In recent summer training to participate in big data, record it to learn something.
introduction
Lazy learning: simple data storage and waits until a given test data before proceeding Fan of order and test data are classified according to the similarity of the training tuples stored. Lazy learning only a small amount of work in the training tuples, and do more work during the classification or value prediction. Laziness learning or memory tuple training instances, also called case-based learning .
K- nearest neighbor: belong lazy learning, given a training data set, centralized find examples of instances with unknown nearest K training focused on the training data, the majority of the K instance belongs to a class, put the unknown examples of this class to the classification.
Algorithm Description:
1, data standardization
2, calculating the distance between the respective test data and training data
3, sorted in order of increasing distance relationship
4, select the smallest distance K points
5, before determining the point at which the K classes in frequency of occurrence
6, the highest frequency class prediction classified as the test data is returned occurred before the K points
Three basic elements of K nearest neighbor algorithm: selecting the k value, a measure of distance, the classification decision rule
First, data standardization
Role : to prevent an attribute weight is too large
For example, the coordinates of the point x, y. X in the range [0, 1], but the range is [y] 100, 1000, conducting its calculation of the distance y when the weights important than the right to x.
Here it is the most simple of a standardized method:
Min-max Standardization: X '= (X -min) / (max-min)
for example:
data set x [1, 2, 3, 5], the min = 1, max = 5
1: (1-min) / (max-min) = 0
2: (2-min) / (max-min) = 00:25
3: (3-min) / (max-min) = 0.5
5: (5 min) / (max-min) = 1
The data set is updated to x x '[0, 0.25, 0.5, 1]
Min-max method of x 'is normalized in [0, 1] interval
Second, the distance metric
Calculating a distance from Continental, Manhattan distance and the like, Euclidean distance is generally used.
Euclidean distance formula:
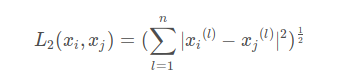
For example it is (x1, y1) and (x2, y2) of the distance

Multidimensional is the same, subtracting the corresponding coordinates, squared, summed, and then Root No.
Manhattan Distance:
Manhattan distance formula:
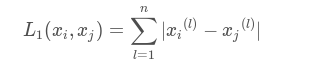
Point (x1, y1) and (x2, y2) Manhattan distance: | X1-X2 | + | Y1-Y2 |
Multidimensional corresponding subtraction sum of the absolute coordinates
Selected according to the needs of different distance measures
In determining the K value
The results will select the k-nearest neighbor k values have a great impact, the k value means that only small training examples closer and enter the instance will work to predict the results, but prone to over-fitting; if the value of k greater advantage is to reduce the estimation error learning, learning disadvantage approximation error increases, then the training examples farther from the input instance also predict the prediction error. In practice, a selected k value is generally smaller value, cross-validation method to select the optimal value of k.
Fourth, the classification decision rule
Classification decision rule is only to determine which category the current instance according to what rules.
k-nearest neighbor algorithm, the classification decision rule is often a majority vote, that is determined by the K nearest training examples input instance of the class with input category instance.
Fifth, the advantages and disadvantages
Pros: Simple, easy to understand, no modeling and training, easy to implement; suitable for rare events are classified.
Cons: Lazy algorithm, large memory overhead, the calculation of the amount of the test sample classification is relatively large, lower performance; interpretability poor, can not give that kind of decision tree rule.