
arXiv-2016
Keras code:https://github.com/titu1994/Wide-Residual-Networks
Article Directory
- 1 Background and Motivation
- 2 Advantages / Contributions
- 3 Method
- 4 Experiments
- 4.1 Datasets
- 4.2 Type of convolutions in a block
- 4.3 Number of convolutions per block
- 4.4 Width of residual blocks
- 4.5 Dropout in residual blocks
- 4.6 ImageNet and COCO experiments
- 4.7 Computational efficiency
- 5 Conclusion(owns)
1 Background and Motivation
ResNet 能训练上千层的网络,然而 each fraction of a percent of improved accuracy costs nearly doubling the number of layers, and so training very deep residual networks has a problem of diminishing feature reuse, which makes these networks very slow to train.
Exploration of the residual focused on
- order of activations inside a ResNet block(bottleneck)
- depth of residual networks
From the point of view of width, he began his story. . .
The authors point out the pros and cons of identity connection,
- 利:train very deep convolution networks
- Disadvantages: as gradient flows through the networks there is nothing to force it to go though residual block weights, ha ha, easy to become Hunzi the residual block!
This (harm) than the stars of Pegasus, the paper "Deep networks with stochastic depth" to randomly disabling residual blocks during training, the effectiveness of the approach confirmed the author's hypothesis.
2 Advantages / Contributions
- Proposed wide residual network, is the result of residual exploration in terms of width
- Proposed a new way of utilizing dropout, insert between convolutional layer rather than the inner residual block ( "Identity Mappings in Deep Residual Networks" paper latter effect is not good, as shown below),
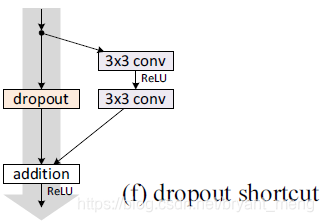
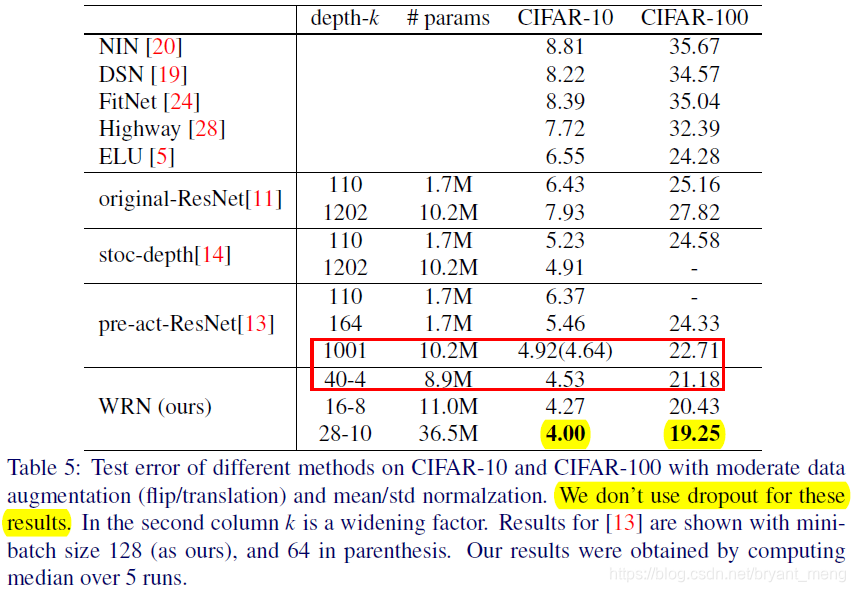
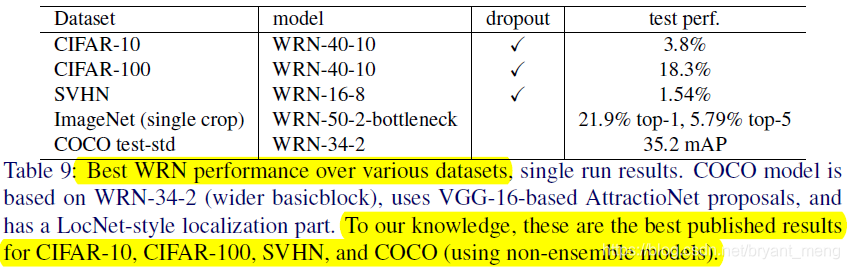
- state-of-the-art results on CIFAR-10, CIFAR-100, SVHN and COCO, on ImageNet also significant improvements!
3 Method
We first review under the resnet original structure ( "Deep Residual Learning for Image Recognition ")
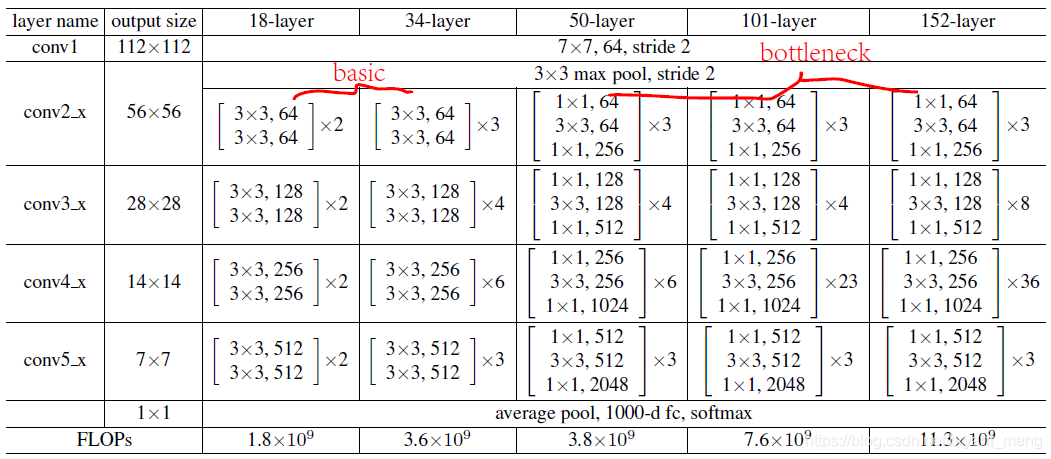
and then look back at pre-activation of resnet version ( "Deep in the Identity Mappings Residual Networks")

Full pre-activation best results, this paper describes the blog They are used in the structure (e) of FIG, i.e. the sequence of BN-ReLU-conv
Haha, hindsight says (standing in the second half of 2019 to evaluate the results of 2016), this is a parameter adjustment of the paper, and did not change the nature of the structure, of course, can be said that a large complex to simple Ha (but it is still super multi harvested)!
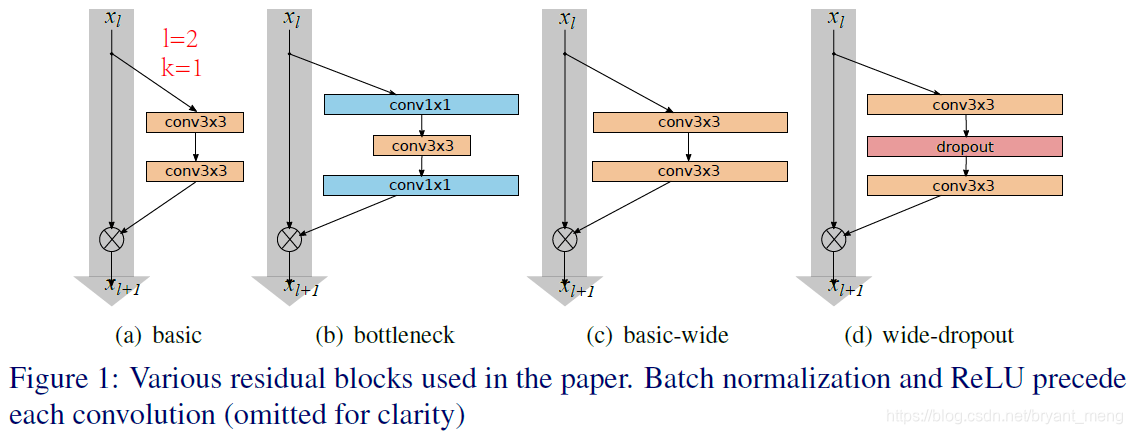
three simple way to increase representational power of residual blocks(上图就是 residual blocks):
- more layers per block——deepening factor
- widen layers by adding more feature planes——widening factor
- increase filter sizes(eg:3×3→5×5)
1)Type of convolutions in residual block
表示 residual block,
is a list with the kernel sizes of the convolutional layers in a block.

2) Number of convolutional layer per residual block
To ensure the same parameters, so should decrease whenever increases.
3) Width of residual blocks
WRN- - : 是 total depth,widening factor
4) Dropout in residual blocks
After more wider parameters, the authors would like to study ways of regularization, it is used in the form of dropout
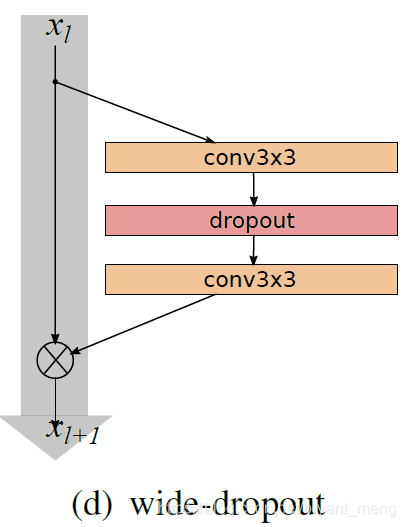
can help deal with diminishing feature reuse problem enforcing learning in different residual blocks
Contrast dropout under the "Identity Mappings in Deep Residual Networks" paper usage
Here the author explains why the BN at the time also with dropout, read on anyway, not the special feeling (not particularly agree! There are arguments that the role of bn is dropout, interested can discuss this issue! Both regularization effect, here initiate omitted)
Residual networks already have batch normalization that provides a regularization effect, however it requires heavy data augmentation, which we would like to avoid, and it’s not always possible.
4 Experiments
4.1 Datasets
- CIFAR-10
- CIFAR-100
- svhn
- ImageNet
- COCO
4.2 Type of convolutions in a block
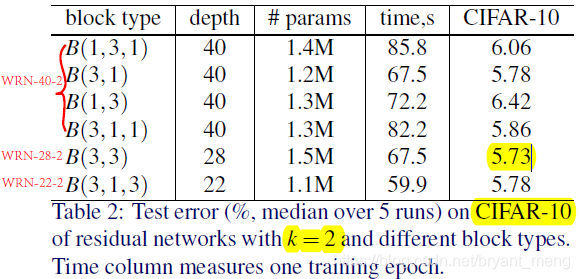
WRN-
-
:
是 total depth,widening factor
accuracy best, and the accuracy and which is similar to, but much less parameters, the fastest! Authors follow behind the way! ! !
4.3 Number of convolutions per block
deepening factor
(the number of convolutional layers per block)

WRN-40-2,same parameters(2.2M),3×3 convolution 堆叠
Preferably, the ratio of , are good, the author analyzes this is probably due to the increased difficultyThat is, the same depth, depth = 40, due to the depth of the residual block is not the same, so the identity connection the fewer the number, the authors feel that this is not conducive to optimization.
Authors follow behind the way! ! !
4.4 Width of residual blocks
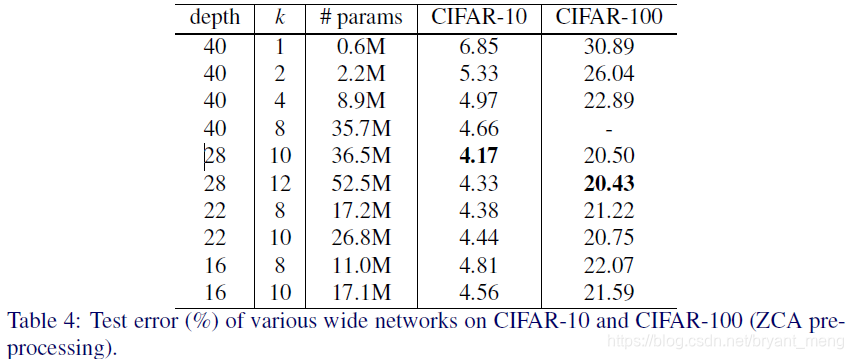
Comparison among the two red box, of WRN IS-40-4. 8 Times Faster Faster to Train, SO evidently The depth to width ratio in Original
Thin IS FAR from residual Optimal Networks.

The solid line test error, the broken line train error, the abscissa Epoch, legends wrong feeling, ha, the yellow part of the subject
4.5 Dropout in residual blocks
ON ON CIFAR 0.4 and 0.3 SVHN
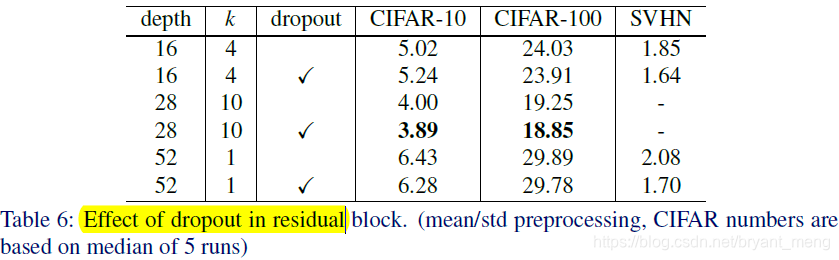
WRN-16-4 decreased, the authors speculate is due to the relatively small number of parameters.
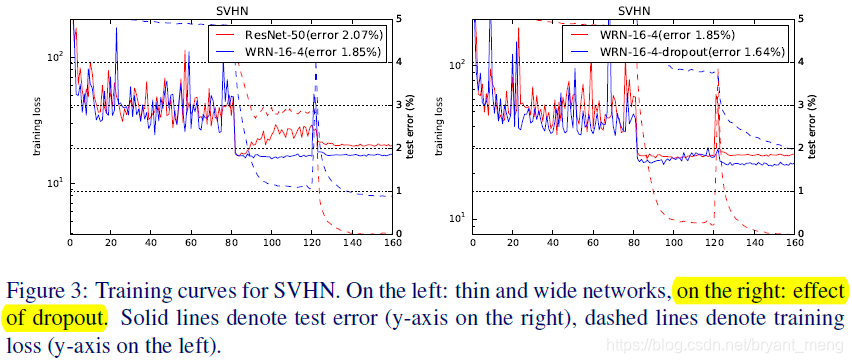
The authors found that when the train resnet, train loss would suddenly rise, it is caused by weight decay, but the weight decay little tune, acc will drop a lot, the authors found that dropout can solve this problem! ! ! Compare FIG. 3 dashed line on the right red and blue!
The author believes, This is probably due to the fact that we do not do any data augmentation and batch normalization overfits, so dropout adds a regularization effect. Because there is no dropout, train loss would drop particularly low!
Overall, despite the arguments of combining with batch normalization, dropout shows itself as an effective techique of regularization of thin(k=1) and wide(k>1) networks.
4.6 ImageNet and COCO experiments
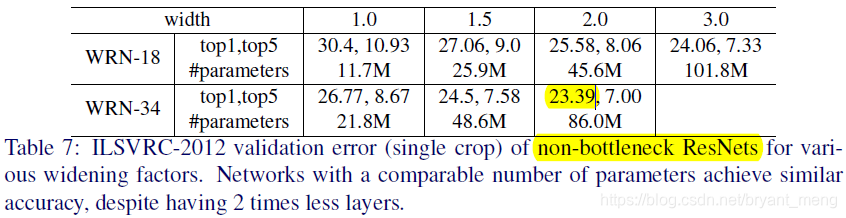

Here WRN-50-2-bottleneck Is the resnet-50 width double yet?
becomes
or
?
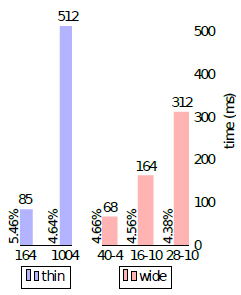
4.7 Computational efficiency

5 Conclusion(owns)
-
diminishing feature reuse problem is mentioned several times, also the author of the important problems to solve, feeling refers to the introduction of identity connection, the residual block may cause problems soy sauce!
-
wide residual networks are several times faster to train.
-
Authors repeatedly referred to the regularization effect, eg: bn, dropout, width, length can add regularization effect, a good understanding of the first two, the latter two not understand yeah, there regularization, let generalization performance better? To better performance? From this point of understanding?

-
This article width only from the start, "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks" on this from the depth, width