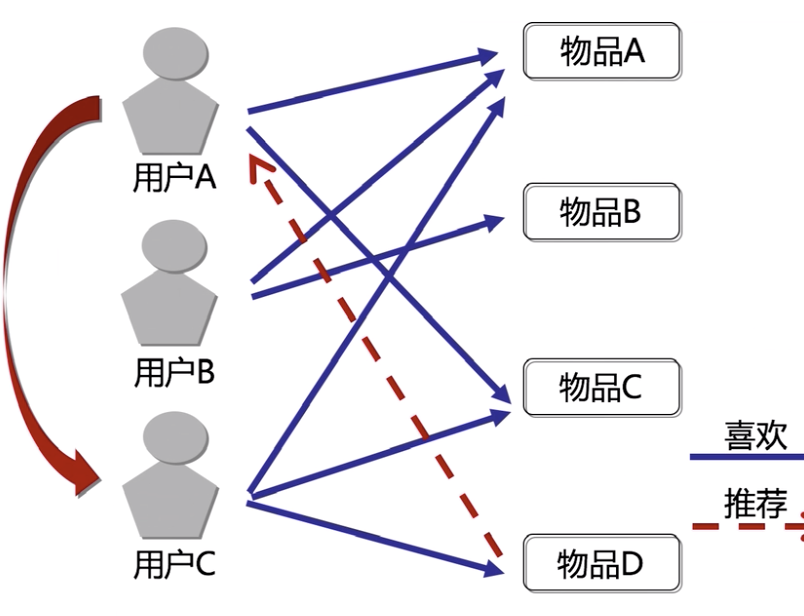
Collaborative filtering collaborative filtering
In human clustering, in groups was
Similarity
1. Jaccard similarity
It is defined as the ratio of the cross and two sets of:
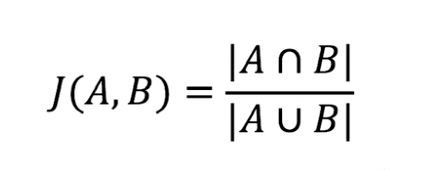
Jaccard distance, defined as 1 - J (A, B), two sets of discrimination measure:
![]()
Why Jaccard is not suitable for collaborative filtering? - consider only the user has not read, did not consider the size scores
2. cosine similarity
The cosine of the angle between the two vectors used to measure the similarity:

Why cosine similarity is not suitable for collaborative filtering? - the sum of scores of different users is not the same, resulting in the same total score than not, the opposite may be calculated and the result of the fact.
3. Pearson similarity
Resolve discrepancies similarity in cosine similarity, also known as the center of the cosine algorithm. To center, re-calculate the cosine similarity, and positive values indicate a positive correlation, a negative value indicates a negative correlation.
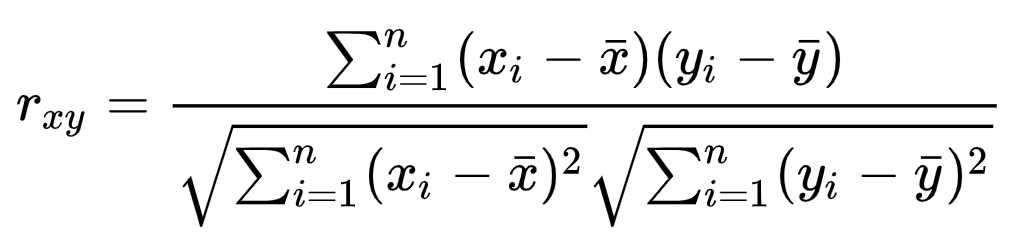
Collaborative filtering based on the user
To measure and score the extent favorite items by the user. Recommended for the same commodity or commodities based on the contents of the attitude of different users.
Illustration, each row vector indicates that a user rating of all movies

Of the first data center

A user then calculated Pearson correlation coefficient and other user:

It can be found in user A and user B preference close, so B can be like but never seen A recommendation to the chamber A, but also can be A, but B likes not seen Goblet recommend to B.
Users law issues exist:
1. Data sparsity. Too many items, buy items overlap between different users are less, making it impossible to find a similar user preferences
2. The algorithm scalability. Nearest neighbor algorithm calculates the amount of users increases and the number of items is increased, is not suitable for the case of using a large amount of data.
Collaborative filtering items based on
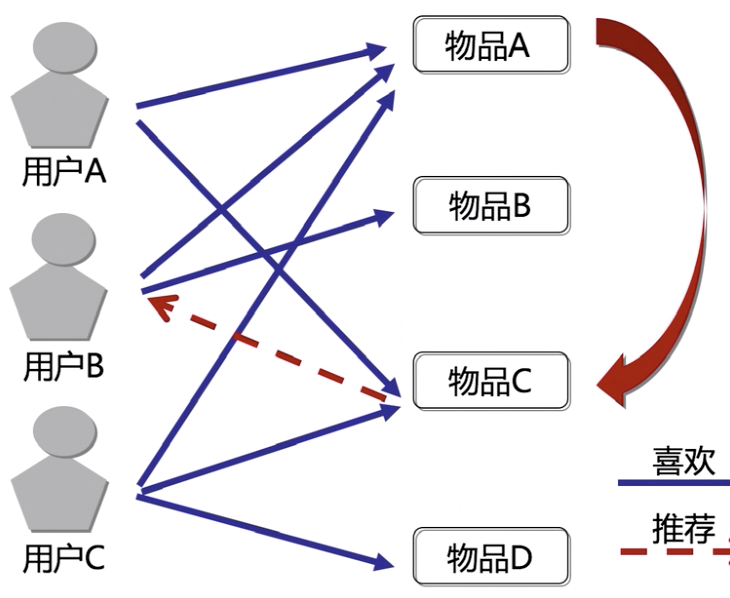
By calculating the scores for different users different items, obtain the relationship between objects. The relationship between the items recommended by the user based on similar items.
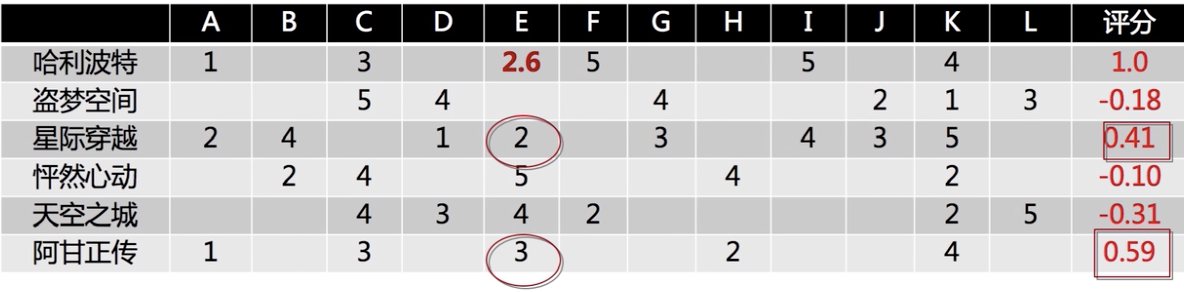
Illustration, each represented by a row vector of each article is a user rating, the first center of

How to predict the degree of preference of the user E Harry Potter? Pearson correlation coefficient between the calculated and the other Harry Potter movies

Relevance significant other movie, to come up with a user score of E these films, using the Pearson correlation coefficient do weighted sum:
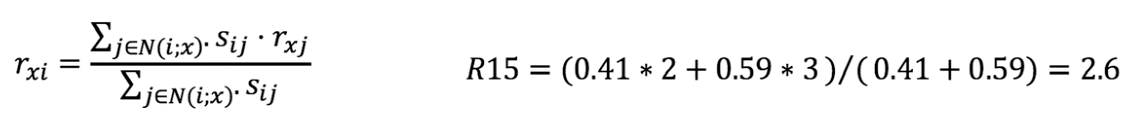
从原理上看,基于用户或基于物品都是可以的,但实践中以物品为基础效果更好,且需要很少的数据就可以进行预测,用户法需要大量数据。
SVD 协同过滤
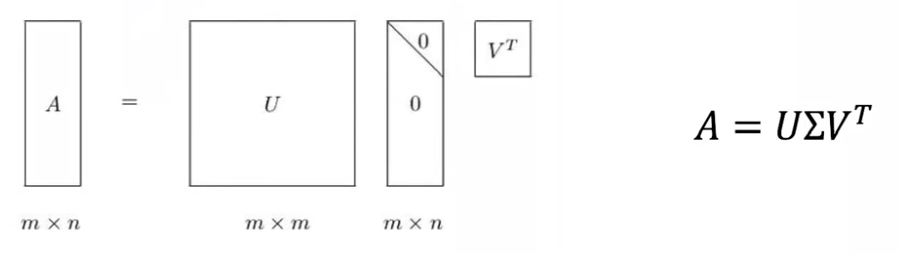
奇异值矩阵的特征值按照从大到小排列且迅速减小,可以把大矩阵用三个小矩阵来近似描述,实现降维和去噪,应用于协同过滤中可以减少计算量。
用 K 维 SVD 分解做协同过滤,实际上就是找一组 latent variables,U 和 V 分别描述了物品与隐变量、用户与隐变量之间的关系。 然后就可以都在 latent space 中表示。
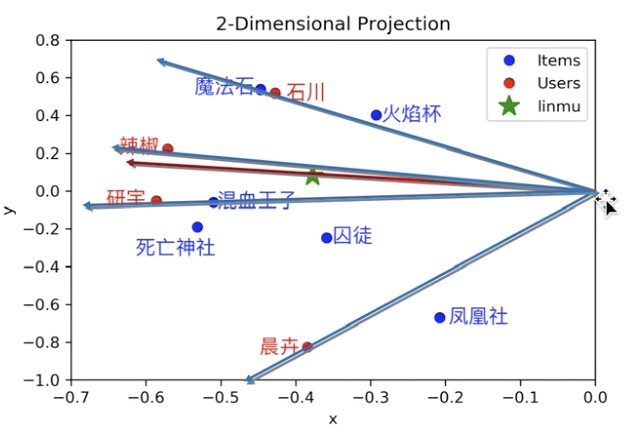
举例说明,4 个用户对 6 部电影的评分情况
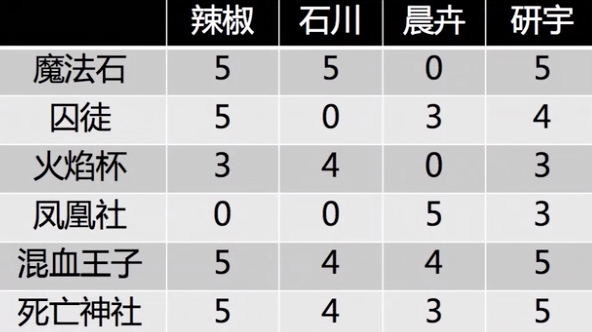
做二维 SVD 分解:

在 latent space 中表示用户和电影,发现电影之间、用户之间、电影和用户之间,都可以衡量中心余弦相似度。
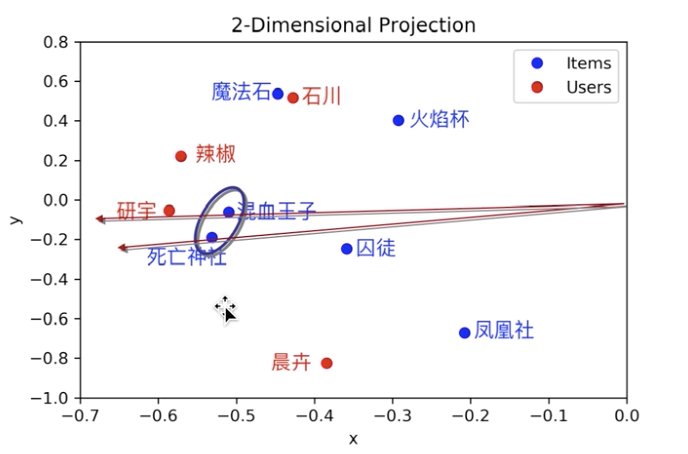
如果出现一个新用户,如何给他推荐他没有看过的电影?

把新用户投影到 latent space

找到和新用户相似度高的用户,把相似用户评分高而新用户没看过的电影,按相似用户的评分高低顺序先后推荐给新用户即可。