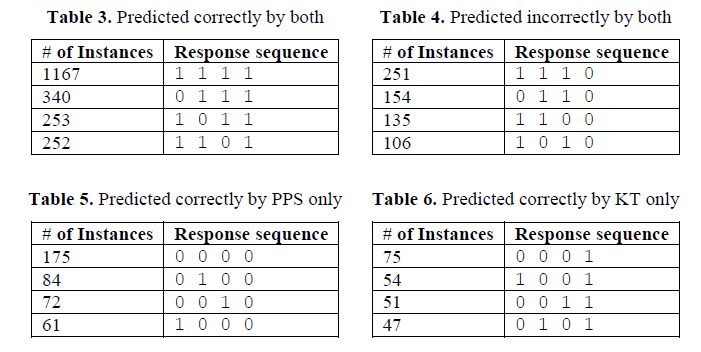
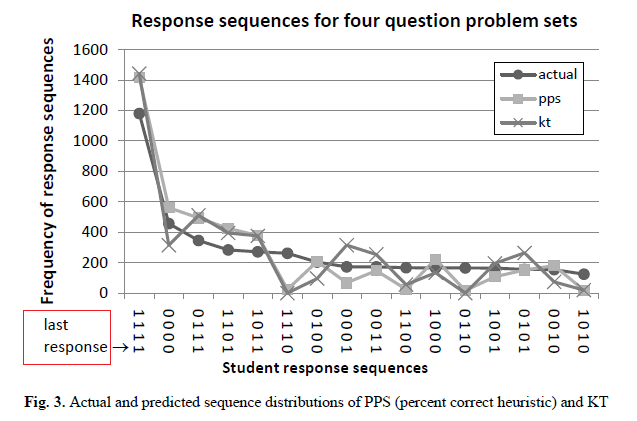
View model under what circumstances can predict right or wrong predictions. View sequence, and statistical models to predict how many times the answer to the last question is right or wrong. It analyzes the 11 problem sets, students answer 4448 sequences. Tables 3 and 4 show two models predict a final question to answer right or wrong answer sequence (just to name a number of occurrences of multi-sequence), Tables 5 and 6 show the last question is only a model to predict the correct answer answer sequence. The results show that the model is superior to predict KT PPS model.
5. Future Work
The author hopes this paper is a beginning, an attempt to better personalize, resulting in intelligent tutoring systems, personalized student learning experience.
The authors would like to know under what circumstances the use of PPS is not good. Of course, if all students in each skill has the same a priori in reality, then in establishing a personalized no a priori the utility. On the other hand, if the difference in students' knowledge of a skill priori large, this seems to be true, then a priori knowledge by capturing personalization will change the parameters, resulting in a better fitting model.
Each student needs a single argument? Or can the individual parameters are grouped into clusters, to achieve the same or better performance it? Has a relatively high performance of cold start heuristic model indicates that according to students the first reaction given skill, dividing them into one of the two parameters a priori, this is effective. Although this heuristic method is effective, but we doubt there is a better representation, and allows the value of the cluster prior learning, rather than as we do temporary settings. Ritter, who recently [8] Studies have shown that the clustering of similar skill can greatly reduce the number of parameters in the fit hundreds of skills to learn, while still maintaining a high degree of fit to the data. Perhaps a similar approach can be used to find groups of students and learn their parameters, rather than learning parameters personalized for each student.
Working paper focuses on four parameters in a knowledge tracked. We want to see, by explicitly simulate different rates of learning the fact that students can achieve a higher level of forecast accuracy. Students receive tutoring questions and feedback can be adjusted according to his learning speed. Student learning rate can also be reported to the teacher, or to make them more accurate and more quickly understand the students of their class. Speculation and sliding personalization is possible, direct comparison with the context of speculation and slide Baker's method will be one aspect of future work.
Have demonstrated that each student selected a priori representation, rather than tracking each skill knowledge a priori said to fit our data set is beneficial; however, better model may be the student's attributes and skills combining the model attributes. How to design properly handle both information exchange model is an open research questions in the field. This paper believes that the interests of users in order to expand the new system of personalized, sets a number of issues must be connected in a Bayesian network, using the evidence of multiple problem sets to help track individual students' knowledge and to benefit more fully percentage recommended correct heuristic.
2. "Addressing Two Problems in Deep Knowledge Tracing via Prediction-Consistent Regularization" (with regularization term to address two issues tracked by the depth of knowledge)
The authors found that two problems DKT models: a reconfiguration of the input sequence exists; 2 fluctuation prediction results.
(1) For Question 1, there is a good answer questions when students can point k knowledge, but the model predicts the probability that students master the knowledge point k fluctuated phenomenon. On that this situation is due, and not considered in the model loss function DKT employed in the input value at time t to time, but consider the output value of the input value at time t and time t + 1. Due to this problem, there will be such a phenomenon: When the sequence (S 32 , 0) (S 33 when, 0) occurs frequently, the model will be considered when the problem S 32 to answer true / false, S 33 will also be answered correctly / error. The experimental results show the problem of S 32 and S 33 is no correlation between before and after the experiment as shown below .

In response to these problems, the solution of this paper is incorporated in the regularization function loss, and the introduction of the input value at time t in a time regularization term, the regularization term r as follows:
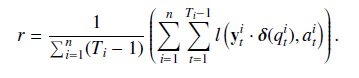
(2) For Question 2, the model predicted the state of knowledge fluctuate over time and inconsistent, which is practical, because of the expected high school students grasp the state of knowledge, should become stable over time.
This paper argues that may be due to hidden layer RNN indicates a problem, the hidden layer represents the extent of potential students to master knowledge, RNN hidden layer H t rely on a hidden layer output before, but it's hard to say clear of each hidden layer how status affects prediction model. Therefore, as the output results directly constrained regularization (L1, L2 regular), so that the smooth output can be predicted result, the regularization term w as follows;
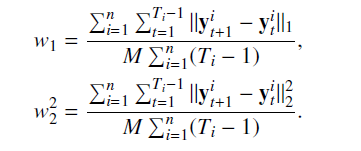
Papers have found the code on GitHub, and can be run locally.
3. "NPA: Neural News Recommendation with Personalized Attention" (With personalized attention mechanisms news recommended)
News recommendation is an important task for the online news platform. Face of massive daily production of news on the Internet, news recommendation to help users find news of interest, and reduce information overload.
While browsing the news, different users often have different interests, and for the same news article, different users tend to focus on its different aspects. However, the news has been recommended method for modeling interest differences are often unable to users on the same news.
There are two scenarios in the news recommended common observations:
1. Not all users can click on the news reflect the user's preferences; the same information to different users should have different information, in order to model the different users .
2. headlines in different words generally have different amount of information to study journalism representation; while the same words in headlines may have a different amount of information to reflect the preferences of different users.
This paper presents a neural news recommendation with personalized attention (NPA) model, the mechanism can be applied to personalized attention in the news recommended tasks to model different interests for different user vocabulary and news. The core of the model is news said user represents and estimated clicks:
1. News Encoder: learning based on news headlines. Each word in the headline of the first word is mapped as a vector, then use CNN to learn words in context, said last select important words through word-level attention mechanism, constructed headlines representation.
2. User Encoder: From the user clicks on the news in the understanding of the user's preferences, the module uses a personalized level of attention mechanisms news.
3. Click Predictor: a prediction score for each candidate user clicks on the news.
Model :

experiment
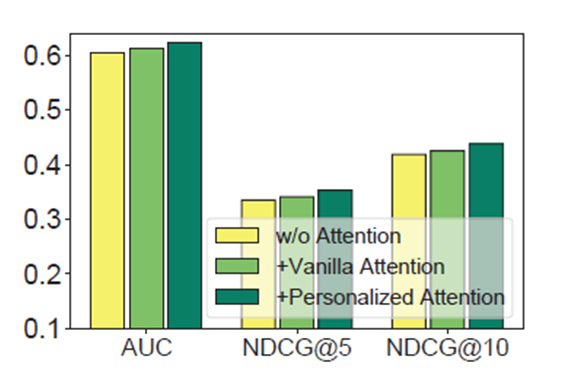
Experimental data from MSN news, random sample of 10,000 users use MSN as a data set of data in a month. FIG model are the result of comparison with other recommended models.
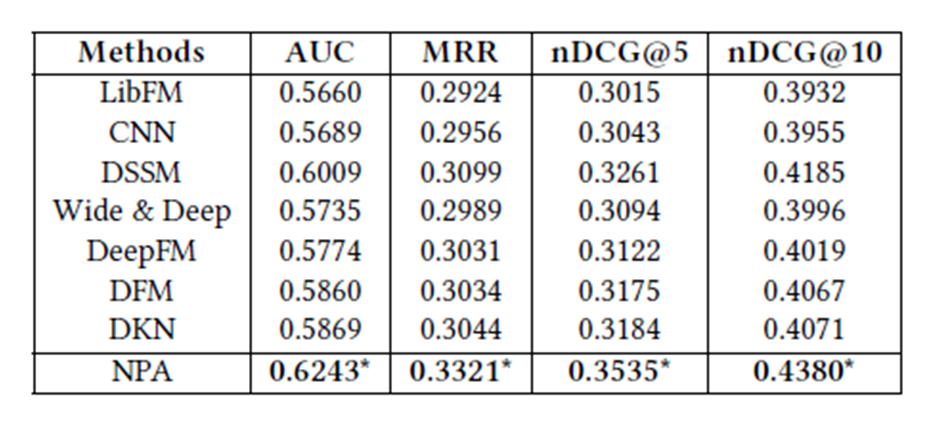
The figure below shows the results of the use of Personalized Atterntion better than not using Atterntion and Vanilla Attention recommended effect.
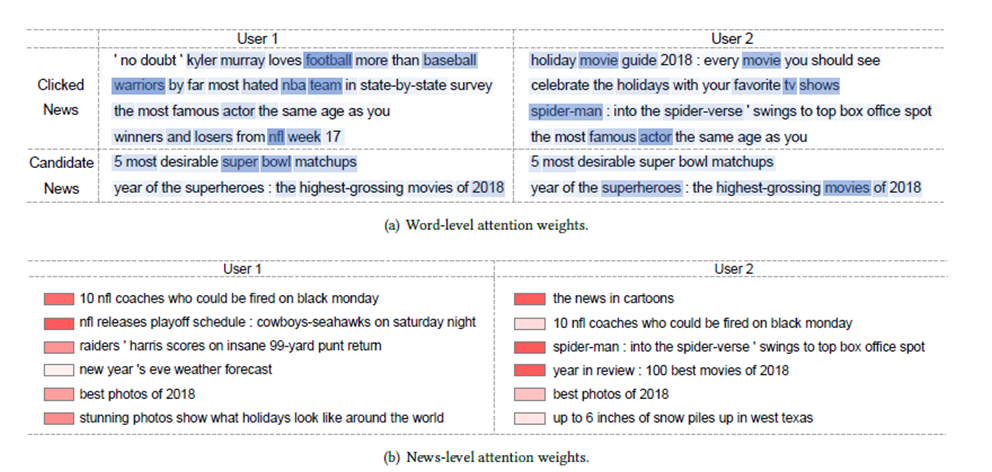
The following figure shows the headlines of different words for different users different information, different news information for different users different.
Inspired: tracking knowledge can help to improve the prediction Attention effect.