Article Directory
This blog is only for learning and communication, not for commercial purposes
1 Website analysis
The address of Maoyan Movies is "https://maoyan.com/board/4?offset=20", where offset represents the offset, and offset=20 means you want to crawl the 21st to 30th movies. So we have to construct a variable BASE_URL ='http://maoyan.com/board/4?offset=' to splice the entire crawled link. There are many anti-crawler mechanisms in Maoyan. Section 2.3 will introduce how to solve anti-crawlers.
2 Code completion
2.1 Guide package & define variables
First, import the package and define global variables
import requests
import logging
import pymongo
from pyquery import PyQuery as pq
from urllib.parse import urljoin
import multiprocessing
# 定义日志级别
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
# 根路径
BASE_URL = 'http://maoyan.com/board/4?offset='
# 总页数
TOTAL_PAGE = 10
# MongoDB配置信息
MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGO_DB_NAME = 'movies'
MONGO_COLLECTION_NAME = 'maoyan'
client = pymongo.MongoClient(MONGO_CONNECTION_STRING)
db = client[MONGO_DB_NAME]
collection = db[MONGO_COLLECTION_NAME]
2.2 Splicing URL
# 拼接url,调用get_html(url)
def get_index(page):
url = f'{BASE_URL}{page}'
return get_html(url)
2.3 Crawling HTML
There are many anti-crawler mechanisms in Maoyan Movies. This can be solved by adding User-Agent and cookie. You need to add your own browser cookie, as shown in the figure below:
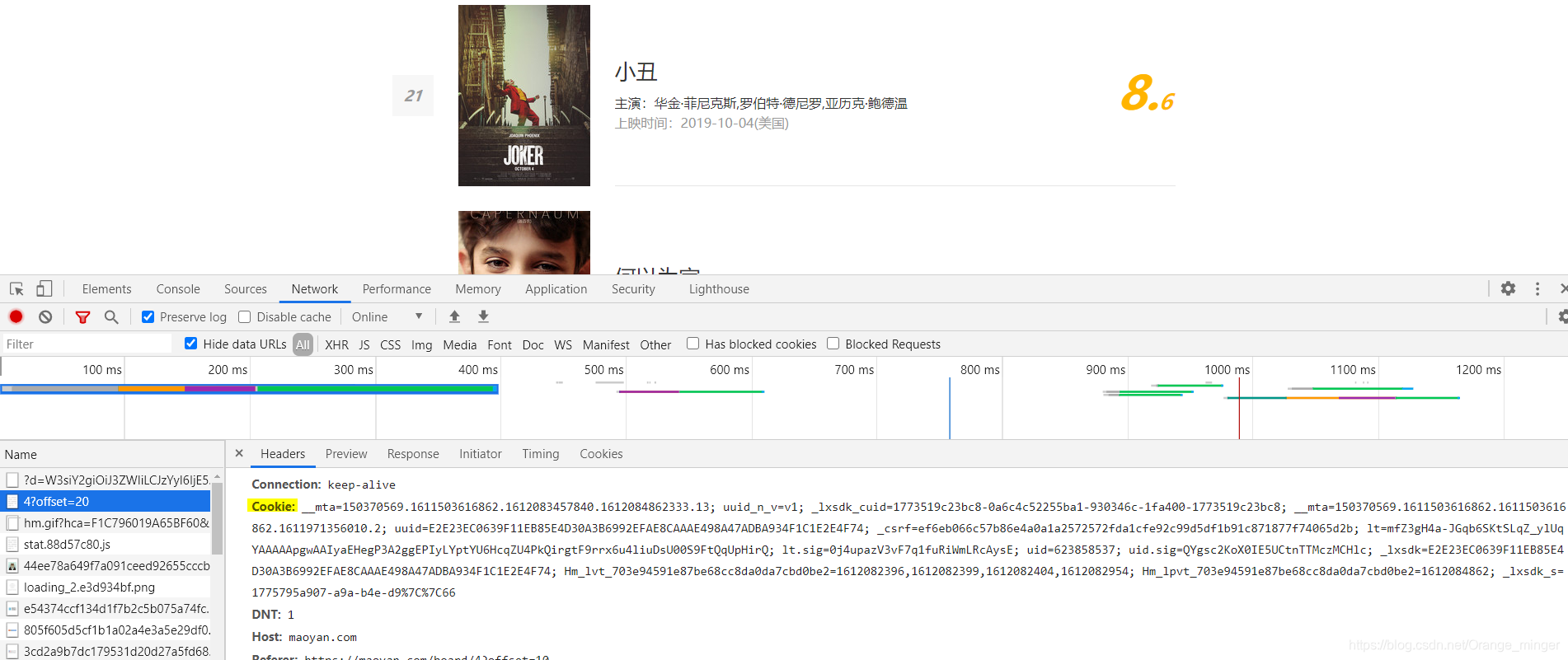
At the same time, you have to browse Maoyan.com several times with your own browser. It is best if you can encounter the verification code verification.
def get_html(url):
logging.info('scraping %s...', url)
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.3987.122 Safari/537.36",
"Cookie": '__mta=150370569.1611503616862.1612082954043.1612082957903.9; uuid_n_v=v1; _lxsdk_cuid=1773519c23bc8-0a6c4c52255ba1-930346c-1fa400-1773519c23bc8; __mta=150370569.1611503616862.1611503616862.1611971356010.2; uuid=E2E23EC0639F11EB85E4D30A3B6992EFAE8CAAAE498A47ADBA934F1C1E2E4F74; _csrf=ef6eb066c57b86e4a0a1a2572572fda1cfe92c99d5df1b91c871877f74065d2b; lt=mfZ3gH4a-JGqb6SKtSLqZ_ylUqYAAAAApgwAAIyaEHegP3A2ggEPIyLYptYU6HcqZU4PkQirgtF9rrx6u4liuDsU00S9FtQqUpHirQ; lt.sig=0j4upazV3vF7q1fuRiWmLRcAysE; uid=623858537; uid.sig=QYgsc2KoX0IE5UCtnTTMczMCHlc; _lxsdk=E2E23EC0639F11EB85E4D30A3B6992EFAE8CAAAE498A47ADBA934F1C1E2E4F74; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1612082396,1612082399,1612082404,1612082954; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1612082957; _lxsdk_s=1775795a907-a9a-b4e-d9%7C%7C31'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
logging.info('scraping %s successfully', url)
return response.text
logging.error('get invalid status code %s while scraping %s', response.status_code, url)
except requests.RequestException:
logging.error('error occurred while scraping %s', url, exc_info=True)
2.4 Parse HTML
# 解析html
def parse_html(response):
doc = pq(response)
divs = doc('.movie-item-info').items()
for div in divs:
name = div.find(".name>a").attr("title")
url = urljoin(BASE_URL, div.find(".name>a").attr('href'))
star = div.find(".star").text()
release_time = div.find(".releasetime").text()
yield {
'name': name,
'url': url,
'star': star,
'release_time': release_time
}
2.5 Save results
The first parameter is the query condition, that is, the query is based on the name;
the second parameter is the data object itself, which is the data used, here we use the $set operator to represent the update operation;
the third parameter is very important, here in fact It is the upsert parameter. If you set this to True, you can update if it exists or insert if it doesn't exist. The update will be based on the name field set by the first parameter, so it can prevent movie data with the same name from appearing in the database.
# 将数据保存到MongoDB
def save_data(data):
if data is not None:
collection.update_one({
'name': data.get('name')
}, {
'$set': data
}, upsert=True)
else:
logging.info("save_data fail... because data is none")
2.6 Multi-threaded crawling
# 多线程爬取
def multiprocess(offset):
response = get_index(offset)
# print(response)
results = parse_html(response) # 得到包含元组的迭代器
for result in results:
save_data(result)
2.7 Main function
if __name__ == '__main__':
# 开启多线程爬取
pool = multiprocessing.Pool(8)
offset = (0, 10, 20, 30, 40, 50, 60, 70, 80, 90)
pool.map(multiprocess, offset)
pool.close()
pool.join()
# 查看爬取结果
results = collection.find()
for result in results:
print(result)
print(collection.find().count())
2.8 Display of results
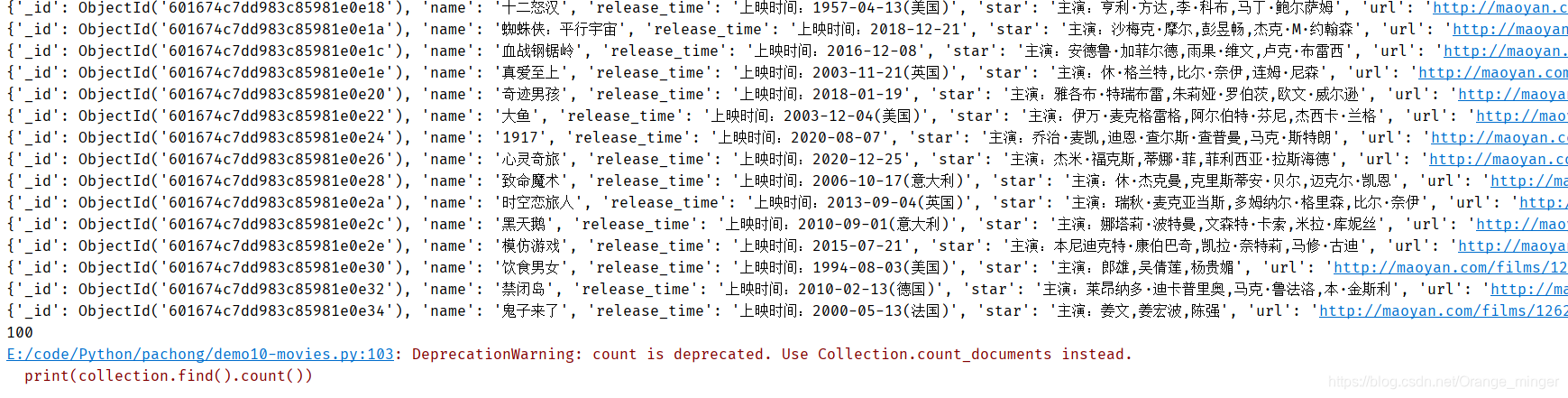
3. Complete code
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# Author: RuiMing Lin
# DateTime: 2021/01/25 15:56
# Description: 使用pyquery爬取猫眼电影网
import requests
import logging
import re
import pymongo
from pyquery import PyQuery as pq
from urllib.parse import urljoin
import multiprocessing
# 定义日志级别
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
# 根路径
BASE_URL = 'http://maoyan.com/board/4?offset='
# 总页数
TOTAL_PAGE = 10
# MongoDB配置信息
MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGO_DB_NAME = 'movies'
MONGO_COLLECTION_NAME = 'maoyan'
client = pymongo.MongoClient(MONGO_CONNECTION_STRING)
db = client[MONGO_DB_NAME]
collection = db[MONGO_COLLECTION_NAME]
# 爬取html
def get_html(url):
logging.info('scraping %s...', url)
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.3987.122 Safari/537.36",
"cookie": '__mta=150370569.1611503616862.1612082954043.1612082957903.9; uuid_n_v=v1; _lxsdk_cuid=1773519c23bc8-0a6c4c52255ba1-930346c-1fa400-1773519c23bc8; __mta=150370569.1611503616862.1611503616862.1611971356010.2; uuid=E2E23EC0639F11EB85E4D30A3B6992EFAE8CAAAE498A47ADBA934F1C1E2E4F74; _csrf=ef6eb066c57b86e4a0a1a2572572fda1cfe92c99d5df1b91c871877f74065d2b; lt=mfZ3gH4a-JGqb6SKtSLqZ_ylUqYAAAAApgwAAIyaEHegP3A2ggEPIyLYptYU6HcqZU4PkQirgtF9rrx6u4liuDsU00S9FtQqUpHirQ; lt.sig=0j4upazV3vF7q1fuRiWmLRcAysE; uid=623858537; uid.sig=QYgsc2KoX0IE5UCtnTTMczMCHlc; _lxsdk=E2E23EC0639F11EB85E4D30A3B6992EFAE8CAAAE498A47ADBA934F1C1E2E4F74; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1612082396,1612082399,1612082404,1612082954; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1612082957; _lxsdk_s=1775795a907-a9a-b4e-d9%7C%7C31'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
logging.info('scraping %s successfully', url)
return response.text
logging.error('get invalid status code %s while scraping %s', response.status_code, url)
except requests.RequestException:
logging.error('error occurred while scraping %s', url, exc_info=True)
# 拼接url,调用get_html(url)
def get_index(page):
url = f'{BASE_URL}{page}'
return get_html(url)
# 解析html
def parse_html(response):
doc = pq(response)
divs = doc('.movie-item-info').items()
for div in divs:
name = div.find(".name>a").attr("title")
url = urljoin(BASE_URL, div.find(".name>a").attr('href'))
star = div.find(".star").text()
release_time = div.find(".releasetime").text()
# logging.info('get detail url %s', detail_url)
yield {
'name': name,
'url': url,
'star': star,
'release_time': release_time
}
# 将数据保存到MongoDB
def save_data(data):
if data is not None:
collection.update_one({
'name': data.get('name')
}, {
'$set': data
}, upsert=True)
else:
logging.info("save_data fail... because data is none")
# 多线程爬取
def multiprocess(offset):
response = get_index(offset)
# print(response)
results = parse_html(response) # 得到包含元组的迭代器
for result in results:
save_data(result)
if __name__ == '__main__':
# 开启多线程爬取
pool = multiprocessing.Pool(8)
offset = (0, 10, 20, 30, 40, 50, 60, 70, 80, 90)
pool.map(multiprocess, offset)
pool.close()
pool.join()
# 查看爬取结果
results = collection.find()
for result in results:
print(result)
print(collection.find().count())