Foreword: This article is finishing blog evolved from numerous articles on RAID disk arrays, thank you seniors ~
What is RAID?
RAID (Redundant Array of Independent Disks) that is a redundant array of independent disks, commonly referred to as a disk array . Briefly, RAID composed of a plurality of independent high-performance disk drives in the disk subsystem, thereby providing higher performance than a single disk storage and data redundancy techniques.

RAID Category
RAID level can be divided into three categories: standard level, the level of non-standard and nested (combined) level. Standard RAID levels are RAID 0 ~ 6 grade seven, the most commonly used is 0,1,5 .
From the implementation point of view, RAID is divided into software RAID, hardware RAID and hard and soft Hybrid RAID three.
- Software RAID : Use RAID function provides host-based software, is implemented at the operating system level. Software RAID can affect system performance, and supports RAID levels. Compared with hardware RAID, software RAID with low cost and simple, intuitive advantages.
- Hardware RAID : comprises a hardware-based RAID and host-based hardware RAID array. It equipped with a special RAID control / processing chip and I / O buffer and an array processing chip, no CPU resources, but the high cost.
- Mixing hard and soft RAID : includes a RAID controller / processor chip, but the lack of I / O processing chip, CPU and the driver needs to accomplish, performance and cost between the soft and hard RAID RAID.
RAID principle
RAID two key objectives is to improve data reliability and I / O performance.
- Reliability . Disk array, the data dispersed in a plurality of disks, but for the computer system, as a separate disk. Redundancy is obtained by the same data is written to multiple disks (typically such as mirroring), the check data calculated or writes to the array when a single disk fails block ensures not cause data loss. Some RAID level allows more simultaneous failures, such as RAID6, two disks can be damaged at the same time. In such a redundancy mechanism to replace the failed disk with a new disk, RAID automatically based on the remaining data and parity data reconstruction of lost data disks to ensure data consistency and integrity.
- I / O performance . Dispersing a plurality of different data storage disks in the RAID, concurrent read and write data to be much better than a single disk, the polymerization can be higher I / O bandwidth. Of course, all disk array will reduce the total available disk storage space, sacrificing space for higher reliability and performance.
There are three main RAID key concepts and technologies: mirroring (Mirroring), data slice (Data Stripping) and parity data (Data parity).
- Mirror . Copying the data to a plurality of disks, one can improve the reliability, on the other hand can be complicated by two or more copies of the read data from the read to improve performance. Obviously, mirrored write performance to be slightly lower, to ensure that data is properly written to multiple disks need more time consuming.
- Data striping . The data fragments stored in multiple different disk, multiple data fragments together to form a complete copy of the data, which mirrors multiple copies are different, it is usually for performance reasons. Data strip having a particle size greater concurrency, when access to data, may be simultaneously located in different data on the disk read and write operations, to obtain very substantial I / O performance.
- Data validation . Using redundant data for error detection and repair data, redundant Hamming code data is commonly used, other algorithms to calculate the XOR operation is obtained. Using a check function, can greatly improve the reliability, robustness and fault-tolerant disk array. However, the data required to calculate and compare the checksum multiple reads data from and will affect system performance.
Different RAID levels use one or more of the above three techniques to obtain various data reliability, availability, and I / O performance. As for what model which uses RAID RAID (or even a new level or type) design or needs to be a reasonable choice in-depth understanding of the system requirements of the premise, comprehensive assessment of reliability, performance and cost trade-off choices
The main reference:
https://www.sohu.com/a/226786837_100128442 or http://www.360doc.com/content/18/0512/11/37015604_753316374.shtml ( on disk array, which is the most comprehensive I've seen, the best an article!)
https://baike.baidu.com/item/%E7%A3%81%E7%9B%98%E9%98%B5%E5%88%97/1149823?fr=aladdin ( Baidu Encyclopedia: Disk Array)
========================== dividing line ====================== ======
Common standards RAID
PS: marked red in the RAID is more commonly used, namely RAID 0,1,5,10
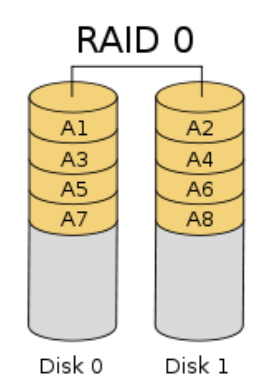
RAID 0 (stripe, Stripe)
The continuous n data dispersed to a hard disk access. Data request may be executed in parallel n disks, so that full use of the bus bandwidth, significantly improve the overall disk access performance. Theoretical single disk storage speed is n times (but due to various factors like the bus bandwidth, the actual performance is lower than the theoretical value)
The required number of disks:> = 2
Actual capacity: n * min (note:. N is the number of hard disks, min is a minimum capacity of a disk hereinafter)
Fault tolerance: None. Any one disk failure will cause all data unrecoverable.
Features: read and write performance of the RAID level best, maximum utilization of the hard disk (100%). But the least secure.
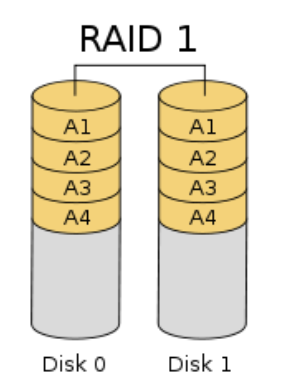
RAID 1 (mirroring, Mirror)
Block n (typically n = 2) are mirror images of hard disks for data redundancy. When a hard disk fails, put a new drive (> = the original hard disk capacity) and the recombinant automatically recover data RAID mode. When the original data is busy, data can be read directly from the mirrored copy, so RAID 1 can improve read performance.
The required number of disks:> = 2
Actual capacity: 1 * min
Fault Tolerance: Yes, up to n-1 drives bad
Features: to provide the best fault tolerance, but smaller-capacity hard disk is actually available, the lowest disk utilization (1 / n), the highest unit costs.
RAID 2 (Hamming code disk array)
The design idea is to use the Hamming code parity for data redundancy. The larger the data width, the higher the storage space utilization, but also the number of disks needed more. Have their own error correction capability, however, Hamming code data redundancy expenses are too high, data reconstruction is very time consuming, so RAID 2 in practice is rarely used .
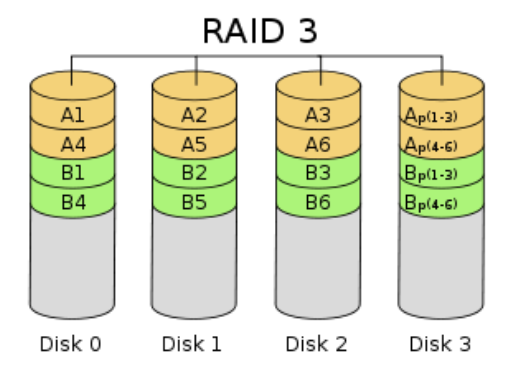
RAID3 (dedicated parity stripe)
A disk using a dedicated parity disk (parity disk), the remaining disk as a data disk, the data bit byte interleaved manner to the respective data disk. RAID3 disk requires at least three, with the same data in different areas on the disk for XOR parity, parity check value written to disk. When data is written to the RAID3, you must calculate the check value with all the same strip, and writes the new parity value check disk. A write operation comprising a write block, read data block with the strip, calculates the checksum value, write check value and other operating system overhead is very large, lower performance.
The required number of disks:> = 3
Actual capacity: disk utilization (n-1) / n
Fault tolerance: there
Features: Read and consistent performance RAID 0 intact, it also provides fault tolerance. But write large overhead. For random data, the parity disk will become a performance bottleneck.
RAID 4
Principle RAID4 and RAID3 about the same. It provides a very good read performance, but relatively poor write performance. And with the increase in the number of member disks, check disks system bottlenecks will become more prominent. In practice, rarely used.
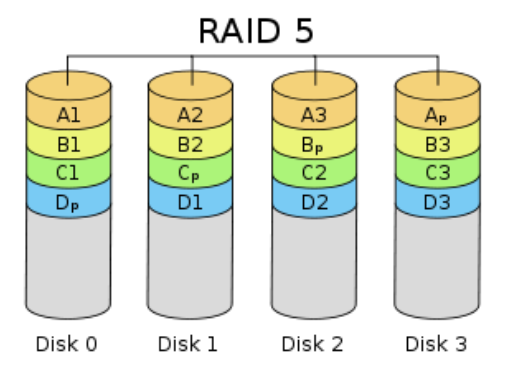
RAID 5 (distributed parity stripe)
RAID 5是RAID 0和RAID 1的折中方案。RAID5不对存储的数据做备份,而是把数据和相对应的奇偶校验信息存储到组成RAID 5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上。当RAID 5的一个磁盘数据发生损坏后,利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。
所需磁盘数:>=3
实际容量:(n-1)*min。磁盘利用率为(n-1)/n
容错能力:有,最多可坏1块硬盘
特点:写性能低,读性能高。利用奇偶校验进行冗余,可容错,安全性高。
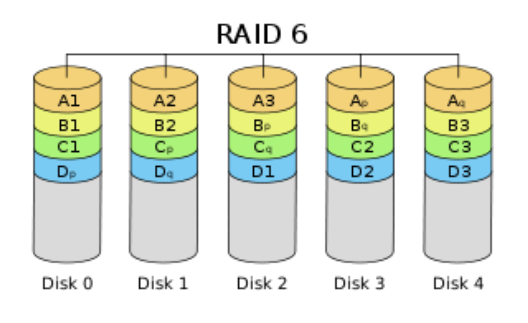
RAID 6(带双重分散校验的数据条带)
前面所述的各个 RAID 等级都只能保护因单个磁盘失效而造成的数据丢失。如果两个磁盘同时发生故障,数据将无法恢复。 RAID 6 引入双重校验的概念,它可以保护阵列中同时出现两个磁盘失效时,阵列仍能够继续工作,不会发生数据丢失。 RAID 6 等级是在 RAID 5 的基础上为了进一步增强数据保护而设计的一种 RAID 方式,它可以看作是一种扩展的 RAID 5 等级。
RAID 6 不仅要支持数据的恢复,还要支持校验数据的恢复,因此实现代价很高,控制器的设计也比其他等级更复杂、更昂贵。 RAID 6 思想最常见的实现方式是采用两个独立的校验算法,假设称为 P 和 Q ,校验数据可以分别存储在两个不同的校验盘上,或者分散存储在所有成员磁盘中。当两个磁盘同时失效时,即可通过求解两元方程来重建两个磁盘上的数据。
RAID 6 具有快速的读取性能、更高的容错能力。但是,它的成本要高于 RAID 5 许多,写性能也较差,并有设计和实施非常复杂。因此, RAID 6 很少得到实际应用,主要用于对数据安全等级要求非常高的场合。它一般是替代 RAID 10 方案的经济性选择。
所需磁盘数:>=4
实际容量:(n-2)*min。磁盘利用率为(n-2)/n
容错能力:有,最多可坏2块硬盘
特点:安全性非常高,主要用于对数据安全等级要求非常高的场合
========================分割线==========================
常用组合RAID
标准RAID等级各有优势和不足。把多个RAID等级组合起来,实现优势互补,弥补相互的不足,从而达到在性能、数据安全性等指标上更高的RAID系统。当然,组合等级的实现成本一般都非常昂贵,只是在少数特定场合应用。
实际得到较为广泛应用的只有RAID01和RAID10两个等级。RAID 10 和 RAID 01 的区别:

参考:
https://wenku.baidu.com/view/e3f5569ab52acfc789ebc9c8.html (各种Raid区别与解释)
RAID 10模式(镜像+条带)
RAID 10 是 RAID 1 和 RAID 0 的组合体。RAID 10技术需要至少四块硬盘来组建,其中先分别两两制作成RAID 1磁盘阵列,以保证数据的安全性;然后再对两个RAID 1磁盘阵列实施RAID 0技术,进一步提高硬盘设备的读写速度。这样子从理论上讲,只要坏的不是同一组中的所有硬盘,那么最多可以损坏50%的硬盘设备而不丢失数据。由于RAID 10技术继承了RAID 0的高读写速度和RAID 1的数据安全性。
所需磁盘数:>=4 (偶数)
实际容量:(n/2)*min
容错能力:有,每个RAID 1组最多可坏1块硬盘
特点:兼顾性能和安全性,但磁盘利用率低(50%)

主要参考:
https://www.hack520.com/169.html(图文并茂 RAID 技术全解 – RAID0、RAID1、RAID5、RAID100……)
https://blog.csdn.net/weixin_38808609/article/details/81663621 (常见RAID的各级别的特性简介(RAID0、1、5、6、10))
http://www.05bk.com/68.html (RAID技术讲解-RAID0、RAID1、RAID3、RAID5、RAID6、RAID10对比)
========================分割线==========================
常用RAID的对比

(参考的图忘了出处,侵删~)
========================完结撒花==========================