Docker turned out largely to promote the development of the container and heat technology. Container technology and traditional virtualization technologies are very different, including: First, with respect to the traditional virtual machine, a virtual machine before doing things, will be broken into many containers do, their respective functions will less; second point is the previous result of an IP virtual machine becomes a plurality of containers IP number, the relationship between the container becomes more complicated; third network endpoint is the number of points throughout the network presents a upward trend; fourth point is the life cycle of container actually be shorter. In addition, the container due to its lightweight advantage, may be kept scheduling, dispatching from one machine to another machine, according to the resource load balancing, life cycle of container is actually shorter than the virtual confidential. The above points are actually a number of new challenges to the traditional virtual network raised.
This article is a senior architect with the title seven cattle Xu Zhaokui on the 2015 Global Summit architect speech made finishing, divided into three parts. The first part describes the relationship between meaning and SDN and its container. The second part describes some of the existing open source SDN solutions around the container, including Flannel, Calico and Weave. The third part was seven cattle and shared some practical cases this section.
About SDN and containers
As in recent years, a concept relatively hot, we all know is an acronym for Software Defined Network SDN, that is software-defined network. But different people have different understanding of SDN. In a broad sense, as long as you achieve through a software thing, then that thing the flexibility to achieve the above network deployment and scalable, which can be considered SDN. Analyzed later in will Flannel, Calico, Weave these three solutions, and forwarded from the control layer and the layer focuses on their technology, though they do not claim to be SDN solutions.
Since the container virtualization technology to the traditional network presents some new challenges, it created a lot of different network solutions around Docker, Docker to make up deficiencies in these areas.
Open source SDN solutions around the container
Docker own network solution is relatively simple, is that will run a very pure Linux Bridge on each host, the Bridge can be considered a two-story switches, but it has limited capacity and can only do some simple learning and forwarding. Then out of the flow, the flow of the bridge will go IPTABLES, do NAT address translation and then forwards the communication between a host to do by routing. But when it actually use the network model to deploy a more complex business, there will be many problems, such as IP restart after the container had changed; or because each host chance to allocate a fixed network segment, and therefore moved to a container with different when the host, its IP may change, because it is in a different network segment; the same time, the presence of NAT can cause both ends to see each other's address is not true when communicating, because it is too NAT; and NAT itself is also a performance loss and so on. These problems have caused obstacles to the use of Docker own network solution.
Flannel
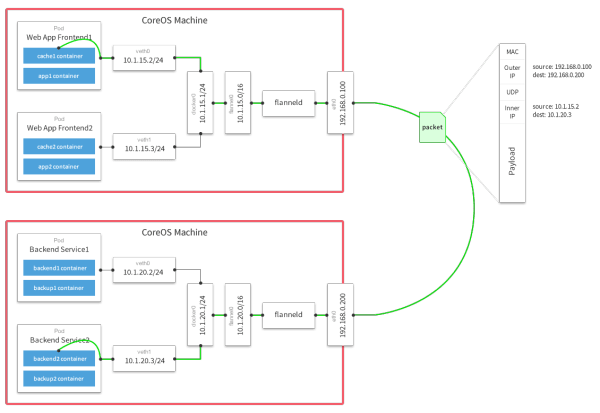
figure 1
CoreOS Flannel is a design team for Kubernetes overlay (Overlay Network) tool, as shown in FIG. The control plane thereof is very simple, as shown in FIG.
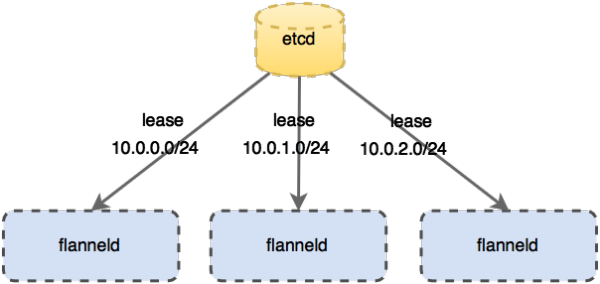
figure 2
Each machine will monitor the process of the above Flannel ETCD, ETCD apply to each node available IP addresses, and get all the other network information from the host ETCD, so that it can do some routing. For its forwarding plane (Figure 3) - forwarding data stream flows mainly plane - it came in the bridge foundation Docker basis, but also created a new device (Figure 4) called the VXLAN, is a VXLAN tunnel scheme, it can be a Layer packet, preceded by a header, and then the entire packet as a packet physical network, to which the physical network to route the circulation.
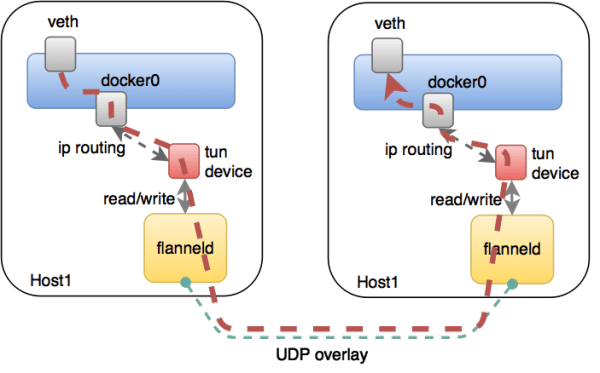
image 3
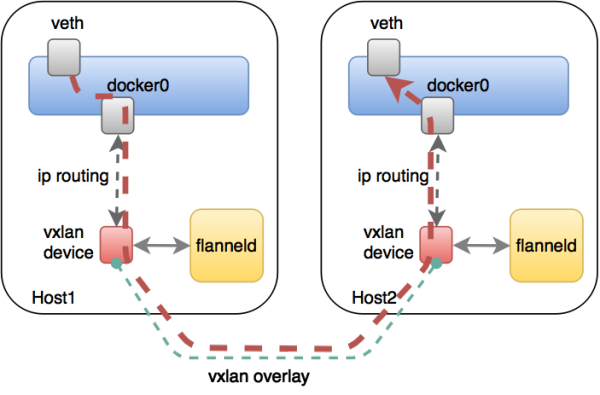
Figure 4
Why have this thing do? Because IP networks are usually virtual and physical network in the MAC actually I do not know. Because the need to identify the physical IP network support, this is actually a tunnel solution.
To summarize Flannel program, you can see that it did not achieve isolation, and it is done in accordance with the allocation of IP network segment, that is, a container moved to another host from one host, its address will change.
Calico
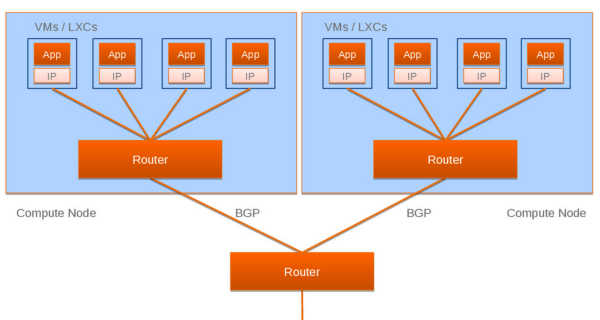
Figure 5
Calico的思路比较新,如图5所示。它把每个操作系统的协议栈认为是一个路由器,然后把所有的容器认为是连在这个路由器上的网络终端,在路由器之间跑标准的路由协议——BGP的协议,然后让它们自己去学习这个网络拓扑该如何转发。所以Calico方案其实是一个纯三层的方案,也就是说让每台机器的协议栈的三层去确保两个容器,跨主机容器之间的三层连通性。对于控制平面(图6),它每个节点上会运行两个主要的程序,一个是它自己的叫Felix,左边那个,它会监听ECTD中心的存储,从它获取事件,比如说用户在这台机器上加了一个IP,或者是分配了一个容器等。接着会在这台机器上创建出一个容器,并将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。绿色部分是一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,你们路由的时候得到这里来。
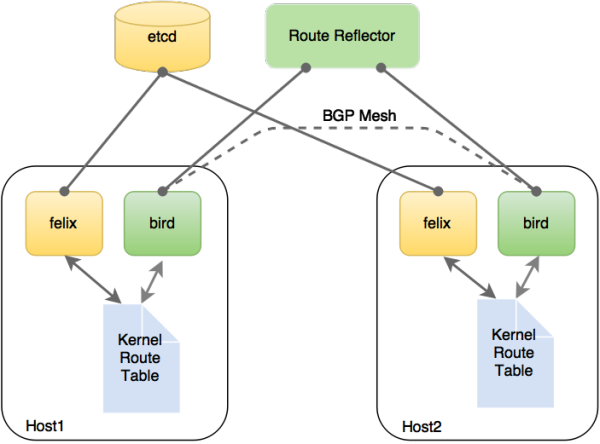
图6
关于Calico这里讨论一个问题,因为它跑的是纯三层的协议,所以其实它对物理架构有一定的侵入性。Calico官方称,你可以跑在一个大二层的网络里面。所谓大二层就是没有任何三层的网关,所有的机器、宿主机、物理机在二层是可达的。这个方案其实有一定的弊端,事实上在很多有经验的网络工程师眼里,一个大二层其实是一个单一的故障率,也就是说任何一个都会有一定的硬件风险会让整个大二层瘫痪。
另外,Calico跑在了一个三层网关的物理网络上时,它需要把所有机器上的路由协议和整个物理网络里面的路由器的三层路全部用BGP打通。这其实会带来一个问题,这里的容器数量可能是成千上万的,然后你让所有物理的路由学习到这些知识,其实会给物理集群里的BGP路由带来一定的压力,这个压力我虽然没有测过,但据专业的网络工程师告知,当网络端点数达到足够大的时候,它自我学习和发现拓扑以及收敛的过程是需要很多的资源和时间的。
转发平面(图7)是Calico的优点。因为它是纯三层的转发,中间没有任何的NAT,没有任何的overlay,所以它的转发效率可能是所有方案中最高的,因为它的包直接走原生TCP/IP的协议栈,它的隔离也因为这个栈而变得好做。因为TCP/IP的协议栈提供了一整套的防火墙的规则,所以它可以通过IPTABLES的规则达到比较复杂的隔离逻辑。
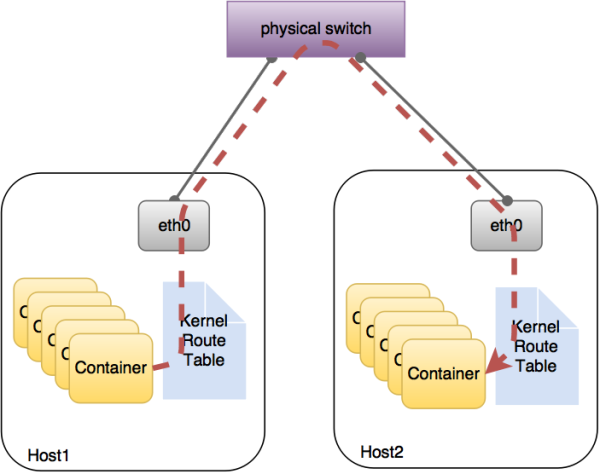
图7
Weave
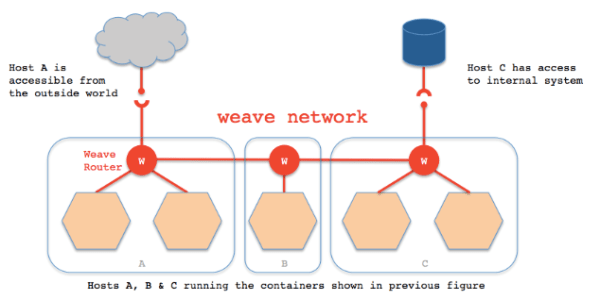
图8
Weave方案比较有趣,如图8所示。首先它会在每台机器上跑一个自己写的Router程序起到路由器的作用,然后在路由器之间建立一个全打通的PC连接,接着在这张TCP的连接网里面互相跑路由协议,形成一个控制平面(图9)。可以看出,它的控制平面和Calico一致,而转发平面(图10)则是走隧道的,这一点和Flannel一致,所以Weave被认为是结合了Flannel和Calico这两个方案的特点。
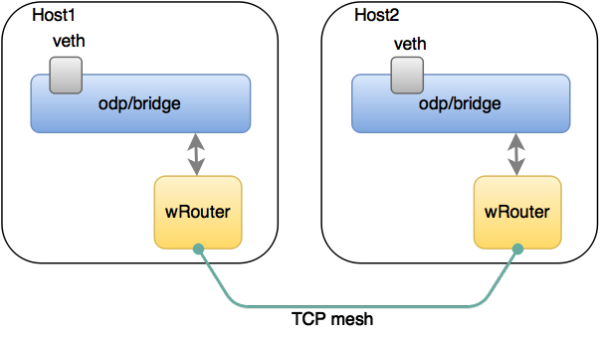
图9
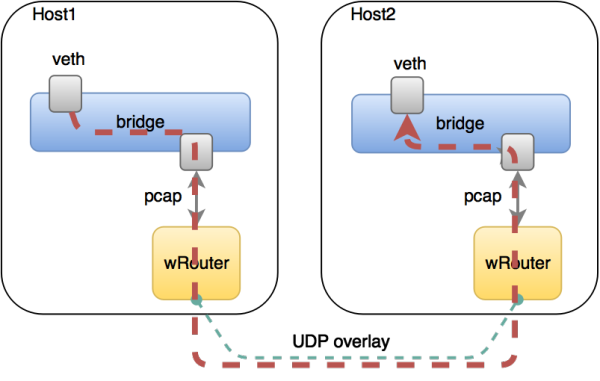
图10
图11所示是它的服务发现与负载均衡的一个简单的方案,它在每个容器会起两个网卡,一个网卡连着自己起的可以跟其他宿主机联通的网桥;另一个网卡绑在原生Docker的一个网桥上,并在这个网桥上监听一个DNS的服务,这个DNS实际上嵌在Router里面,即它可以从Router里学习到一些服务的后端的一些配置。所以这时容器如果发起DNS查询,实际上会被路由导到宿主机上,DNS Server上,然后DNS server做一些响应。它们官方负载均衡也是靠这个,但是这其实是一个短板,因为我们更偏向于四层或者是七层更精细的负载均衡。
在隔离方面,Weave的方案比较粗糙,只是子网级的隔离(图12)。比如说有两个容器都处在10.0.1-24网段,那么它会在所有的容器里面加一条路由说该网段会走左边的网桥出去,但是所有非此网段的流量会走Docker0,这个时候Docker0和其他是不联通的,所以它就达到一个隔离的效果。
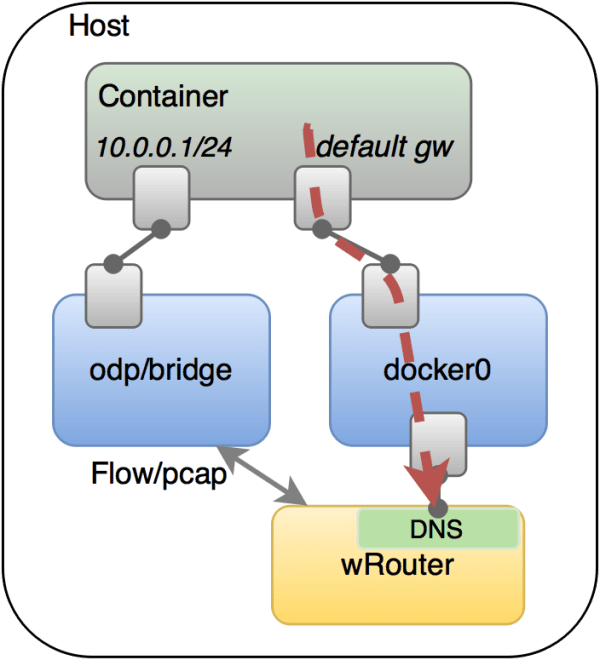
图11
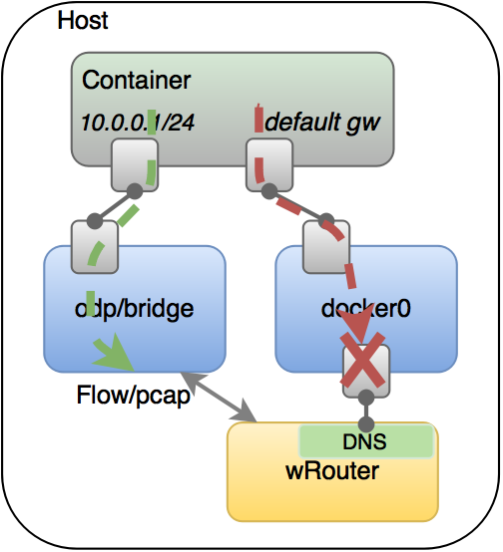
图12
三个方案总结
总结一下:
1. Flannel仅仅作为单租户的容器互联方案还是很不错的,但需要额外的组件去实现更高级的功能,例如服务发现与负载均衡。
2. Calico有着良好的性能和隔离策略,但其基于三层转发的原理对物理架构可能会有一定的要求和侵入性。
3. Weave自带DNS,一定程度上能解决服务发现,但因隔离功能有限,若作为多租户的联通方案还稍加欠缺。
4. 另外,Calico和Weave都使用了路由协议作为控制面,而自主路由学习在大规模网络端点下的表现其实是未经验证的,曾咨询过相关的网络工程师,大规模端点的拓扑计算和收敛往往需要一定的时间和计算资源。
七牛的具体实践
业务需求
七牛实际上一直在拥抱容器带来的变革,拥抱新型的微服务架构理念。所以构建了一套容器平台,这么做的目的,一方面想推进通过将已有业务容器化简化研发和上线流程,另一方面也想通过这个方式去满足用户的一些计算需求,毕竟计算和数据离得越近越好。
所以我们业务上对网络的需求是:
1. 首先一点,是能够运行在底层异构的基础网络上,这一点对于推进已有业务的容器化来说是很重要的,否则会涉及到基础网络的大规模变更,这是无法接受的。
2. 我们试图构造一个对容器迁移友好的网络结构,允许容器在必要情况下发生调度。
3. 我们认为服务发现和负载均衡对业务来说是个基础而普适的需求,尤其是在倡导微服务架构的今天,一个设计良好的组件应该是可水平伸缩的,因此对于组件的调用方,服务发现和负载均衡是非常必要的功能。当然有人会说这个功能和网络层无关,而应由应用层去实现,这个说法挺有道理,但后面我会讲到由网络层直接支持这两个功能的好处。
4. 为了满足七牛本身已有的一些对隔离有要求的服务,并满足上层更丰富的权限模型和业务逻辑,我们试图将隔离性做的更加灵活。
在这几个需求的驱动下,我们最终尝试跳出传统网络模型的束缚,尝试去构造一个更加扁平而受控的网络结构。
转发平面
首先,在转发层面,为了包容异构的基础网络,我们选择了使用Open vSwitch构造L2 overlay模型,通过在OVS之间联通vxlan隧道来实现虚拟网络的二层互通。如图13所示。但隧道通常是有计算成本的,隧道需要对虚拟二层帧进行频繁解封包动作,而通用的cpu其实并不擅长这些。我们通过将vxlan的计算量offload到硬件网卡上,从而将一张万兆网卡的带宽利用率从40%提升到95%左右。
选择overlay的另一个理由是,据我们目前所了解到,当下硬件的设备厂商在对SDN的支持上通常更偏向于overlay模型。
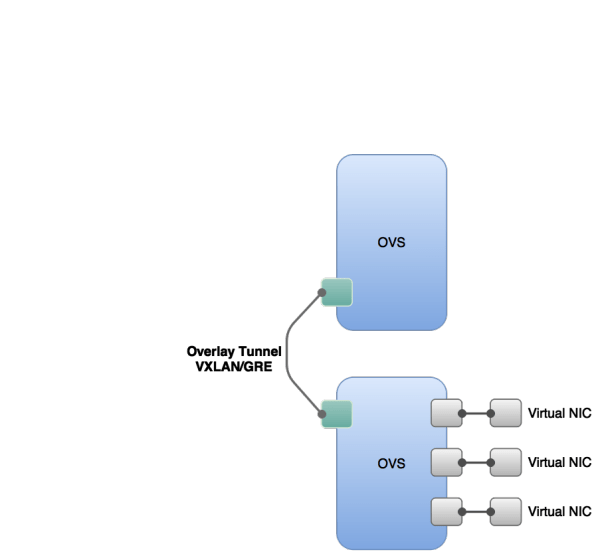
图13
控制平面
而在控制层面,我们思考了容器和传统虚机的一些不同:
前面提到,微服务架构下,每个容器的职责相对虚机来说更加细化和固定,而这会造成容器与容器间的依赖关系也相对固定。那么每台宿主机上的容器可能产生的outbound其实也是可推演的。如果进一步想的话,其实推演出来的理论范围通常会远大于容器实际产生的 outbound。所以我们尝试使用被动的方式实现控制指令的注入。因此我们引入了OpenFlow作为控制面的协议。OpenFlow作为目前SDN 控制平面的协议标准,它有着很强的表达能力。从包匹配的角度看,它几乎可匹配包头中的任意字段,并支持多种流老化策略。此外,扩展性也很好,支持第三方的 Vendor 协议,可以实现标准协议中无法提供的功能OpenFlow可以按Table组织流表,并可在表间跳转(这一点其实和IPTABLES很像,但OpenFlow的语义会更加丰富)。配合OpenFlow的这种Table组织方式,可以实现相对复杂的处理逻辑。如图14所示。
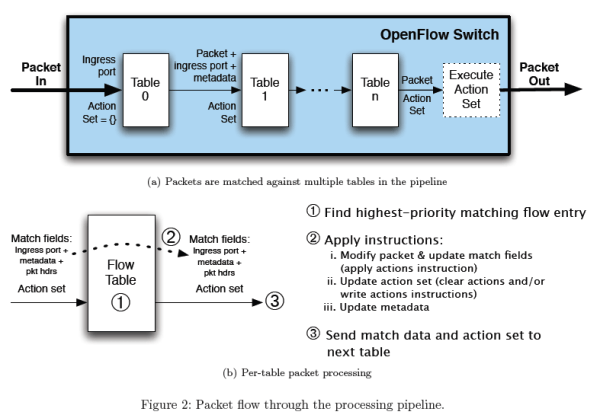
图14
选择了OpenFlow,我们的控制平面会显得很中规中矩,也就是逻辑上的集中式控制,没有weave/calico的P2P那么炫酷。在这样的结构下,当ovs遇到未知报文时,会主动提交包信息给Controller,Controller会根据包信息判断后,给ovs下发合适的流表规则。为了实现负载均衡和高可用,我们给每组ovs配置多个Controller。如图15所示。
例如:
1. 对于非法流量Controller会让ovs简单丢弃,并在将来一段时间内不要再询问。
2. 对于合法流量,Controller会告诉ovs如何路由这个包并最终到达正确的目的地。
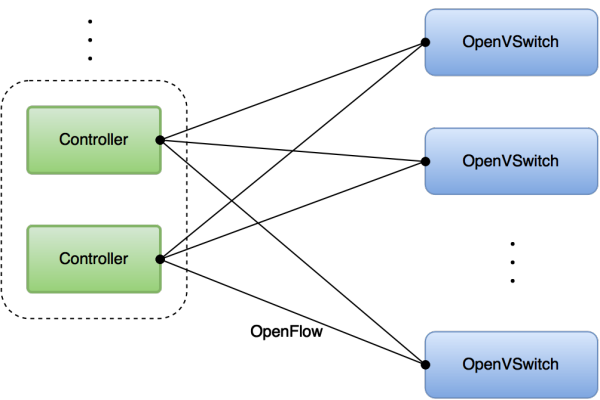
图15
服务发现和负载均衡
关于服务发现和负载均衡,我们提供了以下几个对象模型:
1. Container,容器实例,多个Container构成一个Pod(实体)。
2. Pod,每个Pod共享一个网络栈,IP地址和端口空间(实体)。
3. Service,多个相同Pod副本构成一个Service,拥有一个Service IP(逻辑)。
4. 安全组,多个Service构成一个安全组(逻辑)。
其中,可动态伸缩的关系是一个Service与其后端Pod的映射,这一步是靠平台的自动服务发现来完成。只要发起对Service IP的访问,那么Service本身就会完成服务发现和负载均衡的功能。后端Pod如果发生变动,调用方完全无需感知。
从实现上来说,我们将这个功能实现到了每个宿主机上,每个宿主机上的这个组件会直接代理本机产生的Service流量,这样可以避免额外的内网流量开销。
功能上,我们实现了IP级的负载均衡,什么意思,就是每个Service IP的可访问端口与后端Pod实际监听的端口是一致的,比如后端Pod监听了12345,那么直接访问Service IP的12345端口,即可直接访问,而无需额外的端口配置。
这里对比一下常见的几种负载均衡:
1. 比DNS均衡更加精细。
2. 比端口级的负载均衡器更容易使用,对业务入侵更小。
另外,7层的负载均衡实际上有很大的想象空间,我们实现了大部分Nginx的常用配置,使用者可以灵活配置。业务甚至还可以指定后端进行访问。
安全组
在隔离层面,我们在逻辑上划分了安全组,多个service组成一个安全组,安全组之间可以实现灵活的访问控制。相同安全组内的容器可以互相不受限制的访问。其中最常见的一个功能是,将安全组A中的某些特定的Service Export给另一组安全组B。Export后,安全组B内的容器则可以访问这些导出的Service,而不能访问A中的其他Service。如图16所示。
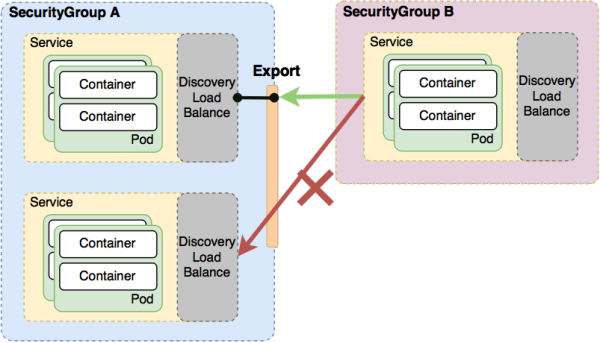
图16
介绍完了我们网络的基础功能,这里通过分析两个七牛的实际案例来说明这样的结构是如何推动业务的架构演变的。
案例分析1——七牛文件处理FOP架构演变
第一个是七牛的文件处理架构(File OPeration),如图17所示。文件处理功能一直是七牛非常创新、也是很核心的一个功能,用户在上传了一个文件后,通过简单地在资源url中添加一些参数,就能直接下载到按参数处理后的文件,例如你可以在一个视频文件的url中添加一些参数,最终下载到一张在视频某一帧上打了水印并旋转90度并裁剪成40x40大小的图片。
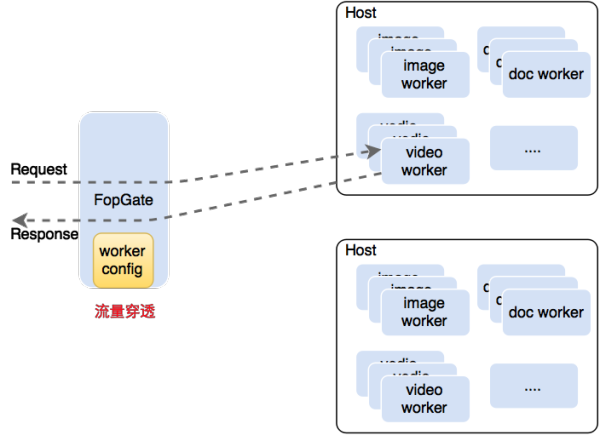
图17
而支撑这样一个业务的架构,在早期是非常笨拙的。图17左侧是业务的入口,右侧是实际进行计算的各种worker集群,里面包含了图片处理,视频处理,文档处理等各种处理实例。
1. 集群信息写死在入口配置中,后端配置变更不够灵活。
2. 业务入口成为流量穿透的组件(业务的指令流与数据流混杂在一起)。
3. 突发请求情况下,应对可能不及时。
后面负责文件处理的同事将架构进化成了这样(如图18)。
1. 增加Discovery组件,用于集群中worker信息的自动发现,每个worker被添加进集群都会主动注册自己。
2. 业务入口从Discovery获取集群信息,完成对请求的负载均衡。
3. 每个计算节点上新增Agent组件,用于向Discovery组件上报心跳和节点信息,并缓存处理后的结果数据(将数据流从入口分离),另外也负责节点内的请求负载均衡(实例可能会有多个)。
4. 此时业务入口只需负责分发指令流,但仍然需要对请求做节点级别的负载均衡。
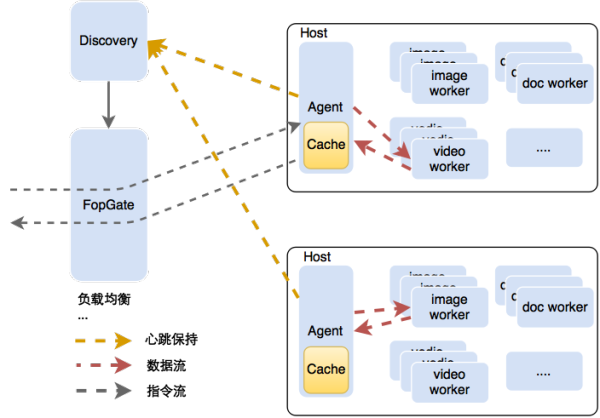
图18
图19描述的是文件处理架构迁移到容器平台后的早期结构,较迁移之前有如下变更。
1. 每个Agent对应一个计算worker,并按工种独立成Service,比如Image Service,Video Service。
2. 取消业务的Discovery服务,转由平台自身的服务发现功能。
3. 每个Agent的功能退化:
l 无需和Discovery维护心跳,也不在需要上报节点信息。
l 由于后端只有一个worker,因此也不需要有节点内的负载均衡逻辑。
4. 业务入口无需负载均衡,只需无脑地请求容器平台提供的入口地址即可。
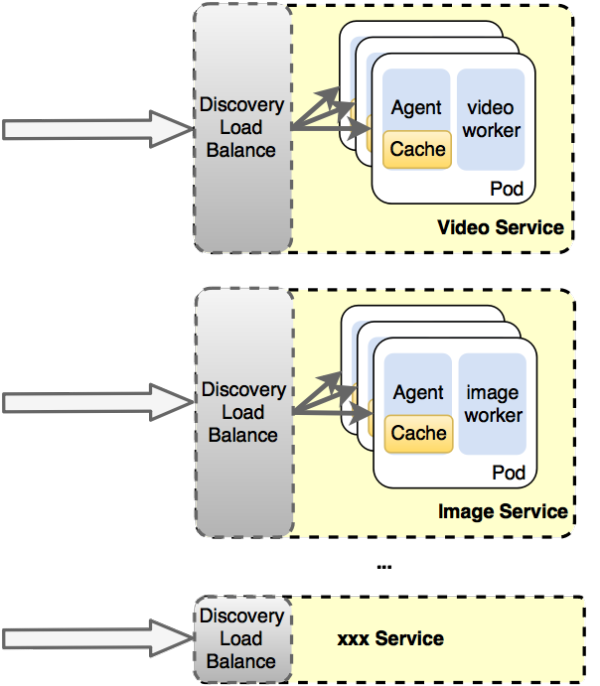
图19
图20是迁移后发生的另一次演变,实际上上一个阶段中,每个Agent仍然和计算实例绑定在一起,而这么做其实只是为了方便业务的无痛迁移,因为Agent本身的代码会有一些逻辑上的假设。
这张图中,我们进一步分离了Agent和worker,Agent独立成一个Service,所有的worker 按工种独立成Service,这么分离的目的在于,Agent是可能会有文件内容缓存、属于有状态的服务,而所有的worker是真正干活、无状态的服务。分离之后的好处在于,worker的数量可以随时调整和伸缩,而不影响Agent中携带的状态。
好处:
1. 可以看到,相比于最早的架构,业务方只需集中精力开发业务本身,而无需重复造轮子,实现各种复杂的服务发现和各种负载均衡的代码。
2. 另外,自从部署到容器平台之后,平台的调度器会自动更具节点的资源消耗状况做实例的迁移,这样使得计算集群中每个节点的资源消耗更加均衡。
案例分析2——用户自定义文件处理UFOP架构演变
另一个案例是七牛的用户自定义文件处理。
用户自定义文件处理(User-defined File OPeration,UFOP)是七牛提供的用于运行用户上传的文件处理程序的框架。他的作用实际上和前面介绍的是一致的,只是允许用户自定义他的计算实例。例如七牛现有的鉴黄服务,就是一个第三方的worker,可以用于识别出一个图片是否包含黄色内容。而正是由于引入了用户的程序,所以UFOP在架构上和官方的 FOP的不同在于,UFOP对隔离有要求。
图20是原本UFOP的架构,事实上,这里已经使用了容器技术进行资源上的隔离,所有的容器通过Docker Expose将端口映射到物理机,然后通过一个集中式的注册服务,将地址和端口信息注册到一个中心服务,然后入口分发服务通过这个中心服务获取集群信息做请求的负载均衡。
而在网络的隔离上,由于Docker自身的弱隔离性,这个架构中选择了禁止所有的容器间通信,而只允许入口过来的流量。这个隔离尺度一定程度上限制了用户自定义程序的灵活性。
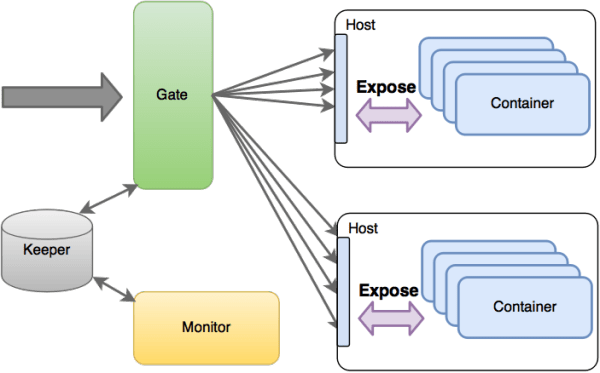
图20
而在迁移到容器平台后,由于有灵活的安全组控制,不同用户上传的处理程序天然就是隔离的,而用户可以创建多种职责不同的Service来完成更复杂的处理逻辑。如图21所示。
另外,迁移后的程序将拥有完整的端口空间,进一步放开了用户自定义处理程序的灵活性。
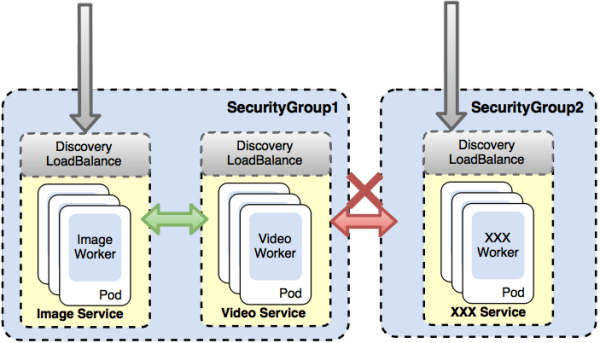
图21
以上内容是七牛首度公开关于多租户虚拟网络方面的探索和实践,并总结了我们对这一领域的观察和思考,还有很多更为细节的点值得探讨,望以后能与大家做更充分的交流。