P(y|X)=P(y)*P(X|y)/P(X)
Sample attributes are independent;
![]()
The problem is equivalent to the original problem:

The data processing
in order to prevent P (y) * P | underflow value (X y), the logarithm of the original question, namely:

Note: If the value of a property not seen in the training set and at the same time a class, directly P (y) or P (X | y) may be 0, so that the calculated P (y) * P (X | y) of is 0, are not comparable, and inconvenient to find the number of probability values is required for "smoothing" process, commonly Laplace correction.
Fixed priori probabilities: Let D Dy represents the training set the combination of the sample set of classes y, N represents the number of the training set of possible categories D

I.e., the number of samples in each category are added 1.
The class conditional probability: Another Dy, xi represents the value set as Dc sample xi is formed on the i-th attribute, Ni denotes the i th attribute values of the number of possible
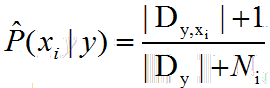
That is, the i-th attribute category have increased a sample.
--------------------------------------------------------------
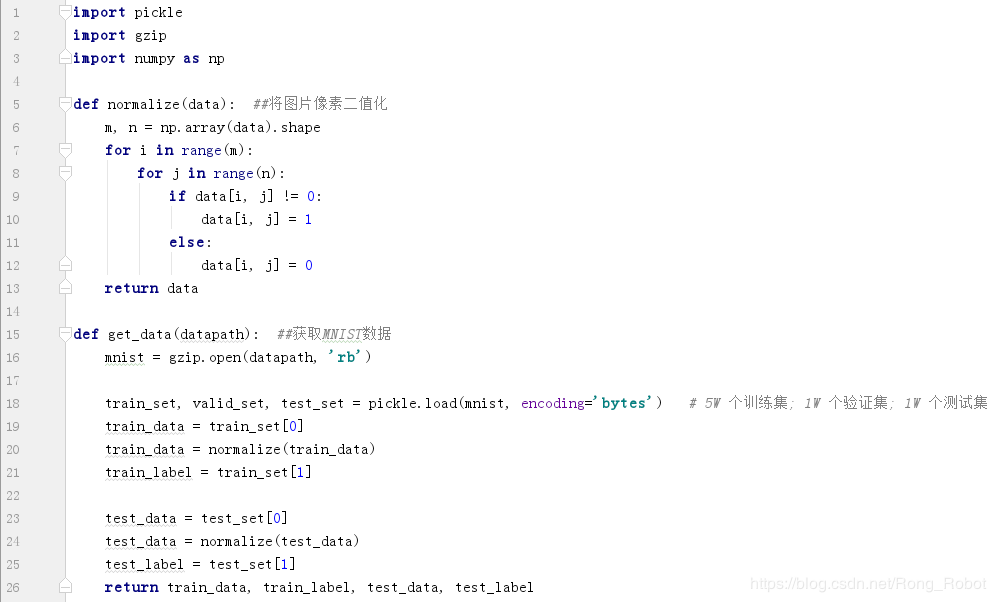
Data preprocessing
Trainer

Test samples

Function call

reference
python naive Bayes classifier MNIST datasets
struct Import
from numpy Import *
Import numpy AS NP
Import Time
DEF read_image (file_name):
# first binary mode to read all the documents come in
file_handle = open (file_name, "rb ") # binary open the document
file_content = file_handle.read () # read into the buffer
offset = 0
head struct.unpack_from = ( '> IIII', FILE_CONTENT, offset) to take before # 4 integer, returns a tuple
offset + = struct.calcsize ( '> IIII')
imgNum = head [1] # image number
rows = head [2] # width
cols = head [3] # height
images = np.empty ((imgNum, 784 )) # empty, it is common to all the elements within the array are empty, there is no practical significance, it is the fastest way to create an array of
image_size = rows * cols # single picture of the size of
fmt = '>' + str ( image_size) + 'B' # single image format
for i in (imgNum) the Range :
Images [I] = np.array (struct.unpack_from (FMT, FILE_CONTENT, offset))
# Images [I] = np.array (struct.unpack_from (FMT, FILE_CONTENT, offset)). the RESHAPE ((rows, cols))
+ = struct.calcsize offset (FMT)
return Images
# read tag
DEF read_label (file_name):
file_handle = open (file_name, "RB") # open the document in binary
file_content = file_handle.read () # read into the buffer
head = struct.unpack_from ( '> II' , file_content, 0) # take the first two integers, returns a tuple
offset = struct.calcsize ( '> II')
labelNum head = [. 1] label number #
# print (labelNum )
bitsString = '>' + STR (labelNum) + 'B' format FMT #: '> 47040000B'
label = struct.unpack_from (bitsString,file_content, offset) # fetch data data, returns a tuple
return NP.array(label)
def loadDataSet():
#mnist
train_x_filename="train-images-idx3-ubyte"
train_y_filename="train-labels-idx1-ubyte"
test_x_filename="t10k-images-idx3-ubyte"
test_y_filename="t10k-labels-idx1-ubyte"
# #fashion mnist
# train_x_filename="fashion-train-images-idx3-ubyte"
# train_y_filename="fashion-train-labels-idx1-ubyte"
# test_x_filename="fashion-t10k-images-idx3-ubyte"
# test_y_filename="fashion-t10k-labels-idx1-ubyte"
train_x=read_image(train_x_filename)#60000*784 的矩阵
train_y=read_label(train_y_filename)#60000*1的矩阵
test_x=read_image(test_x_filename)#10000*784
test_y=read_label(test_y_filename)#10000*1
= the normalize train_x (train_x)
test_x = the normalize (test_x)
# # debug time for speed quickly on, then reduce the size of the data set
# train_x = train_x [0: 1000 ,:]
# train_y = train_y [0: 1000]
# test_x test_x = [0: 500 ,:]
# test_y test_y = [0: 500]
return train_x, test_x, train_y, test_y
DEF the normalize (Data): # binarized image pixels, the distribution becomes 0-1
m = data.shape [0]
n-np.array = (Data) .shape [. 1]
for I in Range (m):
for J in Range (n-):
! IF Data [I, J] = 0:
Data [I, J] = . 1
the else:
Data [I, J] = 0
return Data
# (. 1) calculates a conditional probability and prior probability
DEF train_model (train_x, train_y, classNum): # classNum means 10 categories, train_x here is already binarized,
m = train_x.shape [0]
n-train_x.shape = [. 1 ]
# = np.zeros prior_probability (n-) # priori probability
prior_probability = np.zeros (classNum) # priori probability
conditional_probability = np.zeros ((classNum, n , 2)) # conditional probability
# priori and conditional probabilities calculated
for i in range (m ): # m is the number of images, a total of 60,000
img = train_x [i] #img is the i-th picture, is 1 * n row vector
label = train_y [i] #label the i-th image corresponding to the label
prior_probability [ label] + label number (p (Y = ck) = 1 # statistics class label, for storing the subscript label, prior_probability [label] divided by n is a class prior probabilities
for j in range (n): #n is characteristic number, a total of 784
temp = img [j] .astype ( int) #img [j] is 0.0, the subscript go into an error is displayed only integer
conditional_probability [label] [J] [TEMP] +. 1 =
# (2) given x, conditional probability and prior probability calculating the product of
# conditional_probability [label] [J] [IMG [J]] = 1 + # statistics class label is in each column the number of rows is the number 1 or 0 , img [j] value is either 0 or 1 is calculated conditional probability
# Probability normalized to [1.10001]
for I in Range (classNum):
for J in Range (n-):
# binarized image only two values 0
pix_0 = conditional_probability [i] [j ] [0 ]
pix_1 conditional_probability = [I] [J] [. 1]
# 0 corresponding pixels calculated conditional probability
probability_0 = (a float (pix_0) / a float (pix_0 pix_1 +)) * 10000 +. 1
probability_1 = (a float (pix_1) / a float (pix_0 + pix_1)) * 10000 +. 1
conditional_probability [I] [J] [0] = probability_0
conditional_probability [I] [J] [. 1] = probability_1
return prior_probability, conditional_probability
cal_probability DEF (IMG, label, prior_probability, conditional_probability):
Probability = int (prior_probability [label]) # priori probabilities
n-img.shape = [0]
# Print (n-)
for I in Range (n-): # characteristics should be number
Probability * = int (conditional_probability [label] [I] [IMG [I] .astype (int)])
return Probability
# x instance of the class is determined, corresponding to the argmax
DEF Predict (test_x, test_y, prior_probability, conditional_probability): # after passed in test_x or train_x are binarized
predict_y = []
m = test_x.shape [0]
n-test_x.shape = [. 1]
for I in Range (m):
IMG = np.array (test_x [ i]) # img already binarized after column vector
label = test_y [I]
max_label = 0
max_probability = cal_probability (IMG, 0, prior_probability, conditional_probability)
for J in Range (1,10): # 1 start at index is, because the initial value of the subscript 0
probability=cal_probability(img,j,prior_probability,conditional_probability)
if max_probability<probability:
max_probability=probability
max_label=j
predict_y.append(max_label)#用来记录每行最大概率的label
return np.array(predict_y)
def cal_accuracy(test_y,predict_y):
m=test_y.shape[0]
errorCount=0.0
for i in range(m):
if test_y[i]!=predict_y[i]:
errorCount+=1
accuracy=1.0-float(errorCount)/m
return accuracy
if __name__=='__main__':
classNum=10
print("Start reading data...")
time1=time.time()
train_x, test_x, train_y, test_y=loadDataSet()
train_x=normalize(train_x)
test_x=normalize(test_x)
time2=time.time()
print("read data cost",time2-time1,"second")
print("start training data...")
prior_probability, conditional_probability=train_model(train_x,train_y,classNum)
for i in range(classNum):
print(prior_probability[i])#输出一下每个标签的总共数量
time3=time.time()
print("train data cost",time3-time2,"second")
print("start predicting data...")
predict_y=predict(test_x,test_y,prior_probability,conditional_probability)
time4=time.time()
print("predict data cost",time4-time3,"second")
print("start calculate accuracy...")
acc=cal_accuracy(test_y,predict_y)
time5=time.time()
print("accuarcy",acc)
print("calculate accuarcy cost",time5-time4,"second")