Basic information :
Website: plain text file, which is the programming language HTML, is displayed in the user's browser in the "translated" into a web page
Website: is composed of a page, is a combination of multiple pages
Home: After opening the first page website called website home page (or home page index.html)
Domain Name: Enter the URL when browsing the web (for example www.baidu.com)
HTTP: communication protocol used to transmit web pages (Hypertext Transfer Protocol)
URL: one kind of web addressing system (Uniform Resource Locator)
Http://www.baidu.com.:80/jpg/1.jpg
{kind=link}
HTML: Web page used to write HTML
Hyperlinks: The linked web sites in different functions
Published (online): The process of making good web upload to the server for user access
A full HTTP request process
When we enter in the web browser address bar: www.baidu.com, then enter, in the end what happened?
Process Overview
1. www.baidu.com this URL DNS lookup to obtain the corresponding IP address
2. According to this IP, find the corresponding server initiates the TCP three-way handshake
3. After establishing a TCP connection sends an HTTP request
4. The HTTP server responds to the request, the browser html code to obtain
The browser parses the html code and requests html code resources (such as js, css pictures, etc.) (first get html code to find these resources)
6. browser page rendering presented to the user
Note:
1.DNS DNS uses a recursive query mode, the process is to first go to the DNS cache -> Cache went root name server can not find -> Root domain name will go to the next level, after this recursive search, We found, to our web browser
2. Why HTTP protocol should be implemented based on TCP? TCP is a reliable protocol surface of an end to end connection, HTTP based on the TCP transport layer protocols need not worry about the problems of data transmission (when an error occurs, a retransmission)
3. The final step is the browser how the page is rendered? a) parsing a DOM tree of html files, b) parse tree rendering CSS file configuration, c) edge parsing, rendering side, D) JS single thread, it is possible to modify the DOM structure JS, JS means before the execution is completed, all subsequent resources the download is not necessary, so the JS is single-threaded, can clog up resources download
Let's take a detailed look at the specific details of these procedures:
1. Domain Name
a) will first search the browser's own DNS cache (cache relatively short time, only about one minute, and can only accommodate 1000 Cache)
b) If the browser itself is not found inside the cache, then the browser will search the system's own DNS cache
c) if it is not found, then try to find the hosts file inside
d) In the case of the foregoing three processes have not acquired, recursively go to the DNS server lookup procedure is as follows
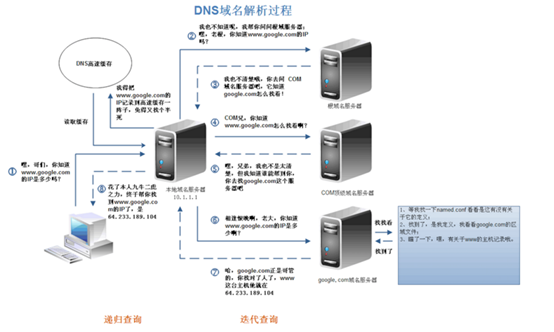
DNS optimization: two aspects: DNS cache, DNS Load Balancing
2.TCP connection (three-way handshake)
After the domain name to get the corresponding IP address, User-Agent (generally refers browser) will be a random port (1024 <port <65535) to the WEB application server (commonly used httpd, nginx) 80 port like. After the connection request (the original http request through TCP / IP4 layer packet-layer model) to the server (middle various routing devices, except for the LAN), into the card, then the kernel into a TCP / IP protocol stack (for identifying a connection request, a depacketizer, the peel layer by layer), it is also possible to go through the firewall Netfilter (belonging to the kernel module) filter, eventually reaches WEB program, eventually established TCP / IP connection
Graphic:

3. establish a TCP after a connection, initiate HTTP requests
HTTP request consists of three parts: the request line, request headers and the request body
Request line: the manner described for requesting the client, the version number of the resource request and the name used by the HTTP protocol (Example: GET / books / java.html HTTP / 1.1)
请求头:用于描述客户端请求哪台主机,以及客户端的一些环境信息等
注:这里提一个请求头 Connection,Connection设置为 keep-alive用于说明 客户端这边设置的是,本次HTTP请求之后并不需要关闭TCP连接,这样可以使下次HTTP请求使用相同的TCP通道,节省TCP建立连接的时间
请求正文:当使用POST, PUT等方法时,通常需要客户端向服务器传递数据。这些数据就储存在请求正文中(GET方式是保存在url地址后面,不会放到这里)
4.服务器端响应http请求,浏览器得到html代码
HTTP响应也由三部分组成:状态码,响应头和实体内容
状态码:状态码用于表示服务器对请求的处理结果
列举几种常见的:200(没有问题) 302(要你去找别人) 304(要你去拿缓存) 307(要你去拿缓存) 403(有这个资源,但是没有访问权限) 404(服务器没有这个资源) 500(服务器这边有问题)
若干响应头:响应头用于描述服务器的基本信息,以及客户端如何处理数据
实体内容:服务器返回给客户端的数据
注:html资源文件应该不是通过 HTTP响应直接返回去的,应该是通过nginx通过io操作去拿到的吧
5.浏览器解析html代码,并请求html代码中的资源
浏览器拿到html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这是时候就用上 keep-alive特性了,建立一次HTTP连接,可以请求多个资源,下载资源的顺序就是按照代码里面的顺序,但是由于每个资源大小不一样,而浏览器又是多线程请求请求资源,所以这里显示的顺序并不一定是代码里面的顺序。
6.浏览器对页面进行渲染呈现给用户
最后,浏览器利用自己内部的工作机制,把请求的静态资源和html代码进行渲染,渲染之后呈现给用户
浏览器是一个边解析边渲染的过程。首先浏览器解析HTML文件构建DOM树,然后解析CSS文件构建渲染树,等到渲染树构建完成后,浏览器开始布局渲染树并将其绘制到屏幕上。这个过程比较复杂,涉及到两个概念: reflow(回流)和repain(重绘)。DOM节点中的各个元素都是以盒模型的形式存在,这些都需要浏览器去计算其位置和大小等,这个过程称为relow;当盒模型的位置,大小以及其他属性,如颜色,字体,等确定下来之后,浏览器便开始绘制内容,这个过程称为repain。页面在首次加载时必然会经历reflow和repain。reflow和repain过程是非常消耗性能的,尤其是在移动设备上,它会破坏用户体验,有时会造成页面卡顿。所以我们应该尽可能少的减少reflow和repain。
JS的解析是由浏览器中的JS解析引擎完成的。JS是单线程运行,JS有可能修改DOM结构,意味着JS执行完成前,后续所有资源的下载是没有必要的,所以JS是单线程,会阻塞后续资源下载
自此一次完整的HTTP事务宣告完成.
总结:
域名解析 --> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求,浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户