first step
Open a movie review interface:
Rebels child came into the world of magic: https://maoyan.com/films/1211270
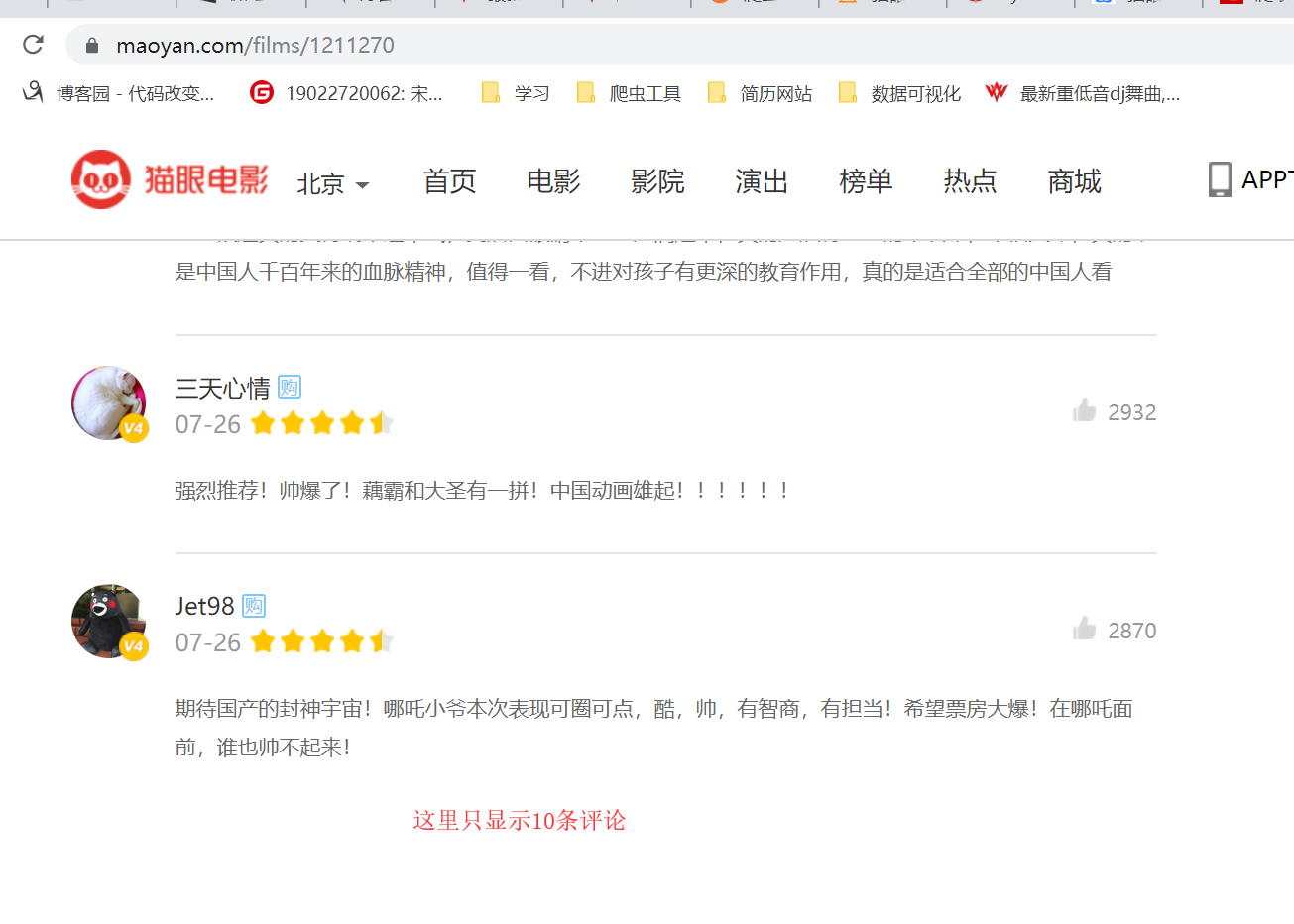
We found that only 10 comments show here, and we need crawling 10w of data, it can not be from this page capture, so give up! ! ! !
So I checked the Internet, and finally saw an article comes to developer mode can be switched directly to the phone mode;
The second step
Developer mode switching mode for mobile phones
After switching modes can see all the comments are displayed, we can directly analyze packet capture
third step
Click to view full discussion
Developer Tools switch switch XHR, and has been declining View Comments
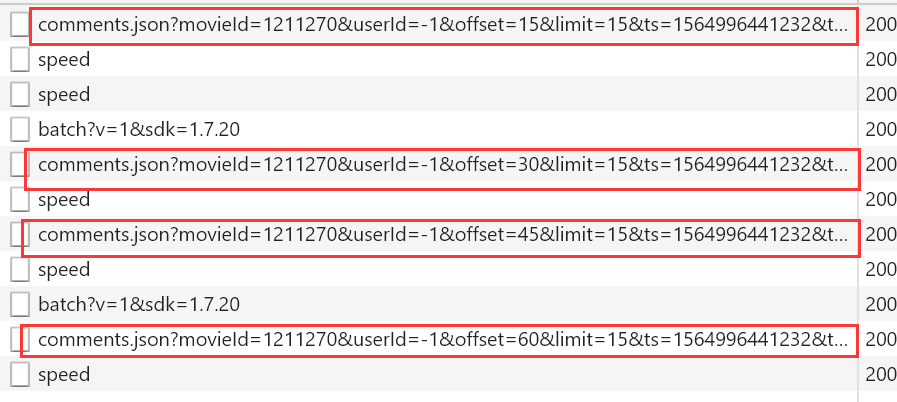
Data corresponding to each request
http://m.maoyan.com/review/v2/comments.json?movieId=1211270&userId=-1&offset=15&limit=15&ts=1564996441232&type=3 # MovieID expressed movie ID # offset represents the offset # how much data limit a display # TS current timestamp
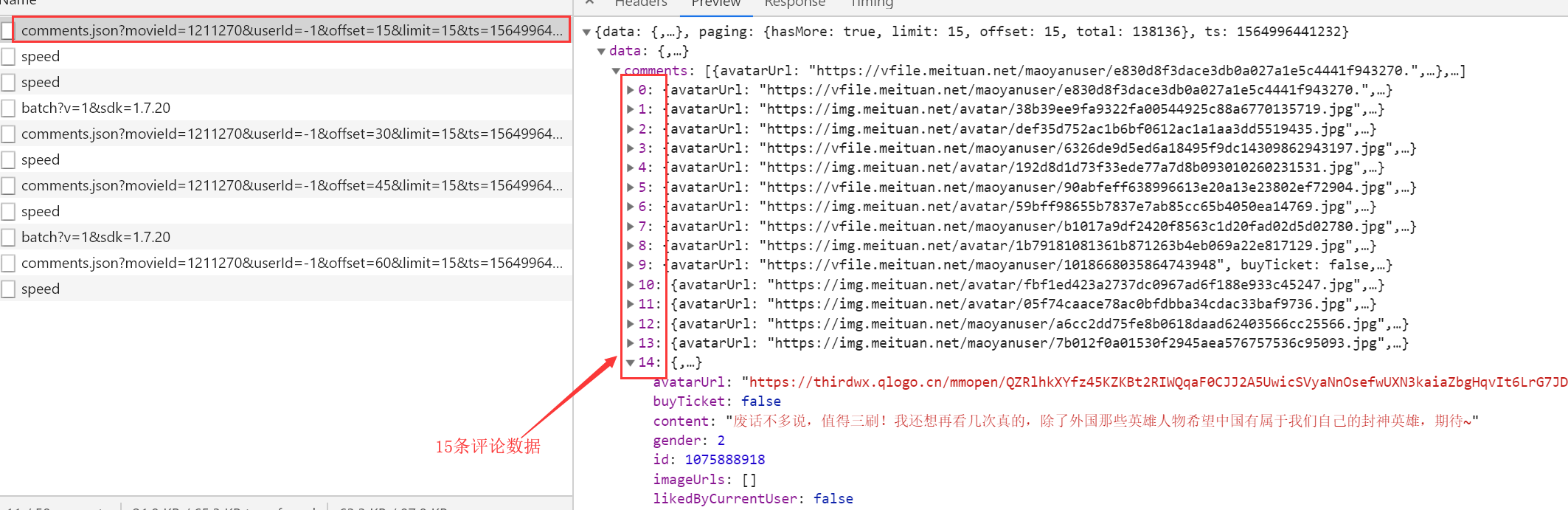
By repeatedly observing the decline can be seen every time the offset is changing, and each plus 15, which is an increase of 15 reviews, in fact, we know that the law should be done, but there is a problem, this method only 1000 can crawl data, unless a time stamp change, i.e. TS,
the fourth step
We are on the basis of the above method after change timestamp can only be found crawling 1000 data, we can only find another method;
So we know that there is another by Baidu api can get a cat's eye movie review data
http://m.maoyan.com/mmdb/comments/movie/1211270.json?_v_=yes&offset=0&startTime=2019-08-04%2018:18:53
# 只需要改变startTime,根据时间段来获取评论数据
# 每次获取的评论数据还是15条
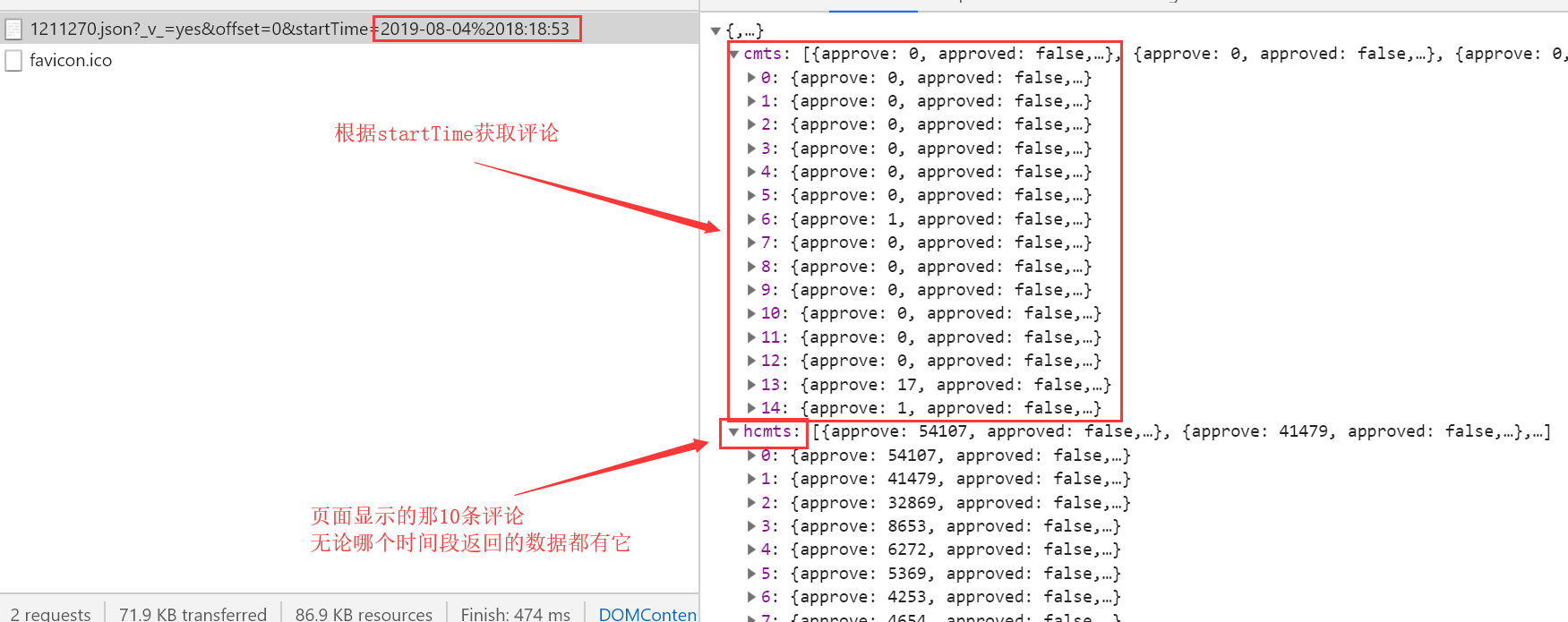
查看每页中最后一条数据的startTime
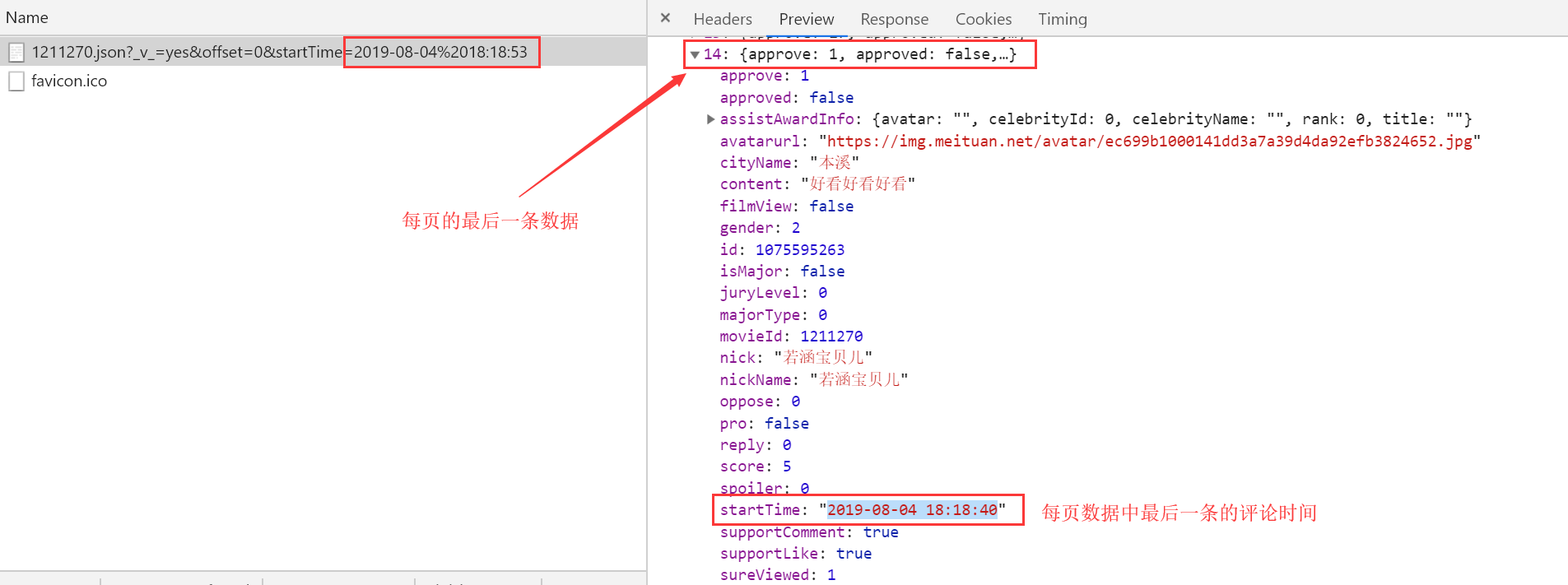
根据上面的原理我们制定爬取方案:
因为我们请求网页所得到的响应数据只用15条,且可以获取到最后一条数据的startTime;
第一次请求url中的startTime我们用当前时间,并获取响应数据中最后一条数据的startTime;
第二次请求时我们将时间替换为第一次请求时响应数据中最后一条数据的startTime,依次类推
直到时间为电影的上映时间即可获取该部电影的所有评论数据;


from pymongo import MongoClient my_client = MongoClient("127.0.0.1",27017) MDB = my_client["Movie_rating"] # 指定连接电影评分的库名 print(MDB.Movie_comment.find({}).count()) # 查看表中一共有多少条数据
import time import random import datetime import requests from mongo_db import MDB # 获取当前时间转换为2019/8/5 17:31:15形式空格用%20替换 now_time=datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S').replace(' ','%20') headers = { 'Host': 'm.maoyan.com', 'Referer': 'http://m.maoyan.com/movie/1211270/comments?_v_=yes', 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36', 'X-Requested-With': 'superagent', } time.sleep(random.random()) # 从当前时间往前爬取2000个url的数据,每个url有15条数据 for num in range(1,2000): url = "http://m.maoyan.com/mmdb/comments/movie/1211270.json?_v_=yes&offset=0&startTime={}".format(now_time) print("正在下载第{}条评论".format(num)) response = requests.get(url).json() # 每页的最后一条评论的时间,每次请求后给全局的now_time重新赋值,下次请求时用的时间就是上次响应数据中的最后一条数据的时间 now_time = response["cmts"][-1]["startTime"] for movie_info in response["cmts"]: cityName = movie_info["cityName"] content = movie_info["content"] user_id = movie_info["id"] nickName = movie_info["nickName"] movieId = movie_info["movieId"] gender = movie_info.get("gender") if not gender: gender = "暂无" comment_info = {"cityName":cityName,"nickName":nickName,"user_id":user_id,"movieId":movieId,"gender":gender,"content":content} # 因为我们创建了唯一索引,所以我们在插入数据时如果有重复的会报错,这里做了异常处理 try: MDB.Movie_comment.insert_one(comment_info) except Exception as e: print(e) print("所有评论下载完成")
数据下载地址:https://files.cnblogs.com/files/songzhixue/%E7%8C%AB%E7%9C%BC%E7%94%B5%E5%BD%B13w%E6%9D%A1%E8%AF%84%E8%AE%BA%E6%95%B0%E6%8D%AE.rar
共计3w评论下载完成后导入mongodb数据库
时间转换地址:http://tool.chinaz.com/Tools/unixtime.aspx