introduction:
Data manipulation language (Data Manipulation Language, DML) is the SQL language, is responsible for operating data access instruction set to work on database objects to INSERT, UPDATE, DELETE three kinds of instruction as the core, representing the insert, update and delete, are developed to data-centric applications will certainly use the command
Hands-on
This is a continuation on an update written an article on: MYSQL Learning Series --DML statement (a)
The last time we were to say to insert, update, delete records, we have to introduce different play this query (related to some common functions)
4) query logselect 字段 from 表名
1> query does not duplicate records
here we use the mysql database that comes to demonstrate (information_schema) 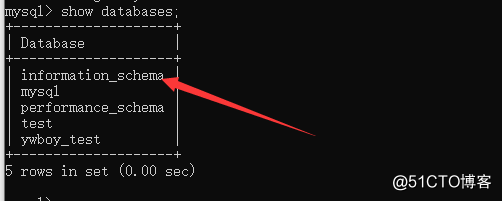
first, we need to use this database use information_schema;
queries after select COLUMN_NAME from COLUMNS;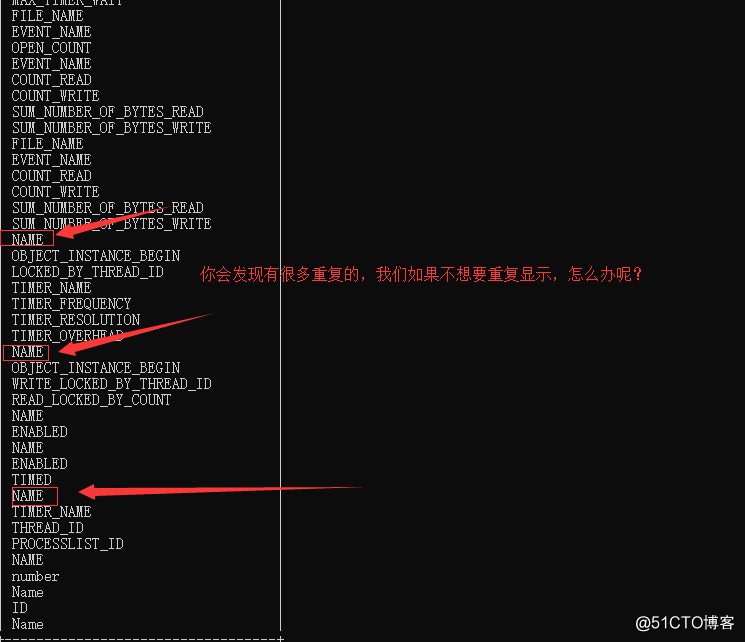
the general use of distinct, screening only one field! this is when a single table select distinct COLUMN_NAME from COLUMNS;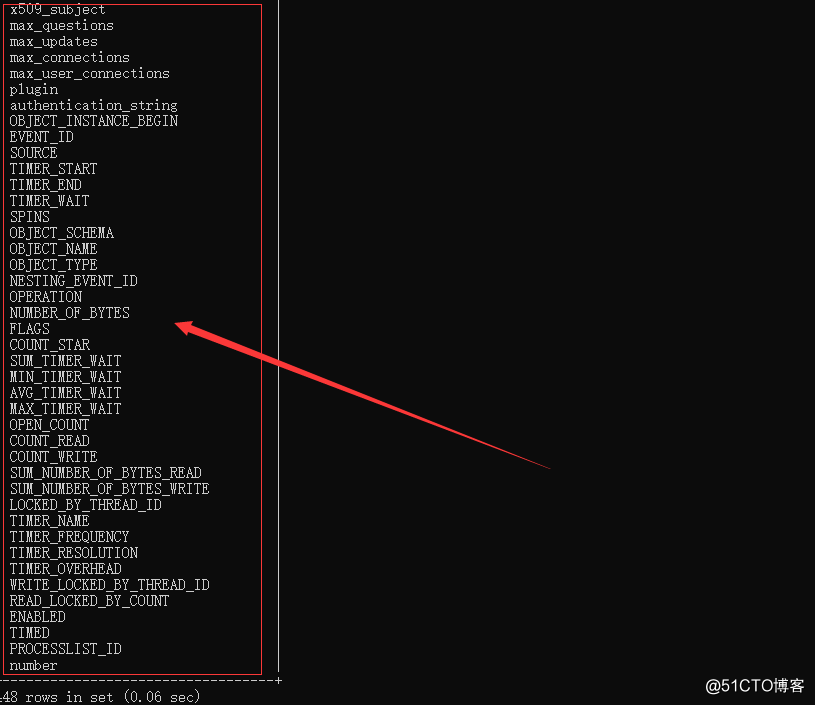
record or a lot, but you will find that duplicate still display will not be like before
2> query conditions
Note: Conditional field compare symbols:
! =, <,>,> =, <=, =, etc. Compare operators
can use across multiple conditions or and so on
where ground conditions behind select * from 表名 where 条件
this demonstration I do not need you to play your own imagination
3> Sort and limit
syntax: order by field name sort
our first fight sequence data chaos, and then sorted 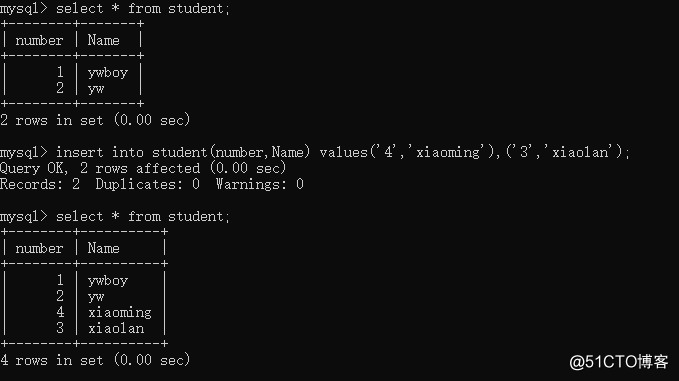
ASC: from low to high, is the default 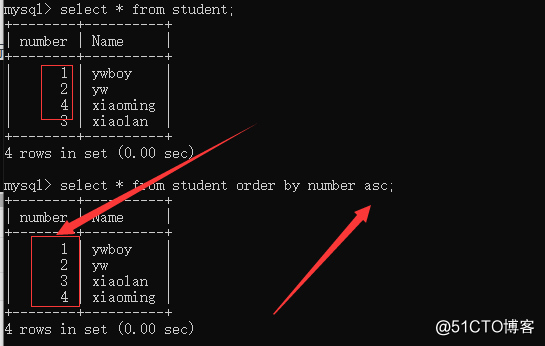
desc: high in the end by a 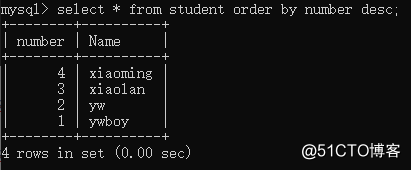
plurality of sort fields 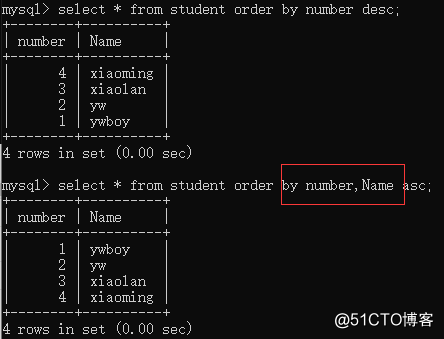
limits:
the rearmost limit plus the statement number 1, number 2 to the number of queries limits.
limit the number 1, number 2 numeral 1 denotes a recording turn taken from the first few (starting from 0), numeral 2 to take a few!
4> polymerization
①sum summing select sum(字段名) from 表名;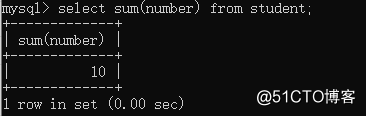
②count total number of recordsselect count(*|字段名) from 表名;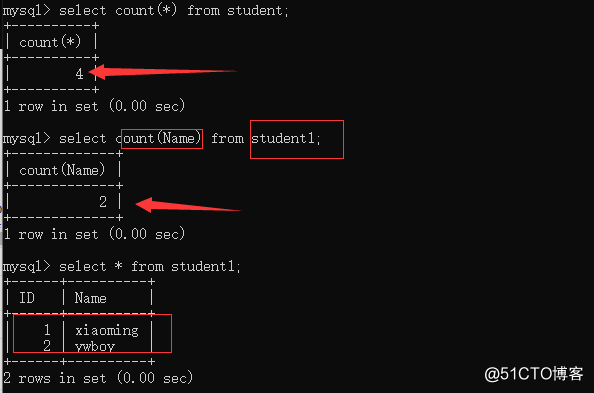
③max maximum select max(字段名) from 表名;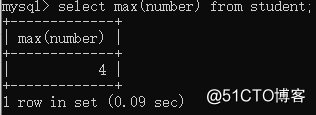
④min minimum select min(字段名) from 表名;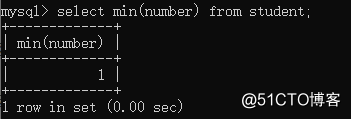
⑤GROUP BY polymerization classification select sum(number),Name from student group by Name;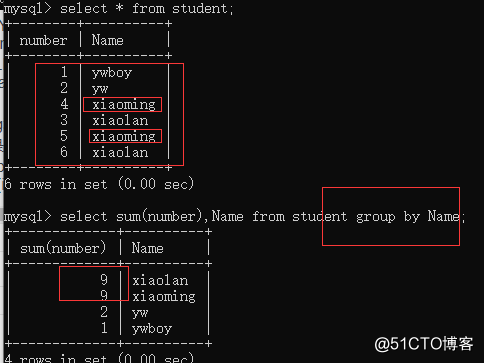
result of re-polymerization ⑥WITH ROLLUP classification summary select sum(number) from student group by Name with rollup;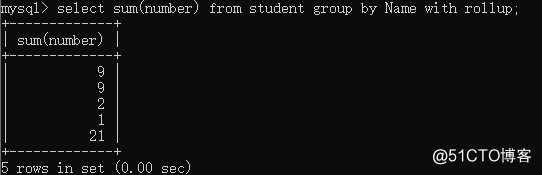
⑦HAVING
NOTE: The difference is that where and HAVING, HAVING is the result of the polymerization conditions for filtering, and where it is recorded prior to polymerization filter, first filter the records should as far as possible! 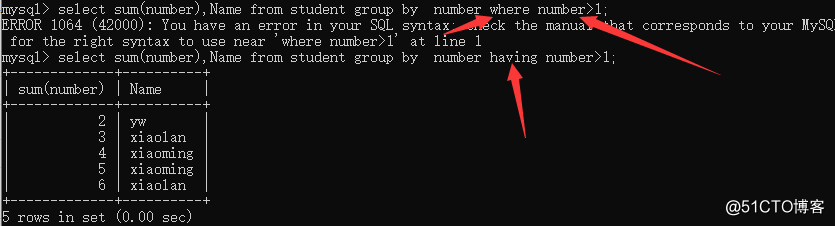
Research studies can own Baidu do not understand! ! ! Or give me a message