Today do not know to write, think of the gold 9 silver 10 crawl pull hook to write a software test engineer net we pay ~~
Crawling pull hook Occupational Information Network
Analysis of website information
1. Open the pull hook net, enter the position we want to find

2, the capture tool or developer tools view request data
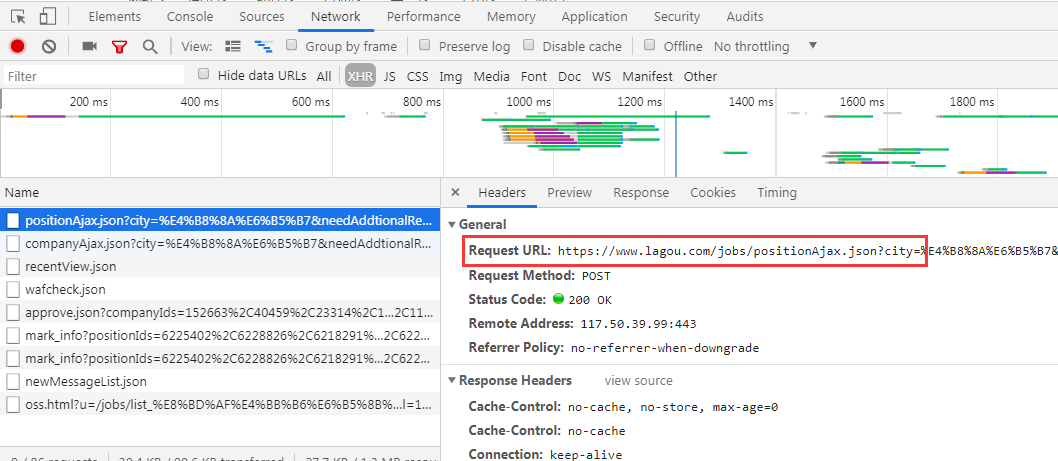
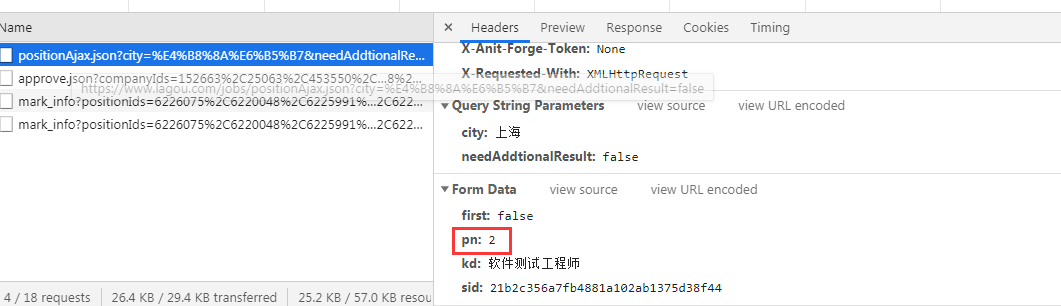
Discovery request address is: https:? //Www.lagou.com/jobs/positionAjax.json city =% E4% B8% 8A% E6% B5% B7 & needAddtionalResult = false
By post in the form of a request, the request parameters may also be seen
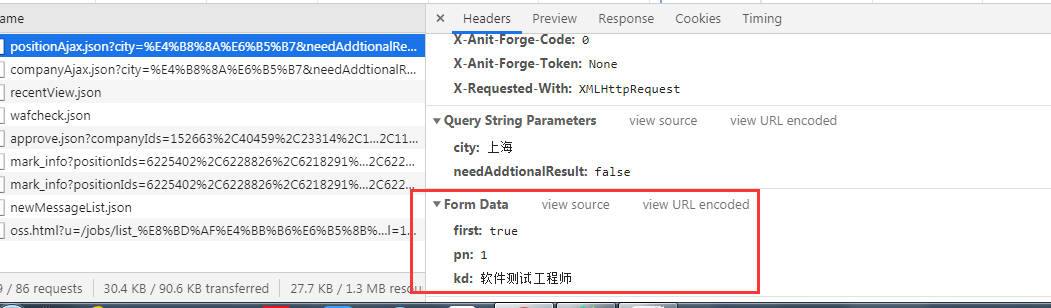
4, data analysis page
By analyzing the presence of preview data format has json
How to get data it? We can, we want to find data by the content of json returned by json content acquisition
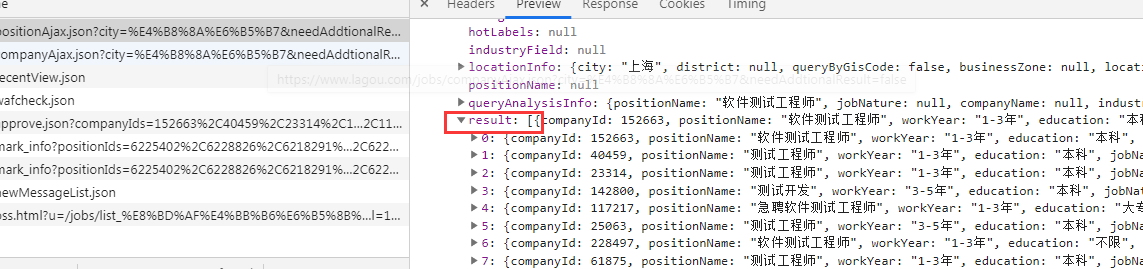
3, post request by sending requests
First of requests directly pull hook network information, addition request header.
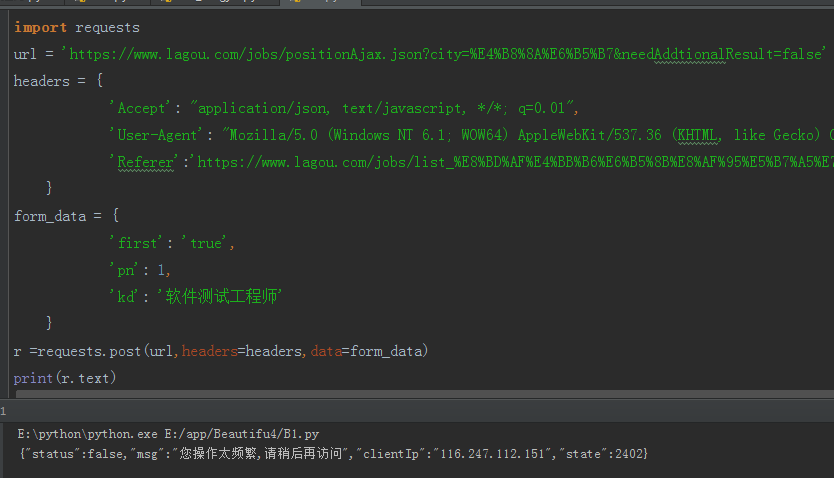
Discovery requests will be prompted frequently can not obtain the site information, so that how to engage?
In front of a small series of written data session by session request, then we try today
First page displaying our request access to information cookies value, carry this web page request url cookies we need to go crawling
import requests # 请求地址 url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E4%B8%8A%E6%B5%B7&needAddtionalResult=false' # 请求头 headers = { 'Accept': "application/json, text/javascript, */*; q=0.01", 'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36", 'Referer':'https://www.lagou.com/jobs/list_%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95%E5%B7%A5%E7%A8%8B% ? E5% B8% 88 City =% E4% B8%. 8A% E6% B5% B7 & Cl = to false & fromSearch = to true & labelWords = & suginput = ' } # request parameter form_data = { ' First ' : ' to true ' , ' PN ' :. 1 , ' KD ' : ' software test engineer ' } # import answer session S = requests.session () # requested page address acquisition Cookies URL_LIST = 'https://www.lagou.com/jobs/list_%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95%E5%B7%A5%E7%A8%8B% E5% B8% 88? City =% E4% B8%. 8A% E6% B5% B7 & Cl = to false & fromSearch = to true & labelWords = & suginput = ' s.get (URL_LIST, headers = headers) Cookie = s.cookies # carrying cookies value continuation request response s.post = (URL, data = form_data, headers = headers, = Cookies Cookie) job_json = response.json () # Get json data Print (job_json)
Json data returned by the observation that we have the data we need in the result data inside, then by json way we can extract out into a list for easy later on we write csv file
csv_data = [] for i in job_list: job_info = [] job_info.append(i['positionName']) # 职位 job_info.append(i['companyShortName']) # 公司 job_info.append(i['salary']) # 薪资 job_info.append(i['education']) # 学历 job_info.append(i['district']) #Position job_info.append (I [ ' workYear ' ]) # EXPERIENCE job_info.append (I [ ' positionAdvantage ' ]) # benefits csv_data.append (job_info)
4, data is written to the csv file
Write csv file written many times, they are basically the same
csvfile = open('软件职业.csv', 'a+',encoding='utf-8-sig',newline='') writer = csv.writer(csvfile) writer.writerows(csv_data) csvfile.close()
5, construct paging list, all data crawling
By observing the control pagination in form_data, we simulate it on page content, crawling all the data
= All [] for The page_num in Range (. 1, 30 ): Result = Data (Page = The page_num) # acquires a total number of data All + = Result Print ( ' crawled pages {}, the total number of jobs: {} ' . format (page_num, len (all) ))
The complete code
import requests # 请求地址 url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E4%B8%8A%E6%B5%B7&needAddtionalResult=false' # 请求头 headers = { 'Accept': "application/json, text/javascript, */*; q=0.01", 'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36", 'Referer':'https://www.lagou.com/jobs/list_%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95%E5%B7%A5%E7%A8%8B% ? E5% B8% 88 City =% E4% B8%. 8A% E6% B5% B7 & Cl = to false & fromSearch = to true & labelWords = & suginput = ' } # request parameter form_data = { ' First ' : ' to true ' , ' PN ' :. 1 , ' KD ' : ' software test engineer ' } # import answer session S = requests.session () # requested page address acquisition Cookies URL_LIST = 'https://www.lagou.com/jobs/list_%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95%E5%B7%A5%E7%A8%8B%E5%B8%88?city=%E4%B8%8A%E6%B5%B7&cl=false&fromSearch=true&labelWords=&suginput=' s.get(url_list, headers=headers) cookie = s.cookies # 携带cookies值继续请求 response = s.post(url, data=form_data, headers=headers,cookies=cookie) job_json = response.json() csv_data = [] for i in job_list: job_info = [] job_info.append(i['positionName']) # 职位 job_info.append (I [ ' companyShortName ' ]) # Company job_info.append (I [ ' the salary ' ]) # pay job_info.append (I [ ' Education ' ]) # degree job_info.append (I [ ' District ' ]) # position job_info.append (I [ ' workYear ' ]) # eXPERIENCE job_info.append (I [ ' positionAdvantage ' ]) # benefits csv_data.append (job_info) # writing list Print (csv_data) csvFile = Open ( ' SOFTWARE .csv ' , ' A + ' , encoding = ' UTF--SIG. 8 ' , NEWLINE = '' ) Writer = csv.writer (csvFile) writer.writerows (csv_data) csvfile.close () return csv_data IF the __name__ == ' __main__ ' : A = [( ' post ' , ' company ' , ' salary' , ' Degree ' , ' location ' , ' EXPERIENCE ' , ' welfare ' )] csvFile = Open ( ' SOFTWARE .csv ' , ' A + ' , encoding = ' UTF--SIG. 8 ' , = NEWLINE ' ' ) Writer = csv.writer (csvFile) writer.writerows (A) csvfile.close () All = [] for The page_num in Range (. 1, 30 ): ResultData = (Page = The page_num) All + = Result Print ( ' crawled pages {}, the total number of jobs: {} ' .format (The page_num, len (All))) # control time, to prevent that site crawler time.sleep (15)
Crawl results:
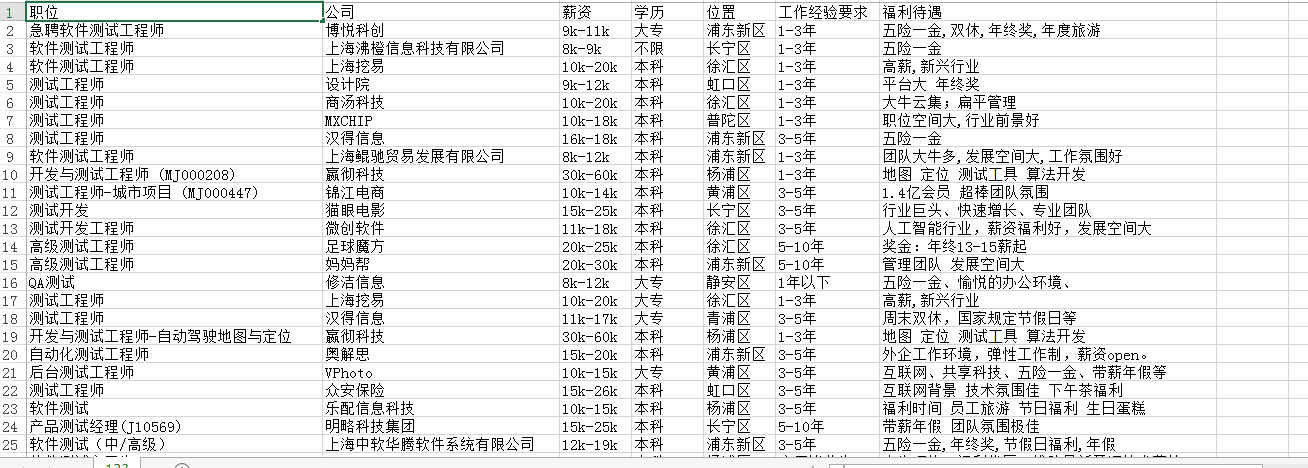
We tested to see such a high salary, good heart, ~~~~~
Note, do not ask too often, think of reptiles IP closure.
If you feel like it, the lower right corner followers ~~~