1/0 Foreword
Before we explored how a .class file is loaded into the jvm. But within jvm memory is how to divide it? This is loaded into the internal memory of that piece? jvm memory is divided among the interview questions will be asked of a surface.
1/1 What is jvm memory zoning?
In fact, this problem is very simple, when the JVM is running the code we write, he must use more than one memory space, different memory space used to put different data, then write the code with our process, to make our system up and running.
To give a simple example, such as we now know JVM is loaded into memory to class for subsequent runs, then I ask you, after these classes are loaded into memory, where he had put it? I thought about this problem?
So the JVM must have an area of memory used to store the classes we wrote.
We define members including class variables, methods, local variables, etc., have a corresponding record is stored in memory to memory jvm.
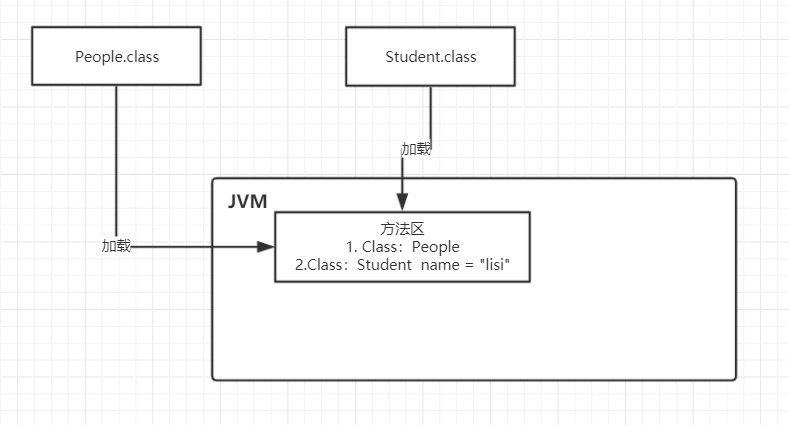
Method class storage area 2/0
In previous versions of JDK1.8, the representative of an area JVM. After the 1.8 version, the name of this area changed, called "Matespace", can be considered a "meta-data space" This means, of course, this is mainly our own store or write information about various classes.
For chestnuts. The following two classes, People no class member variables, and Student class has a class name of the variable.
public class Student{ private static String name = "lisi"; } public class People{ public static void main(){ Student student = new Student(); } }
These two classes are loaded into the JVM, which will be stored in the method area (Note: If you have read my previous chapter, you will understand where the load is represented by: Load -> Authentication -> Prepare -> parse -> All class variables initialized, the class will be assigned). As shown below
3/0 code instructions execute program counter
We know that is loaded into the jvm class object is .class file after we write .java files are compiled.
After compiling our code will be compiled into byte code computer can read. And this .calss document is that we compiled byte code is the code.
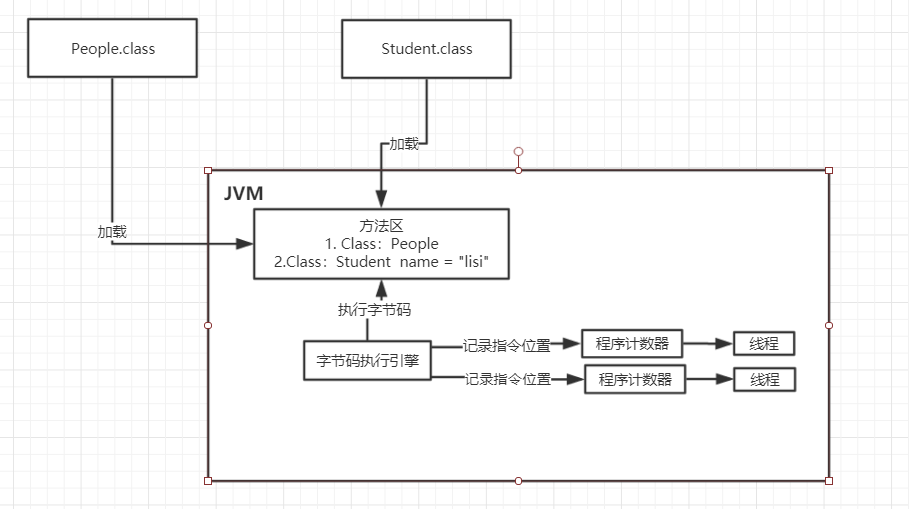
After loading into memory, the bytecode execution engine began to work. We compiled code instructions to execute out, as shown below

At this point the question is, Do we need a memory space to record our current implementation of the bytecode execution engine to which lines of code? This is a special memory area is the "Program Counter"
The program counter is used to record the position of bytecode instructions currently executed.
As shown below:

到这里我相信会有人产生疑惑,就按照当前的代码顺序执行就行了,为什么要记录执行到哪里了?
因为我们写好的代码可能会开启多个线程并发的执行不同的代码。可能当前线程这段代码还没有执行完毕,就上下文切换到另一段代码中。
当线程再次上下文切换到之前的代码时,就需要一个专门记录当前线程执行到了哪一条字节码。所以,每一个线程都有这自己的程序计数器。
如下图:
4/0 java虚拟机栈
java代码在执行的时候,一定是某个线程来执行某个方法中的代码。
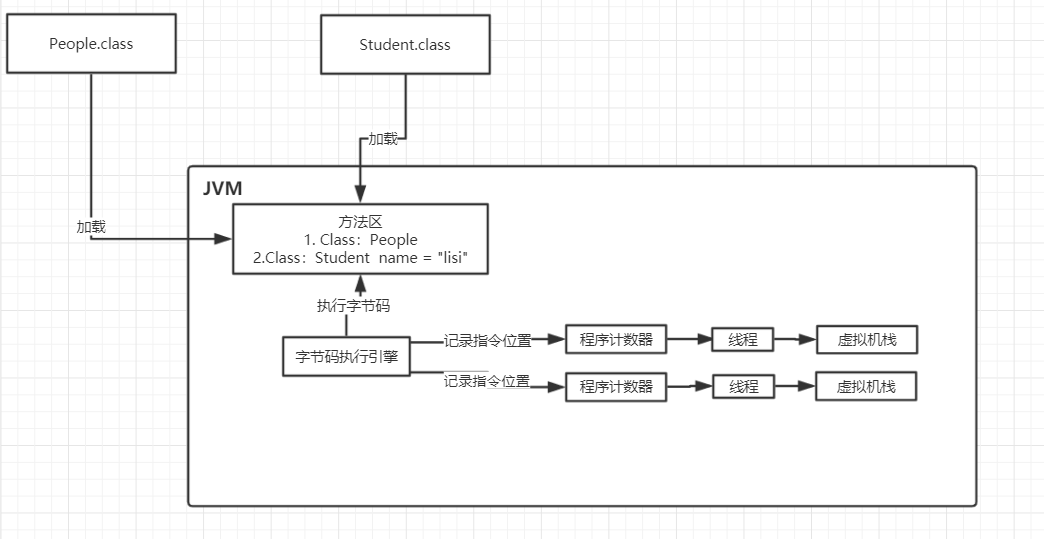
当线程执行到某个方法的时候,如果这个方法有局部变量,那么就需要一块区域来存放局部变量的数据信息。这个区域就叫做java虚拟机栈。
每一个线程都有一个自己的java虚拟机栈,比如说当执行main方法的时候就会有一个main线程,用来存放main方法中定义的局部变量
public static void main(){ People people = new People(); int i = 9; }
比如上面的main()方法中,其实就有一个"people"的局部变量,他是引用一个People的实例对象的,这个对象我们先不管他。然后有一个"i"的局部变量。
如下图:

我想大家应该都知道栈的数据结构,后进先出。当方法执行完毕以后,这个栈桢就会出栈,里面的局部变量信息就会从内存删除。所以局部变量是线程安全的。因为只有当前线程能获取到这个值。
为什么要用后进先出的数据结构?
假设a方法当中同步调用b方法,此时a方法的栈桢先入栈,然后再是b方法的栈桢入栈。b方法执行完毕后,b方法的栈桢出栈,继续执行a方法。所以使用一个后进先出的栈结构是非常完美的。
此时jvm的内存模型图如下:
5/0 java堆内存
这一块内存是非常非常重要的。
我们实例化的所有对象都是存放在这个内存中。这个实例化的对象里面会包含一些数据,我们用上面的代码来做栗子。
public class Student{ private String name = "lisi"; public String getNmae(){ return name; } } public class People{ public static void main(){ Student student = new Student(); student.getName(); } }
还是这个代码,当main线程执行main()方法的时候,首先在堆内存中实例化Student对象,然后在局部变量中创建student,student存的是实例化Student对象的内存地址。然后执行Student对象的getName()方法。
如下图:
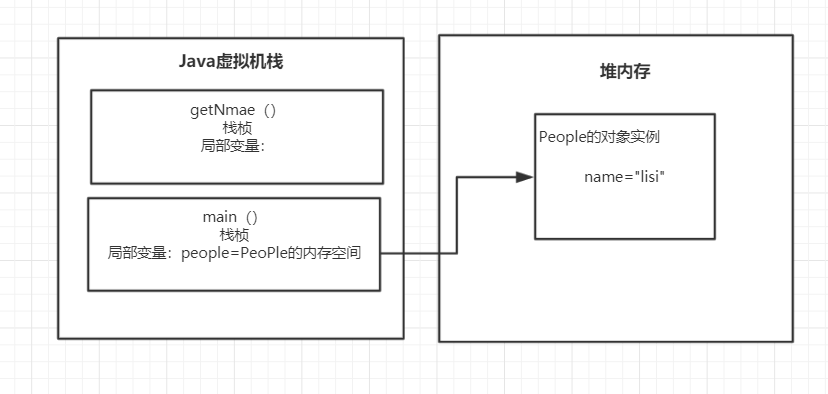
由上图可以看出来,栈空间是封闭的,是线程安全的,而堆内存中是我们主要发生线程不安全的地方,因为堆内存的空间所有的线程其实都是能共享的。
此时jvm的内存划分的最终模型为:
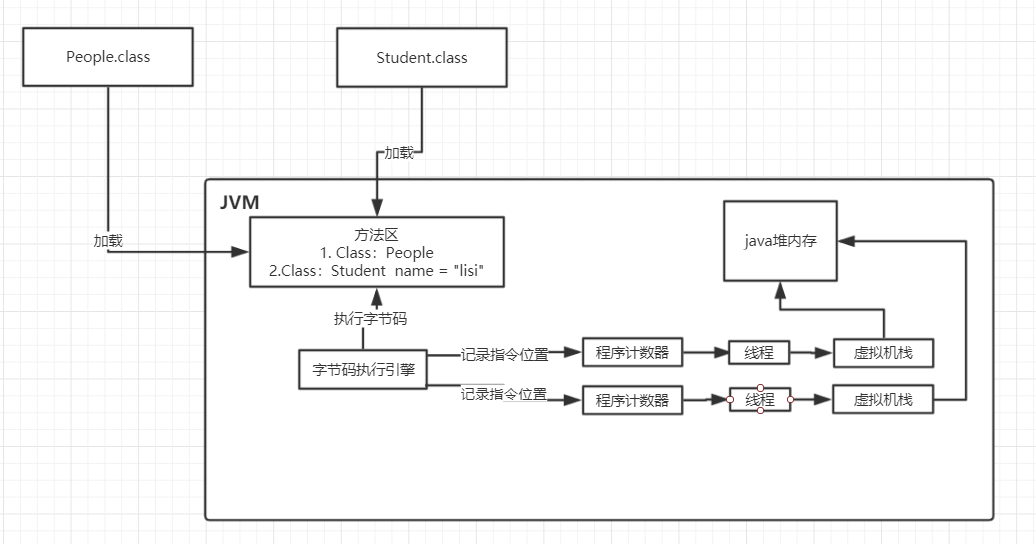
6/0 其他内存区域
很多java程序猿对这一块区域的接触是非常少的。
其实在JDK的很多底层代码API中,比如NIO。
如果你去看源码会发现很多地方的代码不是java写的,而是走的native方法去调用本地操作系统里面的一些方法,可能调用的都是c语言写的方法。
比如说:public native int hashCode();
在调用这种native方法的时候,就会有线程对应的本地方法栈,这个其实类似于java虚拟机栈。也是存放各种native方法的局部变量表之类的信息。
还有一块区域,是不是jvm的,通过NIO中的allocateDirect这种API,可以在jva堆外分配内存空间,然后通过java虚拟机栈里的DirectByteBuffer来引用和操作堆外内存空间。
7/0 总结
基本上jvm的核心内存区域的功能都解释清楚了,面试能回答到这一个地步应该也能顺利通过了。
我们需要重点关注的是方法区,程序计数器,java虚拟机栈和java堆内存这些内存区域的作用