I. Introduction
More than 1.1 data source support
Spark supports the following six core data source, while Spark community also offers up hundreds of ways to read the data source to meet the vast majority of usage scenarios.
- CSV
- JSON
- Parquet
- ORC
- JDBC/ODBC connections
- Plain-text files
Note: All of the following test files available from this warehouse resources download directory
1.2 Read Data Format
API calls to read all the following formats:
// 格式
DataFrameReader.format(...).option("key", "value").schema(...).load()
// 示例
spark.read.format("csv")
.option("mode", "FAILFAST") // 读取模式
.option("inferSchema", "true") // 是否自动推断 schema
.option("path", "path/to/file(s)") // 文件路径
.schema(someSchema) // 使用预定义的 schema
.load()Read Mode There are three options:
| Read Mode | description |
|---|---|
permissive |
Encountered when the recording is damaged, all of its fields set to null, and all the records in the damaged column named string of _corruption t_record |
dropMalformed |
Delete malformed line |
failFast |
Failure immediately encountered a malformed data |
1.3 Write Data Format
// 格式
DataFrameWriter.format(...).option(...).partitionBy(...).bucketBy(...).sortBy(...).save()
//示例
dataframe.write.format("csv")
.option("mode", "OVERWRITE") //写模式
.option("dateFormat", "yyyy-MM-dd") //日期格式
.option("path", "path/to/file(s)")
.save()Write data model has the following four options:
| Scala / Java | description |
|---|---|
SaveMode.ErrorIfExists |
If the given path to the file already exists, an exception is thrown, which is the default mode to write data |
SaveMode.Append |
Writing additional data in a manner |
SaveMode.Overwrite |
To cover the write data |
SaveMode.Ignore |
If the given path to the file already exists, no operation |
Two, CSV
CSV is a common text file format, where each row represents a record, record each field separated by a comma.
2.1 reading CSV file
Example infer the type automatically reading reads:
spark.read.format("csv")
.option("header", "false") // 文件中的第一行是否为列的名称
.option("mode", "FAILFAST") // 是否快速失败
.option("inferSchema", "true") // 是否自动推断 schema
.load("/usr/file/csv/dept.csv")
.show()Use predefined types:
import org.apache.spark.sql.types.{StructField, StructType, StringType,LongType}
//预定义数据格式
val myManualSchema = new StructType(Array(
StructField("deptno", LongType, nullable = false),
StructField("dname", StringType,nullable = true),
StructField("loc", StringType,nullable = true)
))
spark.read.format("csv")
.option("mode", "FAILFAST")
.schema(myManualSchema)
.load("/usr/file/csv/dept.csv")
.show()2.2 write CSV file
df.write.format("csv").mode("overwrite").save("/tmp/csv/dept2")You may specify a specific separator:
df.write.format("csv").mode("overwrite").option("sep", "\t").save("/tmp/csv/dept2")2.3 Optional
To save space the main text, read all configuration items, see end of text section 9.1.
Three, JSON
3.1 JSON file to read
spark.read.format("json").option("mode", "FAILFAST").load("/usr/file/json/dept.json").show(5)Note that: a default data record is not supported across multiple lines (see below), you can be configured multiLineto truechange to its default value false.
// 默认支持单行
{"DEPTNO": 10,"DNAME": "ACCOUNTING","LOC": "NEW YORK"}
//默认不支持多行
{
"DEPTNO": 10,
"DNAME": "ACCOUNTING",
"LOC": "NEW YORK"
}3.2 write JSON file
df.write.format("json").mode("overwrite").save("/tmp/spark/json/dept")3.3 Optional
To save space the main text, read all configuration items, see end of article 9.2 section.
Four, Parquet
Parquet is an open source data store for a column, it provides a variety of storage optimized for the individual columns to read the entire non-file, which not only saves storage space and enhance the efficiency of reading, it is the default file format Spark .
Parquet read 4.1 files
spark.read.format("parquet").load("/usr/file/parquet/dept.parquet").show(5)2.2 write file Parquet
df.write.format("parquet").mode("overwrite").save("/tmp/spark/parquet/dept")2.3 Optional
Parquet storage file has its own rules, so the optional configuration items is relatively small, two commonly used are as follows:
| Read and write operations | Configuration Item | Optional value | Defaults | description |
|---|---|---|---|---|
| Write | compression or codec | None, uncompressed, bzip2, deflate, gzip, lz4, or snappy |
None | Compressed file format |
| Read | mergeSchema | true, false | Depending on the configuration items spark.sql.parquet.mergeSchema |
When true, Parquet data source to all data files collected Schema merge together, or choose from the summary file Schema, if none is available the summary file, select the file from random data Schema. |
More optional configuration can be found in the official documentation: https://spark.apache.org/docs/latest/sql-data-sources-parquet.html
Five, ORC
ORC is a self-describing type of column sensing file format that is optimized for large data reading and writing, and it is commonly used in large data file formats.
5.1 ORC to read the file
spark.read.format("orc").load("/usr/file/orc/dept.orc").show(5)4.2 ORC write file
csvFile.write.format("orc").mode("overwrite").save("/tmp/spark/orc/dept")六、SQL Databases
Spark also supports reading and writing data from traditional relational databases. But there is no default Spark program provides database-driven, so before you need to use the corresponding database-driven uploaded to the installation directory jarsdirectory. The following example uses Mysql database, before use the corresponding mysql-connector-java-x.x.x.jarupload jarsdirectory.
6.1 to read data
To read all the data table the following example, here help_keywordis the built-in dictionary mysql table only help_keyword_id, and nametwo fields.
spark.read
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver") //驱动
.option("url", "jdbc:mysql://127.0.0.1:3306/mysql") //数据库地址
.option("dbtable", "help_keyword") //表名
.option("user", "root").option("password","root").load().show(10)Read data from query results:
val pushDownQuery = """(SELECT * FROM help_keyword WHERE help_keyword_id <20) AS help_keywords"""
spark.read.format("jdbc")
.option("url", "jdbc:mysql://127.0.0.1:3306/mysql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root").option("password", "root")
.option("dbtable", pushDownQuery)
.load().show()
//输出
+---------------+-----------+
|help_keyword_id| name|
+---------------+-----------+
| 0| <>|
| 1| ACTION|
| 2| ADD|
| 3|AES_DECRYPT|
| 4|AES_ENCRYPT|
| 5| AFTER|
| 6| AGAINST|
| 7| AGGREGATE|
| 8| ALGORITHM|
| 9| ALL|
| 10| ALTER|
| 11| ANALYSE|
| 12| ANALYZE|
| 13| AND|
| 14| ARCHIVE|
| 15| AREA|
| 16| AS|
| 17| ASBINARY|
| 18| ASC|
| 19| ASTEXT|
+---------------+-----------+The following may also be used to filter the data writing:
val props = new java.util.Properties
props.setProperty("driver", "com.mysql.jdbc.Driver")
props.setProperty("user", "root")
props.setProperty("password", "root")
val predicates = Array("help_keyword_id < 10 OR name = 'WHEN'") //指定数据过滤条件
spark.read.jdbc("jdbc:mysql://127.0.0.1:3306/mysql", "help_keyword", predicates, props).show()
//输出:
+---------------+-----------+
|help_keyword_id| name|
+---------------+-----------+
| 0| <>|
| 1| ACTION|
| 2| ADD|
| 3|AES_DECRYPT|
| 4|AES_ENCRYPT|
| 5| AFTER|
| 6| AGAINST|
| 7| AGGREGATE|
| 8| ALGORITHM|
| 9| ALL|
| 604| WHEN|
+---------------+-----------+You may be used numPartitionsto specify data read parallelism:
option("numPartitions", 10)Here, instead of specifying a partition, but also may be provided upper and lower bounds, no less than the lower bound value is assigned a first partition, any value greater than the upper bound is assigned in the last partition.
val colName = "help_keyword_id" //用于判断上下界的列
val lowerBound = 300L //下界
val upperBound = 500L //上界
val numPartitions = 10 //分区综述
val jdbcDf = spark.read.jdbc("jdbc:mysql://127.0.0.1:3306/mysql","help_keyword",
colName,lowerBound,upperBound,numPartitions,props)Want to verify the contents of the partition, you can use mapPartitionsWithIndexthis operator, as follows:
jdbcDf.rdd.mapPartitionsWithIndex((index, iterator) => {
val buffer = new ListBuffer[String]
while (iterator.hasNext) {
buffer.append(index + "分区:" + iterator.next())
}
buffer.toIterator
}).foreach(println)Execution results are as follows: help_keywordThis table is only about 600 data, the data should have been uniformly distributed in the partition 10, but which there are partitions 0 319 data, which is set as a lower limit, all data will be less than 300 limited The first partition, partition 0. Similarly all the data are assigned is greater than 500 in the partition 9, i.e., the last partition.
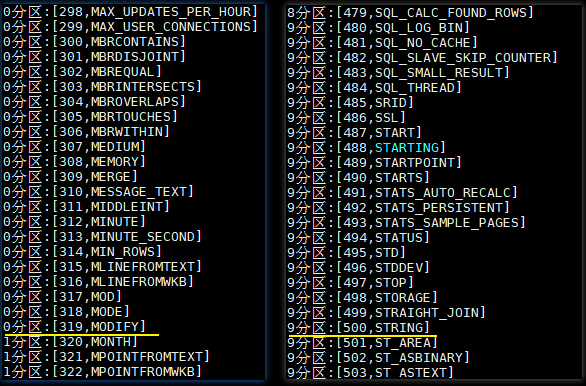
6.2 write data
val df = spark.read.format("json").load("/usr/file/json/emp.json")
df.write
.format("jdbc")
.option("url", "jdbc:mysql://127.0.0.1:3306/mysql")
.option("user", "root").option("password", "root")
.option("dbtable", "emp")
.save()Seven, Text
Text file read and write performance, and there is no advantage, and can not express a clear data structure, so its use is relatively small, read and write operations as follows:
7.1 Text data read
spark.read.textFile("/usr/file/txt/dept.txt").show()7.2 Text written data
df.write.text("/tmp/spark/txt/dept")Eight, advanced features to read and write data
8.1 concurrent read
More Executors can not read the same file at the same time, but they can read different files at the same time. This means that when your file contains multiple files from a folder to read data, each of these files will be a partition of DataFrame by available Executors read in parallel.
8.2 concurrent write
The number of write files or data depends on the number of partitions has DataFrame when writing data. By default, each data partition to write a file.
8.3 Partition write
Partition and sub-barrel these two concepts and sub-Hive in the partition table and the table is the same barrel. The data are split according to certain rules stored. Note that the partitionByspecified partitions and the partition is not a concept RDD: Here partitioning performance subdirectory output directory , the data are stored in the corresponding subdirectory.
val df = spark.read.format("json").load("/usr/file/json/emp.json")
df.write.mode("overwrite").partitionBy("deptno").save("/tmp/spark/partitions")The output is as follows: You can see the output is divided into three sub-directory, subdirectory is the corresponding output files according to department number.

8.3 barrels written
分桶写入就是将数据按照指定的列和桶数进行散列,目前分桶写入只支持保存为表,实际上这就是 Hive 的分桶表。
val numberBuckets = 10
val columnToBucketBy = "empno"
df.write.format("parquet").mode("overwrite")
.bucketBy(numberBuckets, columnToBucketBy).saveAsTable("bucketedFiles")8.5 文件大小管理
如果写入产生小文件数量过多,这时会产生大量的元数据开销。Spark 和 HDFS 一样,都不能很好的处理这个问题,这被称为“small file problem”。同时数据文件也不能过大,否则在查询时会有不必要的性能开销,因此要把文件大小控制在一个合理的范围内。
在上文我们已经介绍过可以通过分区数量来控制生成文件的数量,从而间接控制文件大小。Spark 2.2 引入了一种新的方法,以更自动化的方式控制文件大小,这就是 maxRecordsPerFile 参数,它允许你通过控制写入文件的记录数来控制文件大小。
// Spark 将确保文件最多包含 5000 条记录
df.write.option(“maxRecordsPerFile”, 5000)九、可选配置附录
9.1 CSV读写可选配置
| 读\写操作 | 配置项 | 可选值 | 默认值 | 描述 |
|---|---|---|---|---|
| Both | seq | 任意字符 | ,(逗号) |
分隔符 |
| Both | header | true, false | false | 文件中的第一行是否为列的名称。 |
| Read | escape | 任意字符 | \ | 转义字符 |
| Read | inferSchema | true, false | false | 是否自动推断列类型 |
| Read | ignoreLeadingWhiteSpace | true, false | false | 是否跳过值前面的空格 |
| Both | ignoreTrailingWhiteSpace | true, false | false | 是否跳过值后面的空格 |
| Both | nullValue | 任意字符 | “” | 声明文件中哪个字符表示空值 |
| Both | nanValue | 任意字符 | NaN | 声明哪个值表示 NaN 或者缺省值 |
| Both | positiveInf | 任意字符 | Inf | 正无穷 |
| Both | negativeInf | 任意字符 | -Inf | 负无穷 |
| Both | compression or codec | None, uncompressed, bzip2, deflate, gzip, lz4, or snappy |
none | 文件压缩格式 |
| Both | dateFormat | 任何能转换为 Java 的 SimpleDataFormat 的字符串 |
yyyy-MM-dd | 日期格式 |
| Both | timestampFormat | 任何能转换为 Java 的 SimpleDataFormat 的字符串 |
yyyy-MMdd’T’HH:mm:ss.SSSZZ | 时间戳格式 |
| Read | maxColumns | 任意整数 | 20480 | 声明文件中的最大列数 |
| Read | maxCharsPerColumn | 任意整数 | 1000000 | 声明一个列中的最大字符数。 |
| Read | escapeQuotes | true, false | true | 是否应该转义行中的引号。 |
| Read | maxMalformedLogPerPartition | 任意整数 | 10 | 声明每个分区中最多允许多少条格式错误的数据,超过这个值后格式错误的数据将不会被读取 |
| Write | quoteAll | true, false | false | 指定是否应该将所有值都括在引号中,而不只是转义具有引号字符的值。 |
| Read | multiLine | true, false | false | 是否允许每条完整记录跨域多行 |
9.2 JSON读写可选配置
| 读\写操作 | 配置项 | 可选值 | 默认值 |
|---|---|---|---|
| Both | compression or codec | None, uncompressed, bzip2, deflate, gzip, lz4, or snappy |
none |
| Both | dateFormat | 任何能转换为 Java 的 SimpleDataFormat 的字符串 | yyyy-MM-dd |
| Both | timestampFormat | 任何能转换为 Java 的 SimpleDataFormat 的字符串 | yyyy-MMdd’T’HH:mm:ss.SSSZZ |
| Read | primitiveAsString | true, false | false |
| Read | allowComments | true, false | false |
| Read | allowUnquotedFieldNames | true, false | false |
| Read | allowSingleQuotes | true, false | true |
| Read | allowNumericLeadingZeros | true, false | false |
| Read | allowBackslashEscapingAnyCharacter | true, false | false |
| Read | columnNameOfCorruptRecord | true, false | Value of spark.sql.column&NameOf |
| Read | multiLine | true, false | false |
9.3 数据库读写可选配置
| 属性名称 | 含义 |
|---|---|
| url | 数据库地址 |
| dbtable | 表名称 |
| driver | 数据库驱动 |
| partitionColumn, lowerBound, upperBoun |
分区总数,上界,下界 |
| numPartitions | 可用于表读写并行性的最大分区数。如果要写的分区数量超过这个限制,那么可以调用 coalesce(numpartition) 重置分区数。 |
| fetchsize | 每次往返要获取多少行数据。此选项仅适用于读取数据。 |
| batchsize | 每次往返插入多少行数据,这个选项只适用于写入数据。默认值是 1000。 |
| isolationLevel | 事务隔离级别:可以是 NONE,READ_COMMITTED, READ_UNCOMMITTED,REPEATABLE_READ 或 SERIALIZABLE,即标准事务隔离级别。 默认值是 READ_UNCOMMITTED。这个选项只适用于数据读取。 |
| createTableOptions | 写入数据时自定义创建表的相关配置 |
| createTableColumnTypes | 写入数据时自定义创建列的列类型 |
数据库读写更多配置可以参阅官方文档:https://spark.apache.org/docs/latest/sql-data-sources-jdbc.html
参考资料
- Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02
- https://spark.apache.org/docs/latest/sql-data-sources.html
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南