1.1.1core-site.xml (tool module)
Including Hadoop commonly used tools, it changed its name from the original Hadoopcore part. Including system configuration tool Configuration, remote procedure call RPC, serialization mechanism and Hadoop file system FileSystem abstract and so on. They provide basic services to build a cloud computing environment on commodity hardware, and provides the necessary API to develop software to run on the platform.
1.1.2hdfs-site.xml (data storage means)
Distributed file system, application data providing high throughput , high stretchability , high fault tolerance access. It is the basis for Hadoop system data storage management. It is a highly fault-tolerant system that can detect and respond to hardware failure, to run on low-cost commodity hardware. HDFS consistency simplifies the model file, by accessing streaming data , provides high-throughput access application data for applications with large data sets.
namenode + datanode + secondarynode
1.1.3mapred-site.xml (data processing module)
Based on parallel processing systems YARN large datasets. Is a calculation model for calculating large amount of data. Hadoop MapReduce implementations of, and Common, HDFS together, constitute the early development of three components Hadoop. The MapReduce Map and Reduce the application is divided into two steps, wherein individual elements of the Map data sets specified operation, generating key - value pairs of intermediate results. Reduce the same intermediate result "key" all "values" in the statute, to obtain the final result. MapReduce functions of this division, is ideal for distributed parallel environment consisting of a large number of computers in data processing.
1.1.4yarn-site.xml (+ job scheduling resource management platform)
Task scheduling and cluster resource management
resourcemanager + nodemanager
1.2hadoop five nodes:
1.2.1NameNode (management node)
Namenode space command manages the file system (Namespace). It maintains the file system tree (FileSystemTree) and metadata file tree of all files and folders (metadata), including editing metadata log (edits) and image files (fsimage). The management information file has two, namely Namespace image file (FsImage) and editing the log file (edits) , mainly edit log is a record of modifications made hdfs. The main image file is a file tree structure of the recording hdfs Such information Cache in RAM is, of course, these two documents will be stored in a persistent local hard disk . Namenode record the location information for each file in the data nodes where each block, but he is not persistent store this information , because this information will be reconstructed from the data node at system startup.
1.2.2DataNode (work nodes)
Datanode node file system is working , they are based on the client or namenode the schedule storing and retrieving data , and to periodically namenode transmission block their stored list (block) a.
No namenode, the file system can not be used. In fact, if the server is running namenode services broken, all the files on the file system will be lost because we do not know how to rebuild the file according to DataNode blocks. All of conduct NameNode Fault-tolerant redundancy mechanism is very important .
Cluster run from a server node DataNode daemon , this daemon is responsible for reading and writing HDFS data blocks to the local file system . When required by a client to read / write a data, first NameNode tell the client to which DataNode specific read / write operations, and then the client communicates directly with DataNode daemon on this server, and the relevant data block read / write operation.
1.2.3secondary NameNode (corresponding to a MySQL database from the master copy from node)
Secondary NameNode是一个用来监控HDFS状态的辅助后台程序。和NameNode一样,每个集群都有一个Secondary NameNode,并且部署在一个单独的服务器上。Secondary NameNode不同于NameNode,它不接受或者记录任何实时的数据变化,但是,它会与NameNode进行通信,以便定期地保存HDFS元数据的快照。由于NameNode是单点的,通过Secondary NameNode的快照功能,可以将NameNode的宕机时间和数据损失降低到最小。同时,如果NameNode发生问题,Secondary NameNode可以及时地作为备用NameNode使用。
1.2.4ResourceManager
ResourceManage 即资源管理,在YARN中,ResourceManager负责集群中所有资源的统一管理和分配,它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上是ApplicationManager)。
RM包括Scheduler(定时调度器)和ApplicationManager(应用管理器)。Schedular负责向应用程序分配资源,它不做监控以及应用程序的状态跟踪,并且不保证会重启应用程序本身或者硬件出错而执行失败的应用程序。ApplicationManager负责接受新的任务,协调并提供在ApplicationMaster容器失败时的重启功能.每个应用程序的AM负责项Scheduler申请资源,以及跟踪这些资源的使用情况和资源调度的监控
1.2.5Nodemanager
NM是ResourceManager在slave机器上的代理,负责容器管理,并监控它们的资源使用情况,以及向ResourceManager/Scheduler提供资源使用报告
HDFS文件存储机制:
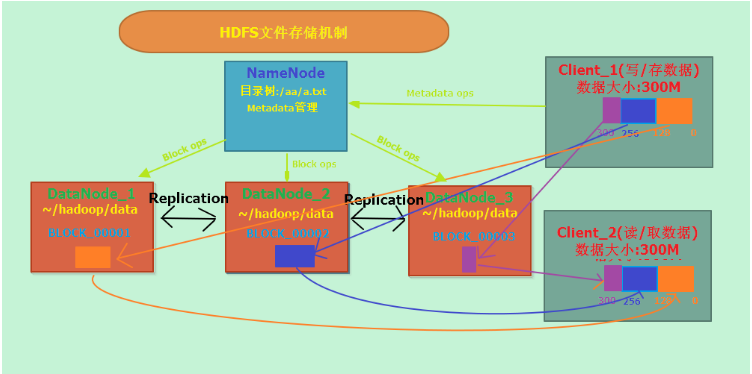
HDFS集群分为两大角色:NameNode、DataNode、(secondary NameNode)
NameNode负责管理整个文件系统的元数据
DataNode负责管理用户的文件数据块
文件会按照固定的大小切成若干块后分布式存储在若干台DataNode上
每一个文件块可以有多个副本,并存放在不同的DataNode上
DataNode会定期向NameNode汇报自身所保存的文件block信息,而NameNode则会负责保持文件的副本数量
HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向NameNode申请来进行