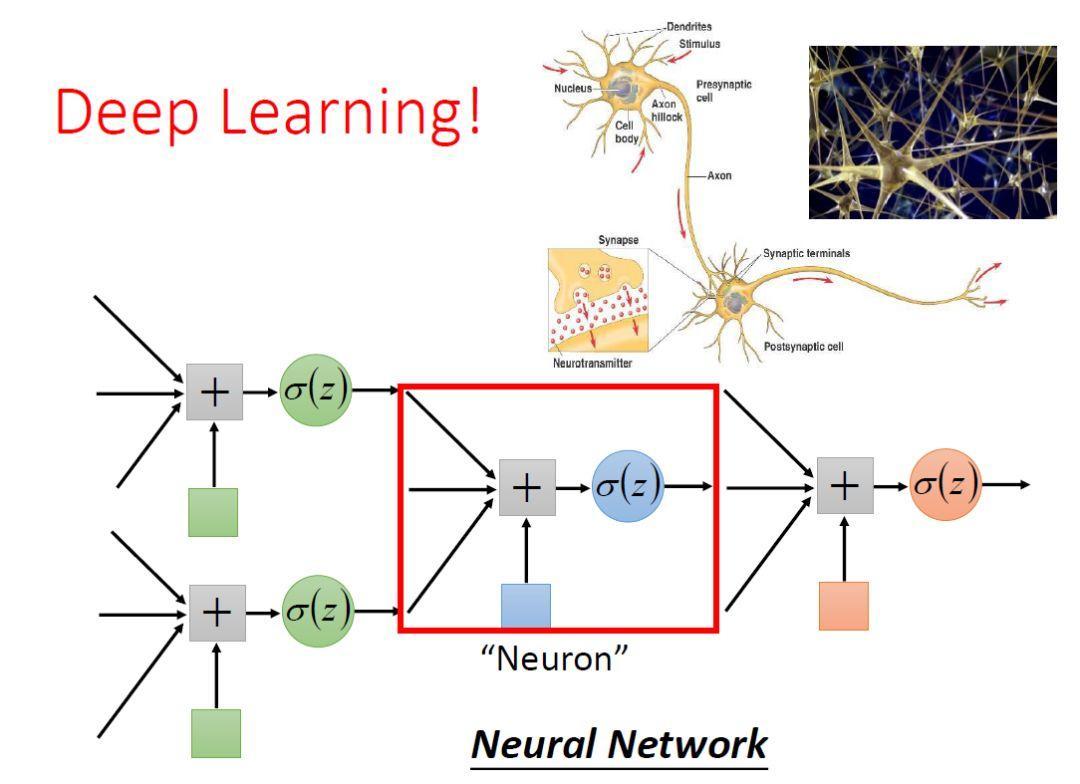
Antecedent Review
Machine learning 100 days | Day1 data preprocessing
for 100 days machine learning | Day2 simple linear regression analysis
for 100 days machine learning | Day3 multiple linear regression
for 100 days machine learning | Day4-6 logistic regression
for 100 days machine learning | Day7 K- NN
100 days to get the machine learning | Principia Mathematica Day8 logistic regression
for 100 days machine learning | Day9-12 support vector machine
for 100 days of machine learning | Day11 achieve KNN
100 days to get the machine learning | achieve Day13-14 SVM of
100 days to get the machine learning | Day15 naive Bayes
Day17, Avik-Jain start at Coursera depth study of professional courses, complete logistic regression Week 1 and Week 2 of the course content and learning, neural networks, and implement a neural network with Python.
Day4-6 We have learned a logistic regression model.
100 days to get the machine learning | Day4-6 logistic regression
But we did not discuss in depth scalability, after all, this model is very straightforward. In fact, there is a link between the model, such as Logistic Regression leads SVM regression model.
First, we'll look back Logistic Regression
The main idea is to classify logistic regression: a regression equation to classify borderline According to available data, in order to be classified. We want the function should be, can accept all inputs and predicted category. For example, for the classification, the function should return 0 or 1.
Logistic regression function is assumed as follows
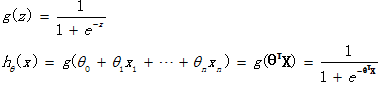
It [theta] T X- made a conversion function g, mapped to the range of 0 to 1, and the function g is called sigmoid function or logistic function, a function of the image as shown below.
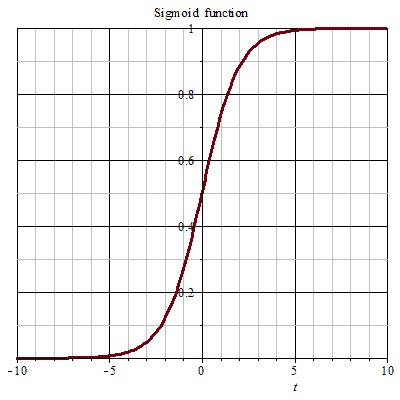
Logistic regression is used to obtain the probability of the sample belonging to a category when the input is equal to z 0, Sigmoid function value 0.5. With increasing z, the function corresponding to a value close to 1; z decreases, the function corresponding to the value close to zero.
We then drawn through logistic regression SVM
We found H θ (the X-) and θ only T the X-related, θ T the X-> 0, then H θ (the X-)> 0.5.g (z) is only used to map, the decision is still true category θ T the X- . Model to achieve the goal nothing more than to make the training data characteristics y = 1 [theta] T the X->> 0, but y = 0 characteristic of [theta] T the X-<< 0. Logistic regression study is to obtain [theta], characterized in that the positive examples is much larger than 0, a negative feature of the embodiment is much smaller than 0, to achieve this goal emphasis on all the training examples.
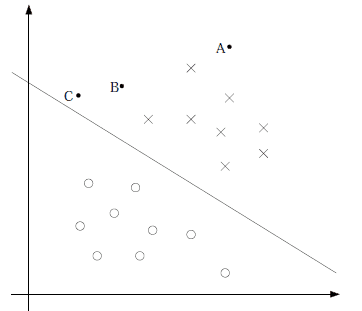
Figure above that line is [theta] T X-= 0, all emphasis Logistic Recalling that line away from the intermediate points as possible, also the intermediate results of the study that line. So we can conclude that we should be concerned about a point near the middle of the dividing line, keep them away from the middle line as much as possible, rather than optimal in all points.
Then, look at the cost of logistic regression function
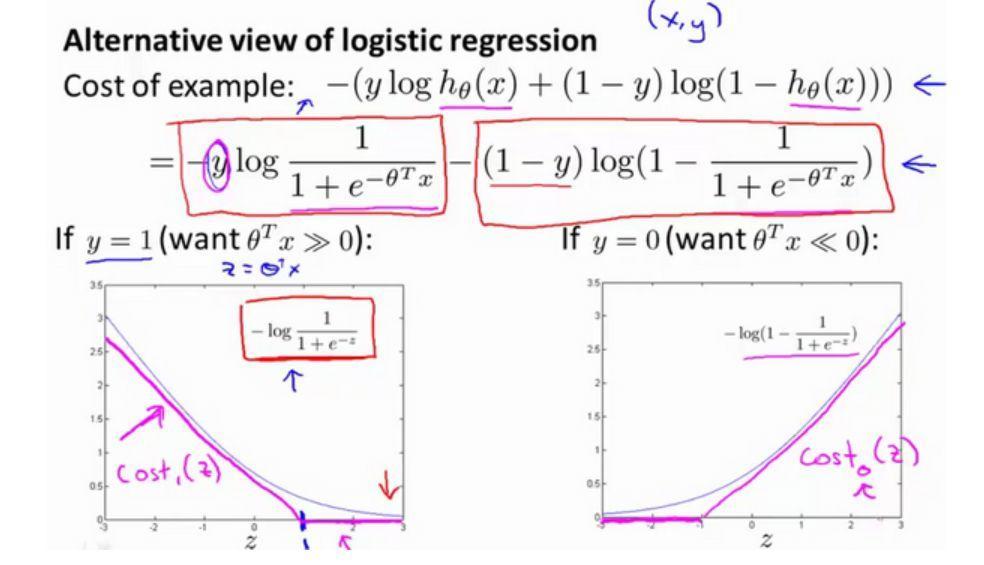
When y = 1, and [theta] z = T X into which minor modifications loss function image can be obtained image SVM loss function, taking as a point of z = Draw a boundary very close to the logistic regression and the linear image obtained rose red image above a straight line, called Cost1 (z). y = 0, obtained similarly Cost0 (z).
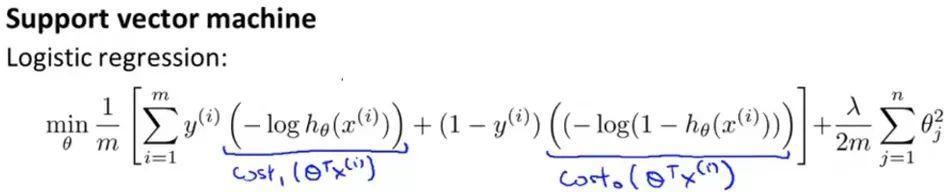
Modified basic logistic regression equation was obtained at: 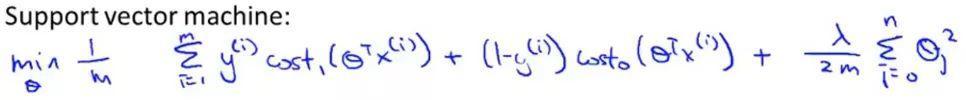
Because people in different rules when using logistic regression and SVM follow, some places still need to be modified, in the above formulas and part of the loss parts are removed regularization 1 / m items
Λ used in the logistic regression function to balance the loss of the sample entry and regularization terms, in the SVM, to balance the use of C.
The final SVM expression :
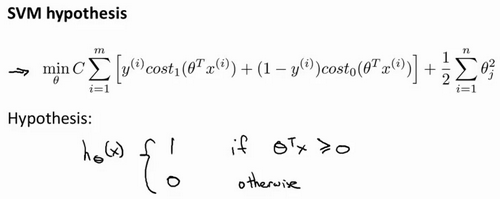
Here, while minimizing the cost function, to obtain the parameter [theta], SVM is that it does directly prediction value y equal to 1 or equal to 0. So learning parameter θ is assumed that the form of support vector machines function.
Another: the detailed process suggest that you watch Andrew Ng original machine learning courses open class
https://www.coursera.org/course/ml
Return to the topic -------------- -------------- dividing line
Neural network and logistic regression to do with it? Let me talk about the conclusion:
Logistic regression is not hidden layer of the neural network
Logistic regression process leads to neural networks, I think CHANG most ingenious machine-learning courses.
First Logistic regression has limitations, there is no way to classify linearly inseparable data.
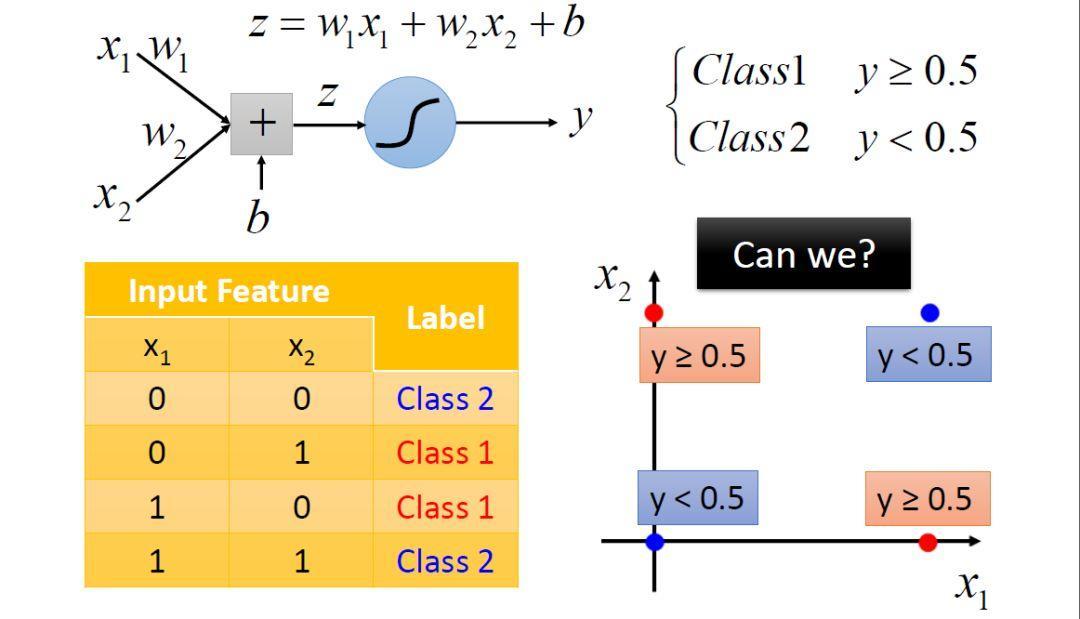
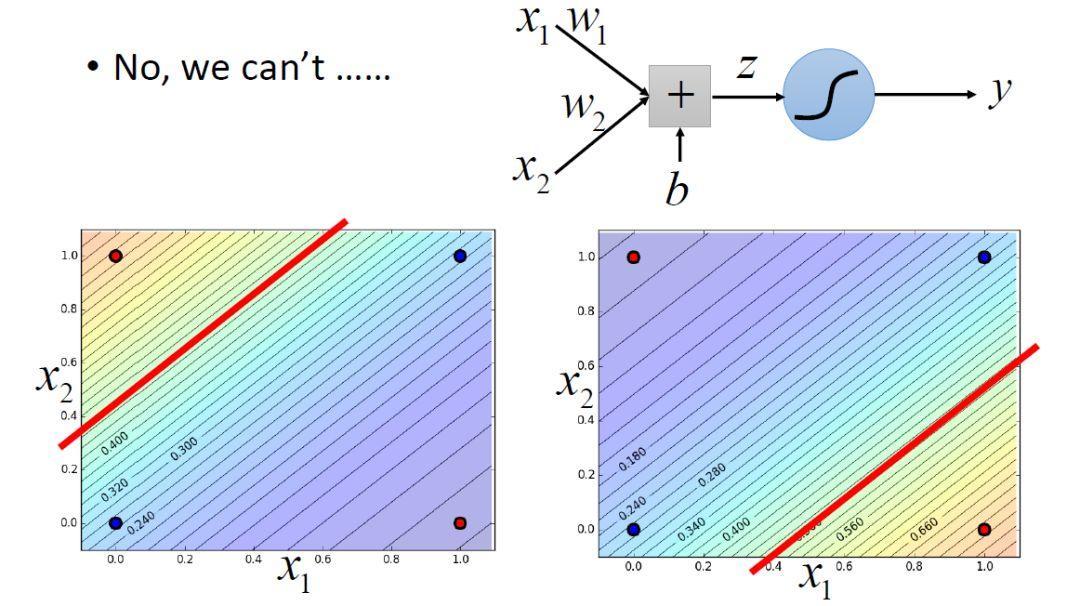
For example, the above case, there is no way to classify the use of a straight line.
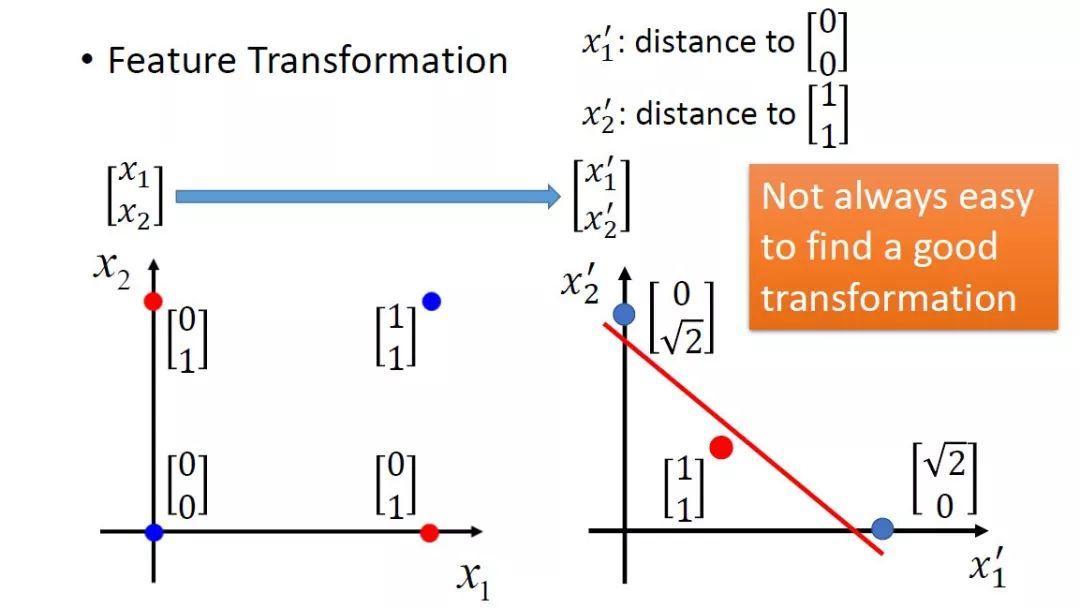
One solution is to solve the XOR problem by converting the feature space method, linearly inseparable data may be separated after conversion characteristic good red line area. But can not always be found by manual methods rely on a good conversion, which is contrary to the nature of machine learning.
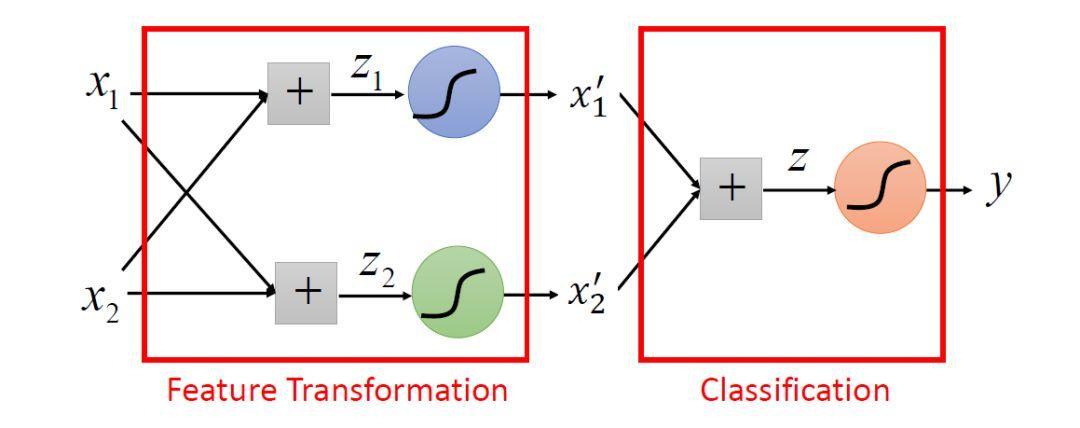
so, Logistic Regression can be seen as two-layer neuron activation function is the Sigmoid function of the neural network. Sigmoid function is the role of the left two aspects of the conversion, the role of the right classification.
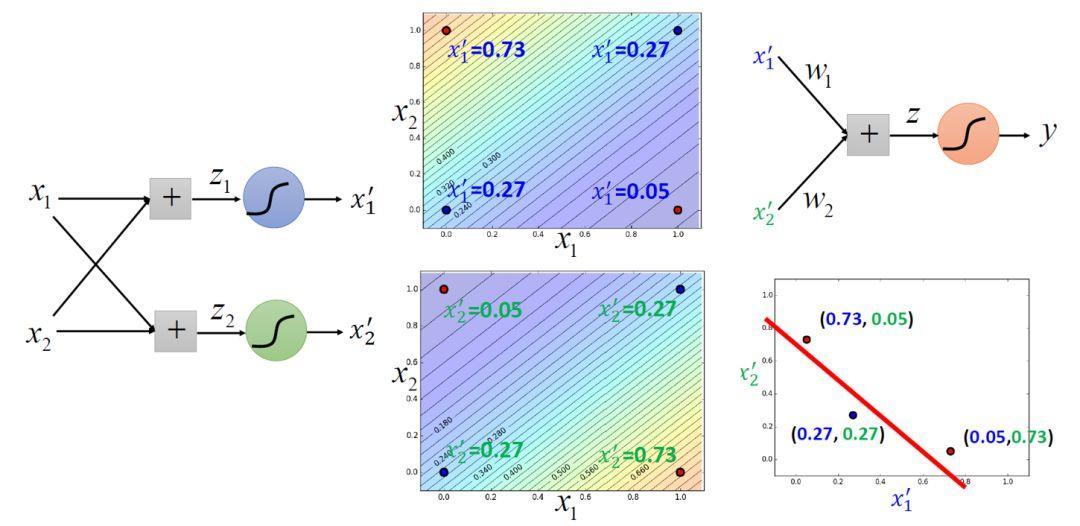
Logistic regression together is the basic structure of the depth of learning.