Article Directory
First, the paper-related information
1. Topic
YOLOv3: An Incremental Improvement
2. Paper Time
2018
3. Paper Documents
4. Paper Source
pytroch
Second, the introduction and background papers
YOLO v3 is not much innovation, but the integration of some of the better points elsewhere to YOLO v2 inside, making YOLO v2 get a better upgrade. YOLO v3 mainly in three aspects YOLO v2 improved.
- Multi-scale object detection features
- Modify the basic network architecture
- Object classification Logistic replaced softmax.
Meanwhile, the authors of the papers as technical reports to write, emmmm, style ... very funny.
Three, YOLO v3 series of improvements
1, Predictions Across Scales (feature-size)
We know YOLO v2 and earlier feature map are downsampled 32-fold after the operation. Meanwhile, to achieve fine-grained detection, the first two layers of the predicted characteristic is connected to the output of FIG. It is in this context of expansion, respectively, 16 times down-sampling and down-sampling feature map hands eight times.
Let comb, input is assumed 416 * 416, the corresponding down-sampled 32 times, 16 times, 8 times wherein FIG respectively (13,13),(26,26),(52,52).
When the network structure according YOLOv2 obtained (13,13)after feature map, for the obtained sampling feature map (26,26)feature map, while the previously generated (26,26)feature is added to the characteristic diagram in FIG, this will achieve the passthrough YOLO v2, strengthen the fine-grained detection. Similarly, again sampled on the (52,52)feature map, and then in front of the network (52,52)of FIG plus features. So, we finally, the three characteristics is obtained in FIG size ( (13,13),(26,26),(52,52)),
then normal processing (prediction detection frame) we are again three characteristic diagram
it is to be noted that, YOLO v2 in FIG prediction feature when, by piror anchor, then we are of different sizes, features three different fine-grained map of how to choose anchor it?
Analysis by K-means clustering, the set K = 9, were selected in three different sizes size (medium and small). The final OF obtained size (10 × 13), (16 × 30), (33 × 23), (30 × 61), (62 × 45), (59 × 119), (116 × 90), (156 × 198), (373 × 326 ). Just used on three different characteristics in FIG.
Of course, since (13,13)the sampling characteristic of FIG. 32 times, large receptive fields, and therefore a high possibility of large objects can be predicted, and therefore a large use of three anchor to processing the characteristic of FIG.(26,26),(52,52)The Select, a small anchor.
This method greatly solve the problem YOLO v2 on small objects difficult to predict. Look at the results of the experimental data.
2、Feature Extractor
Author draws on popular thinking resNet, and added to the original darkNet residual connections, and expand the network to 53 layers, which greatly improves the accuracy.


3、Class Prediction
Another problem is that some labels focus picture of multiple data, such as women and people. Softmax substantially the default output is a single label, so instead of using Logistic softmax to implement multiple label classification.
Fourth, the experimental results
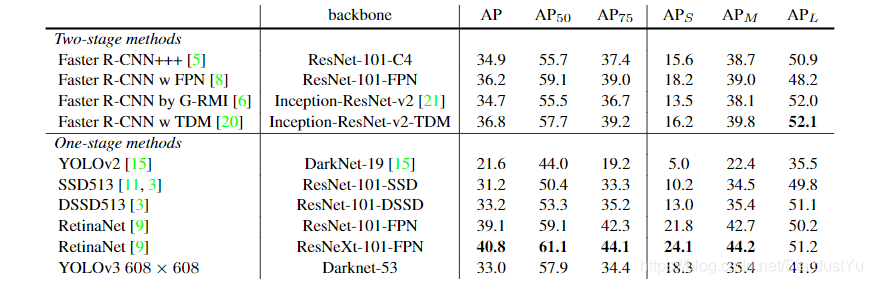
SSD higher precision than on, and the time three times faster than the SSD
Fifth, the advantages and disadvantages
According to the results, we can see YOLO v3 compared to YOLO v2 greatly improves accuracy, but compared to RetinaNet. Precision or not, but fast.
Compared to YOLO v2, you can see YOLO v3 greatly improves the accuracy of prediction of small objects.