Introduction
selenium is the equivalent of a robot that can simulate the behavior of human landing browsers, such as clicks, fill data, delete the cookie, and so on. Chromedriver Chrome is a driver program, use it only can drive browser, before actually Chromedriver is used for automated testing, but found that it is suitable for reptiles. Of course, here is Chromedriver, different browsers have different driver, but here we only introduce Chrome. After all, Google Chrome browser on this level basically be to dominate the world. About selenium is generally in order to obtain dynamic data for those sites using ajax technology, direct access will be difficult, because you view the page source code which can not be found, of course, if analyzes ajax interface, it can be acquired. And by selenium drive driver, then no matter what the technology, as long as could be seen on the page, so you can get to. So if the page is static, it is recommended to use requests, dynamic page recommend selenium + driver
installation
For selenium, directly pip install seleniumto

For the driver, we direct the driver to download the corresponding version, you can look on the version of Chrome to install their own path, usually the default is C: \ Program Files (x86) \ Google \ Chrome \ Application below
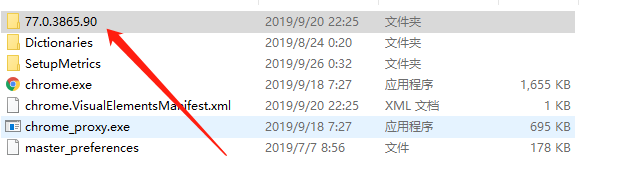
File name is the corresponding version number, we can go to this website http://npm.taobao.org/mirrors/chromedriver/ inside to find the corresponding driver to Chrome. In general, no problem as long as the first three parts, like the last part of the 90, I downloaded the 40, but with no significant problems. Of course, there is the same to use exactly the same, is not the main driver 77.0.3865.90 that site above, driver only 77.0.3865.40, but can also be used.
Getting Started
下面我们就看看这个selenium怎么操作这个webdriver
from selenium import webdriver # 从selenium包中导入webdriver
# 指定driver的路径,就是我们刚才下载的。
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
# 通过webdriver调用Chrome这个类,指定executable_path,传入driver_path,得到对应的driver
driver = webdriver.Chrome(executable_path=driver_path)
# 那么我们就可以使用driver这个驱动去请求应页面了,调用get方法,传入url
driver.get("http://www.baidu.com/s?wd=komeijisatori")
# 调用driver下的page_source得到源代码,查看前100个字符
print(driver.page_source[0: 100])
"""
<html><head>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta http-equiv=
"""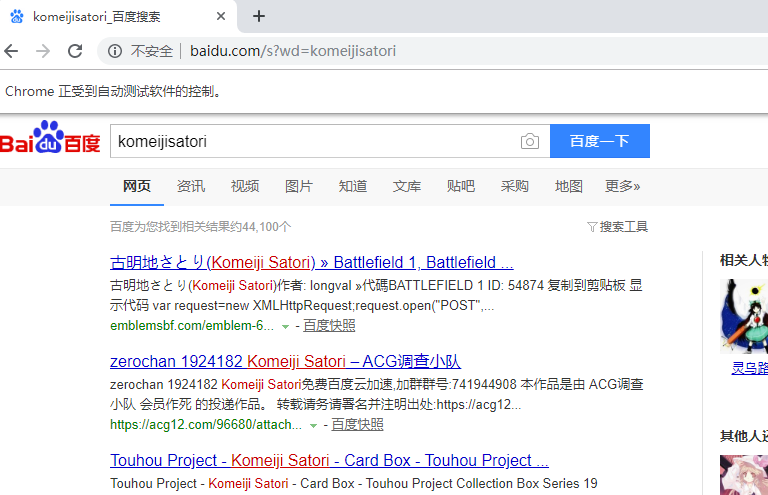
可以看到,自动地会打开相应的页面。如果能打开页面并获取到数据,说明是安装成功了的,如果失败那么就根据报错信息查找一下原因吧。
Close the browser and selenium
Close the page can be turned off, and close the browser.
driver.close():关闭当前页面driver.quit():关闭浏览器
from selenium import webdriver
import time
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("http://www.baidu.com/s?wd=komeijisatori")
time.sleep(5) # 为了观察到现象,这里sleep 5秒
# driver.close()
# driver.quit()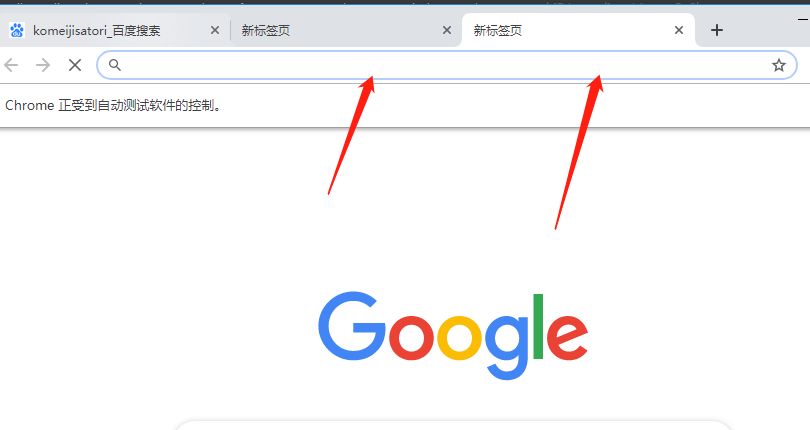
When we execute a program to open the page, click the plus sign, the new page. If it is close, then just shut the beginning of the page that opens, two 新标签页will not close. But if it is quit, then not only page, the entire browser will launch. This is not good shots, free to try.
Positioned elements
If we want to find some labels, how to do it? selenium also provides us with a lot of ways.
根据id来查找from selenium.webdriver.support.select import By # 两种方式等价的 driver.find_element_by_id("id_name") driver.find_element(By.ID, "id_name")根据类名查找元素driver.find_element_by_class_name("class_name") driver.find_element(By.CLASS_NAME, "class_name")根据name属性的值来查找元素driver.find_element_by_name("username") driver.find_element(By.NAME, "username")根据标签名来查找元素driver.find_element_by_tag_name("div") driver.find_element(By.TAG_NAME, "div")根据xpath语法来选择元素driver.find_element_by_xpath("//div[@class='哈哈哈']/a") driver.find_element(By.XPATH, "//div[@class='哈哈哈']/a")根据css选择器选择元素driver.find_element_by_css_selector("banner") driver.find_element(By.CSS_SELECTOR, "banner")
The above is 6 acquires the tag way sufficient. But all of the above methods are eligible to obtain a first label, if multiple obtain, simply put element into elements. For example: find_elements_by_name ( "username"), find_elements (By.NAME, "username")
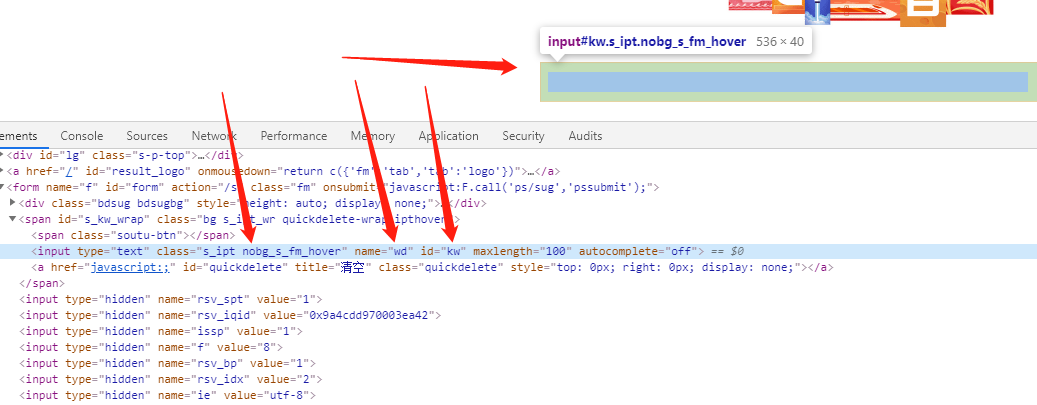
For example, I want to get "Baidu, you know," this input box, I have a variety of ways, such as by id = "kw" name = "wd" class = "a bit long do not write" and so on.
from selenium import webdriver
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("http://www.baidu.com")
tag = driver.find_element_by_id("kw")
# 得到的tag依旧可以使用find_element_by_xxx等方法
# 但除此之外还有哪些属性呢
# 拿到当前的标签名,既然我们获取的是输入框,应该是input
print(tag.tag_name) # input
# 拿到标签对应的文本,有可能为空,所以我们用%r打印
print("%r" % tag.text) # ''
# 获取位置
print(tag.location) # {'x': 152, 'y': 310}
# 获取尺寸
print(tag.size) # {'height': 22, 'width': 500}
# 说实话这些都没啥用,至于其他的方法,会之后介绍之前说了,我们有很多种方式获取
from selenium import webdriver
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("http://www.baidu.com")
tag1 = driver.find_element_by_name("wd")
tag2 = driver.find_element_by_class_name("s_ipt")
print(tag1.tag_name) # input
print(tag2.tag_name) # input由于selenium获取元素的方式是通过python原生实现的,速度肯定没有底层使用C语言实现的lxml模块快,但是它能够对标签进行操作。因此如果我们只是想获取指定内容、不对标签进行操作的话,建议使用driver.page_source获取网页源代码,然后使用lxml或者pyquery进行解析,pyquery底层是使用lxml。
Operation form element selenium
Common form elements, what does? type = "text / username / password / email, etc.," the input tag, we can be entered through the selenium content of the input.
from selenium import webdriver
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("http://www.baidu.com")
# 获取标签
tag1 = driver.find_element_by_id("kw")
# 调用send_keys方法,往里面输入内容
tag1.send_keys("古明地觉")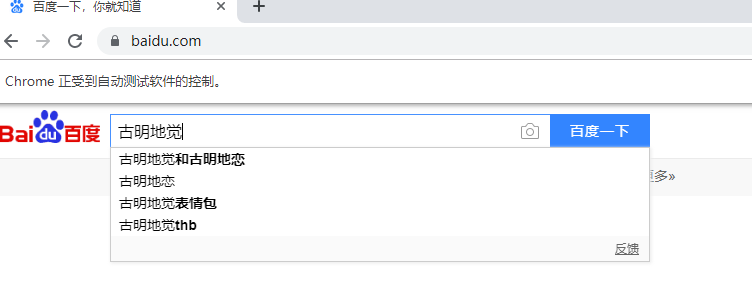
自动帮我们输入了,既然能输入那就能清除
from selenium import webdriver
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("http://www.baidu.com")
# 获取标签
tag1 = driver.find_element_by_id("kw")
# 调用send_keys方法,往里面输入内容
tag1.send_keys("古明地觉")
import time
time.sleep(5)
# 调用clear方法,5s后就自动删除了
tag1.clear()
Operation checkbox, that when we landed in general, there will be a similar "remember me" the little box
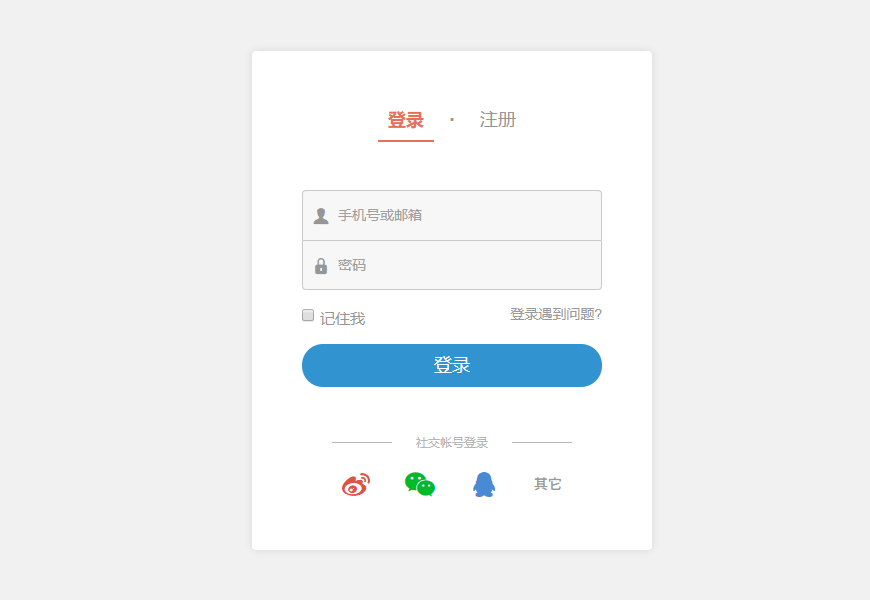
from selenium import webdriver
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.jianshu.com/sign_in")
# 获取对应按钮
tag1 = driver.find_element_by_id("session_remember_me")
# 调用click方法表示点击
tag1.click()如果想取消怎么办?那么就再调用一次click方法
Operation select, there are many options that can make the label we choose. Personal feel of operation select few, I did not find the corresponding website, not demonstrated.
from selenium import webdriver
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.xxxx.com")
# 获取select对应按钮
selectBtn = driver.find_element_by_id("select_id")
# 有了select还不行,必须要包装一下
from selenium.webdriver.support.ui import Select
selectBtn = Select(selectBtn)
# 通过索引
# selectBtn.select_by_index(1)
# 通过值
# selectBtn.select_by_value("http://xxx")
# 根据可视的文本选择
# selectBtn.select_by_visible_text("xxx")
# 取消所有选择
# selectBtn.deselect_all()Mouse click events. We simulate Baidu search, which means we have to find the input box, and then find Baidu that button, then click
from selenium import webdriver
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
# 获取input输入框
input_btn = driver.find_element_by_id("kw")
input_btn.send_keys("古明地觉")
# 获取百度一下按钮
baidu_btn = driver.find_element_by_id("su")
baidu_btn.click()
可以看到,自动进入了相应的页面。
Behavior Chain
Sometimes operation on the page there are many steps, such as clicking, typing, clicking, etc., then this string of actions you can use to string together a chain, is the behavior chain
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains # 导入相关的类
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
# 获取input输入框
input_btn = driver.find_element_by_id("kw")
# 获取百度一下按钮
baidu_btn = driver.find_element_by_id("su")
# 这个类接收一个driver
action_chains = ActionChains(driver)
# 下面可以进行操作
# 首先我们要把鼠标移动到input输入框里面去
action_chains.move_to_element(input_btn)
# 向指定的输入框里面输入内容
action_chains.send_keys_to_element(input_btn, "古明地恋")
# 然后移动到百度一下按钮上面
action_chains.move_to_element(baidu_btn)
# 点击相应的按钮
action_chains.click(baidu_btn)
# 以上相当于数据库里面的事务,然后调用perform执行链子上的操作
action_chains.perform()
以上打开页面、输入内容、点击都是程序自动完成的
There are many behavioral chain operations
click_and_hold(element):点击但不松开鼠标context_click(element):右键点击double_click(element):双击
cookie operations
获取所有cookiefrom selenium import webdriver driver_path = r"D:\chromedriver_win32\chromedriver.exe" driver = webdriver.Chrome(executable_path=driver_path) driver.get("https://www.baidu.com") for cookie in driver.get_cookies(): print(cookie) """ {'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '1432_21103_18560_29073_29523_29720_29567_29220_26350_22160'} {'domain': '.baidu.com', 'expiry': 3717332129.99234, 'httpOnly': False, 'name': 'BIDUPSID', 'path': '/', 'secure': False, 'value': 'ABEDD46CE6CCC56548E54C1159D892B6'} {'domain': '.baidu.com', 'httpOnly': False, 'name': 'delPer', 'path': '/', 'secure': False, 'value': '0'} {'domain': '.baidu.com', 'expiry': 3717332129.992357, 'httpOnly': False, 'name': 'PSTM', 'path': '/', 'secure': False, 'value': '1569848483'} {'domain': '.baidu.com', 'expiry': 1569934883.162394, 'httpOnly': False, 'name': 'BDORZ', 'path': '/', 'secure': False, 'value': 'B490B5EBF6F3CD402E515D22BCDA1598'} {'domain': 'www.baidu.com', 'expiry': 1570712483, 'httpOnly': False, 'name': 'BD_UPN', 'path': '/', 'secure': False, 'value': '12314753'} {'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_HOME', 'path': '/', 'secure': False, 'value': '0'} {'domain': '.baidu.com', 'expiry': 3717332129.99231, 'httpOnly': False, 'name': 'BAIDUID', 'path': '/', 'secure': False, 'value': 'ABEDD46CE6CCC56548E54C1159D892B6:FG=1'} """获取指定cookiefrom selenium import webdriver driver_path = r"D:\chromedriver_win32\chromedriver.exe" driver = webdriver.Chrome(executable_path=driver_path) driver.get("https://www.baidu.com") print(driver.get_cookie("H_PS_PSSID")) """ {'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '1461_21115_29522_29721_29568_29221_26350'} """删除指定cookiefrom selenium import webdriver driver_path = r"D:\chromedriver_win32\chromedriver.exe" driver = webdriver.Chrome(executable_path=driver_path) driver.get("https://www.baidu.com") print(driver.get_cookie("H_PS_PSSID")) """ {'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '1445_21084_29523_29721_29568_29221'} """ driver.delete_cookie("H_PS_PSSID") # 删除之后,再获取一次 print(driver.get_cookie("H_PS_PSSID")) # None删除所有cookiefrom selenium import webdriver driver_path = r"D:\chromedriver_win32\chromedriver.exe" driver = webdriver.Chrome(executable_path=driver_path) driver.get("https://www.baidu.com") # 删除所有的cookie driver.delete_all_cookies() # 得到是空列表 print(driver.get_cookies()) # []
Page wait
Many sites are now using ajax technology, so that the program can not determine an appropriate elements will come out fully loaded. If the actual page you wait too long resulting in a dom element has not been loaded out, try to get a response tag, you will not find the cause error. To solve this problem, so selenium provides two ways to wait, wait implicit and explicit wait.
Implicit wait:直接指定一个等待时间,通过driver.implicitly_wait指定,不管页面加载情况如何,只要过了指定的等待时间,就开始获取元素
from selenium import webdriver
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
# 表示隐式等待10s
driver.implicitly_wait(10)
# todo:可以隐式等待10s之后,再去做相应的操作Shows the wait:相较于隐式等待比较智能一些,需要等待某个条件成立之后才去执行获取指定元素的操作。在可以同时指定一个最大时间间隔,如果超过了这个时间间隔,那么会抛出一个异常。显示等待应该使用selenium.webdriver.support.excepted_conditions(期望条件)和selenium.webdriver.support.ui.WebDriverWait(显示等待)来配合完成。
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.select import By
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
# 让driver等待10s,直到
WebDriverWait(driver, 10).until(
# 某个id="xxx"的元素出现
ec.presence_of_element_located((By.ID, "ID_NAME"))
)Of course, there are other wait condition: presence_of_all_elements_located: All the elements are loaded. element_to_be_clickable: An element can be clicked.
And switch window multiwindow
Sometimes we want to open a new page, but could not close the original page, but more pages you want to switch back and forth, this time how to do it? selenium also provides us with the appropriate method.
from selenium import webdriver
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
# 在介绍之前,肯定会有人思考能不能这么做
driver.get("https://www.baidu.com")
driver.get("https://www.bilibili.com")
# 这样不就打开两个页面了吗?确实没错,但是后一个页面把上一个页面给冲掉了We can call driver.execute_script, this method can execute JavaScript code directly
from selenium import webdriver
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
# 在js中,通过window.open打开新窗口
driver.execute_script("window.open('https://www.bilibili.com')")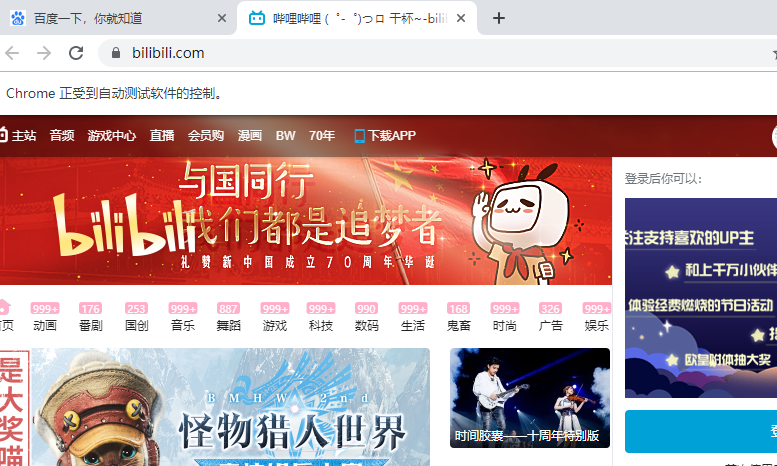
尽管通过图片,我们看到此时切换的是比例比例页面,但是在代码层面上,我们还是在一开始的百度窗口上面,怎么验证呢?可以调用driver.current_url查看一下当前页面的url
print(driver.current_url) # https://www.baidu.com/打印的依旧是百度的url
So how to switch it? can usedriver.switch_to.window里面传入窗口句柄,这个句柄可以通过driver.window_handler获取,driver.window_handler是一个列表,里面存放打开的窗口句柄,句柄的顺序就是打开页面的顺序,显然对于当前window_handler里面只有两个句柄,第一个是百度页面的句柄,第二个是bilibili页面的句柄
from selenium import webdriver
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
# 在js中,通过window.open打开新窗口
driver.execute_script("window.open('https://www.bilibili.com')")
# 以前是driver.switch_to_window,这方法此时还能用,但是已经提示我们要被移除了
# 建议我们使用driver.switch_to.window
driver.switch_to.window(driver.window_handles[1]) # 切换到bilibili
# 打印当前页面的url
print(driver.current_url) # https://www.bilibili.com/Now the question is, if there is a page, the page has 100 links above, I want to get this 100 page links to corresponding source code, and can only remain two windows, how to do it. Obviously, the new window opens url of the page to get content. And then close, then open a second new window url of the page, continue to acquire, in turn reciprocate
Then we just, for example, open Baidu, and then open bilibili, turn off bilibili, open watercress, turn off the watercress, know almost open, know almost turned off, open the blog garden. Of course, the premise is to first open a new page back to Baidu, we assume that these links are in the top Baidu
from selenium import webdriver
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
# 通过window.open打开新窗口bilibili
driver.execute_script("window.open('https://www.bilibili.com')")
# 切换到bilibili
driver.switch_to.window(driver.window_handles[1])
# 源代码就不获取了,就用打印url代替吧
print(driver.current_url)
#关掉bilibili,由于窗口已经切换了,所以close掉的是bilibili的页面
# 注意不能是quit,那样的话,整个浏览器页面就关掉了
driver.close()
# 当close之后,此时的窗口还是停留在bilibili,或者说还没有切换到百度
# 但是此bilibili页面的窗口句柄已经不存在了,此时再进行操作就会报错,提示窗口已经关闭
# 切换到百度窗口,此时window_handlers里面就只有一个元素了
driver.switch_to.window(driver.window_handles[0])
# 打开豆瓣
driver.execute_script("window.open('https://www.douban.com')")
# 切换到豆瓣,此时window_handlers里面就又有两个元素
driver.switch_to.window(driver.window_handles[1])
# 打印url
print(driver.current_url)
# 关闭
driver.close()
# 切换到百度
driver.switch_to.window(driver.window_handles[0])
# 打开知乎
driver.execute_script("window.open('https://www.zhihu.com')")
driver.switch_to.window(driver.window_handles[1])
print(driver.current_url)
driver.close()
driver.switch_to.window(driver.window_handles[0])
# 打开博客园
driver.execute_script("window.open('https://www.cnblogs.com')")
driver.switch_to.window(driver.window_handles[1])
print(driver.current_url)
driver.close()
# 最后再切换到百度
driver.switch_to.window(driver.window_handles[0])
print(driver.current_url)
"""
https://www.bilibili.com/
https://www.douban.com/
https://www.zhihu.com/signin?next=%2F
https://www.cnblogs.com/
https://www.baidu.com/
"""Of course demonstrated here, a bit long-winded, when you can actually write code using a loop.
Use a proxy ip
from selenium import webdriver
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
# 指定代理
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.110.110.119:6666")
# 设置options参数即可
driver = webdriver.Chrome(executable_path=driver_path, chrome_options=options)
# 然后就可以使用代理访问了
driver.get("https://www.baidu.com")WebElement class supplement
We use other methods to get to driver.find_element is a WebElement object, after we get this object, you can also get the corresponding property
from selenium import webdriver
driver_path = r"D:\chromedriver_win32\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
tag = driver.find_element_by_id("su")
print(type(tag)) # <class 'selenium.webdriver.remote.webelement.WebElement'>
# 通过get_attribute获取
print(tag.get_attribute("type")) # submit
print(tag.get_attribute("value")) # 百度一下
print(tag.get_attribute("class")) # bg s_btn