- Download hadoop archive, here is the download version 5.14.2 (address: http://archive.cloudera.com/cdh5/cdh/5/ )

2. Xftp tool bag onto the compressed virtual machine / opt directory (Personal optional) 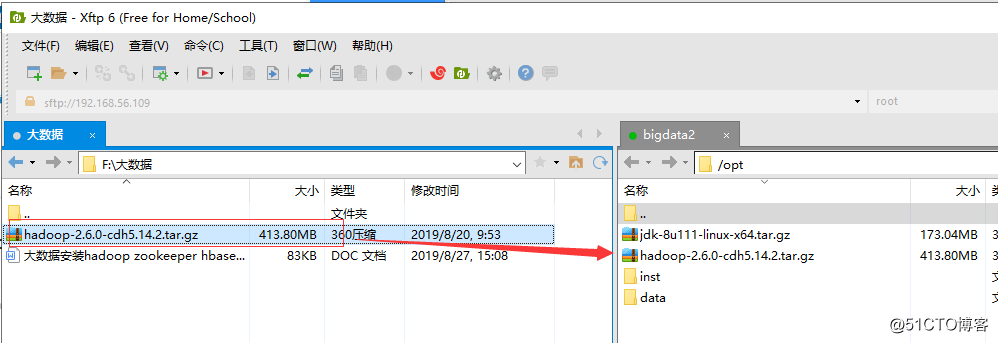
3. Extract hadoop archive (command: the tar-2.6.0-cdh5.14.2.tar.gz -zxvf hadoop) 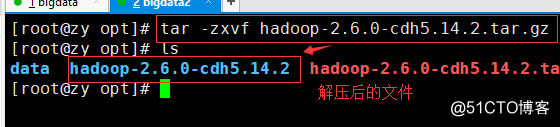
4. where for clarity, a new file folder with bigData stored separately after decompression, and rename
the new: mkdir bigdata
mobile: Music Videos Hadoop-2.6.0-cdh5.14.2 ./bigdata/hadoop260 
5. the head weight: modify the configuration file, move to / etc Up / down hadoop directory, ls command, circled in the figure below in this document is that we need to configure 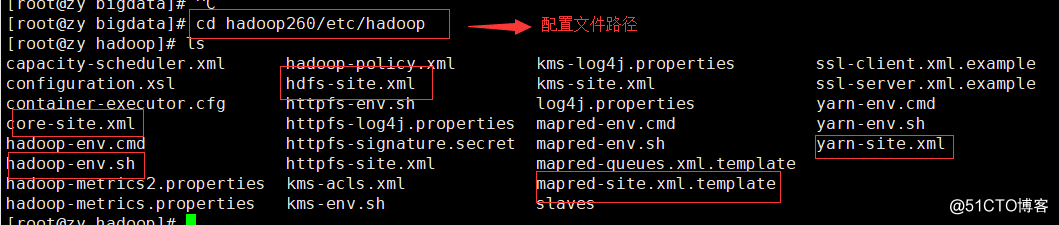
6. configuration 1: vi hadoop-env.sh amended as follows position, to modify JAVA_HOME own path, you can echo $ JAVA_HOME View , revised and stored exit 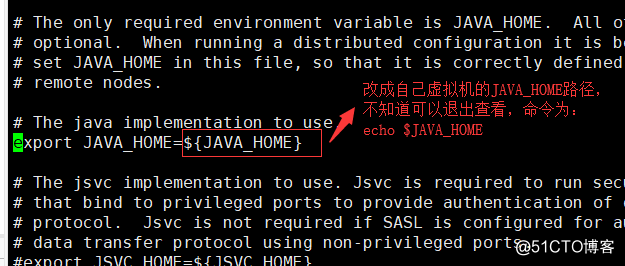
7. configuration 2: vi core-site.xml modify a position
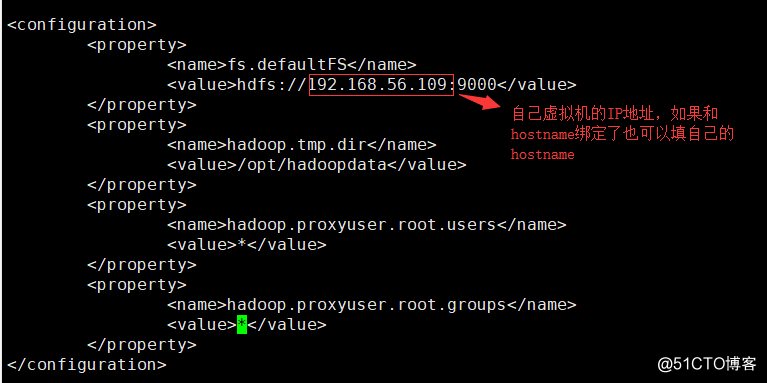
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.56.109:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoopdata</value>
</property>
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>8. Configuration 3: vi hdfs-site.xml, as in the previous step and adding the following code Tags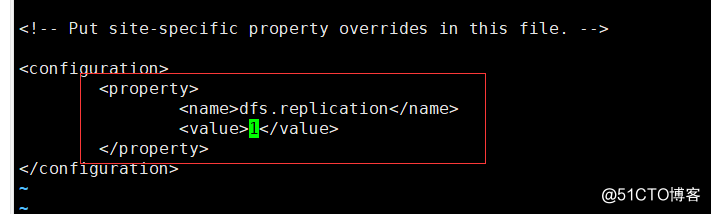
<property>
<name>dfs.replication</name>
<value>1</value>
</property>9. Configuration 4, needs its own Copy the file, and the previous step was added as the following code Tags
command: cp mapred-site.xml.template mapred-site.xml
configuration: vi mapred-site.xml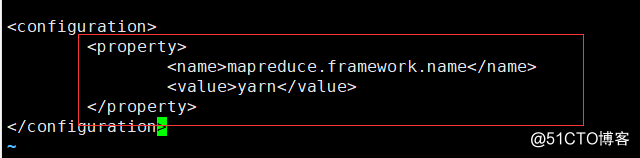
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>10. Configuration 5: vi yarn-site.xml, middle-line comments can be removed directly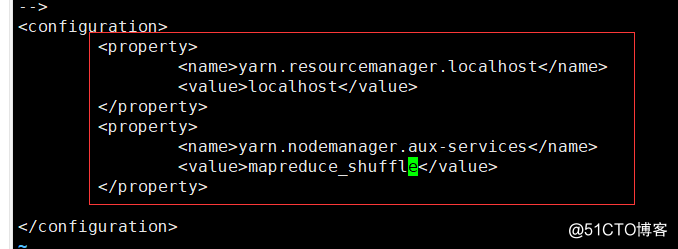
<property>
<name>yarn.resourcemanager.localhost</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
11. Six-: vi / etc / profile, moved to the last, the following code is added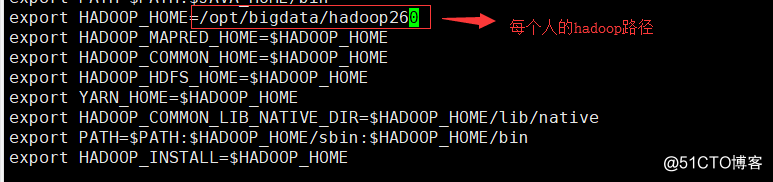
export HADOOP_HOME=/opt/bigdata/hadoop260
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME12. The activation profile: Source / etc / Profile
13. Format NameNode: HDFS NameNode -format
14. A run: start-all.sh, then each step input Yes
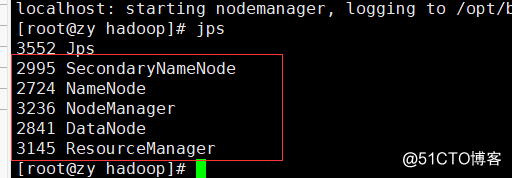
15. A check on the operation: jps, to see if the following 5 process, represents configured to run a successful, if less which one went to check the corresponding configuration file