Today Content:
a remaining portion of Selenium
two BeautifulSoup4
a remaining portion Selenium
1. interworking elements:
- Click, remove
the Click
Clear
- ActionChains
is a chain of action objects, the driver needs to drive it to pass.
Action chain object can operate a series of actions to set a good behavior.
- iframe switching
driver.switch_to.frame ( 'iframeResult')
- js code execution
execute_script ()
Crawling Jingdong product information
Primary Version #:
! # From Tank
# '' '
# Import Time
# Import Selenium from the webdriver
# Import Keys from selenium.webdriver.common.keys
#
# = Driver webdriver.Chrome ()
#
# =. 1 NUM
#
# the try:
# driver.implicitly_wait (10)
# # jingdong transmission request to
# driver.get ( 'https://www.jd.com/')
#
# # jingdong Home input box to Murphy's Law, and press enter
# input_tag = driver.find_element_by_id ( 'Key')
# input_tag.send_keys ( 'Murphy's Law')
# input_tag.send_keys (Keys.ENTER)
#
# the time.sleep (. 5)
#
#
# good_list = driver.find_elements_by_class_name ( 'GL-Item' )
# in good_list Good for:
Print # # (Good)
# # Product Name
# good_name = good.find_element_by_css_selector ( '. P-name EM'). Text
# # Print (good_name)
#
# # Product link
# good_url = good.find_element_by_css_selector ( '. P -name A '). get_attribute (' the href ')
# # Print (good_url)
#
# # commodity price
# good_price = good.find_element_by_class_name ('. price-P '). text
# # Print (good_price)
#
# # product evaluation
# good_commit = good.find_element_by_class_name ( 'the commit-P') text.
#
# good_content = F '' '
# NUM: NUM} {
# product name: good_name} {
# product link:{good_url}
# Product Price: good_price} {
# Product Evaluation: good_commit} {
# \ n-
# '' '
#
# Print (good_content)
#
# with Open (' jd.txt ',' A ', encoding =' UTF-. 8 ') F AS:
# f.write (good_content)
# = NUM +. 1
#
# Print ( 'product information successfully written!')
#
#
# the finally:
# driver.close ()

'' '
Intermediate EDITION
' ''
# Import Time
# Import Selenium from the webdriver
# Import Keys from selenium.webdriver.common.keys
#
# = Driver webdriver.Chrome ()
#
# =. 1 NUM
#
# the try:
# driver.implicitly_wait ( 10)
## to send a request jingdong
# driver.get ( 'https://www.jd.com/')
#
# # jingdong Home input box to Murphy's Law, and press enter
# input_tag = driver.find_element_by_id ( 'Key')
# input_tag.send_keys ( 'Murphy's Law')
# input_tag.send_keys (Keys.ENTER)
#
# the time.sleep (. 5)
#
# # drop-down sliding 5000px
# js_code = '' '
# the window.scrollTo (0 5000)
# '''
#
Driver.execute_script # (js_code)
#
# # wait 5 seconds for the data loading product
# the time.sleep (. 5)
#
# = good_list driver.find_elements_by_class_name ( 'GL-Item')
# in good_list for Good:
# # Print (Good )
# # product name
# good_name = good.find_element_by_css_selector ( '. P-name EM'). text
## Print (good_name)
#
# # product link
# good_url = good.find_element_by_css_selector ( '. p -name a'). get_attribute ( 'the href')
# # Print (good_url)
#
# # commodity price
# good_price = good.find_element_by_class_name ( '. price-P'). text
# # Print (good_price)
#
# # product reviews
Good.find_element_by_class_name good_commit = # ( 'the commit-P') text.
#
# Good_content = F '' '
# NUM: NUM} {
# Product Name: good_name} {
# Product link: good_url} {
# Product Price: {good_price}
# product evaluation: good_commit} {
# \ n-
# '' '
#
# Print (good_content)
#
# with Open (' jd.txt ',' A ', encoding =' UTF-. 8 ') AS F:
# f.write (good_content)
# NUM + = 1
#
# Print ( 'product information is written successfully!')
#
# # find and click Next
# next_tag = driver.find_element_by_class_name ( 'the pn-the Next')
# next_tag.click()
#
# time.sleep(10)
#
# finally:
# driver.close()


'''
狂暴版
'''
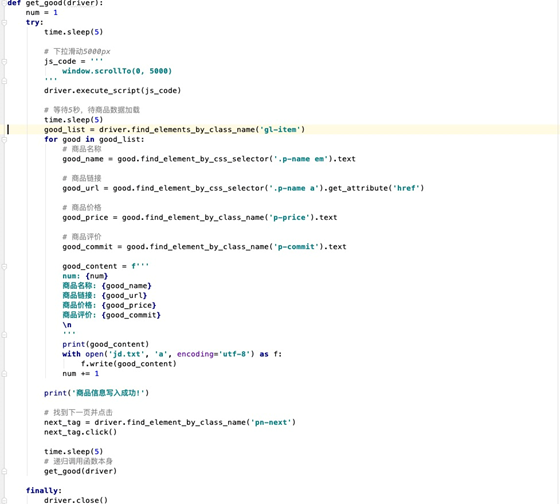
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
def get_good(driver):
num = 1
try:
time.sleep(5)
# 下拉滑动5000px
js_code = '''
window.scrollTo(0, 5000)
'''
driver.execute_script(js_code)
# 等待5秒,待商品数据加载
time.sleep(5)
good_list = driver.find_elements_by_class_name('gl-item')
for good in good_list:
# 商品名称
good_name = good.find_element_by_css_selector('.p-name em').text
# 商品链接
good_url = good.find_element_by_css_selector('.p-name a').get_attribute('href')
# 商品价格
good_price = good.find_element_by_class_name('p-price').text
# 商品评价
good_commit = good.find_element_by_class_name('p-commit').text
good_content = f'''
num: {num}
商品名称: {good_name}
商品链接: {good_url}
商品价格: {good_price}
商品评价: {good_commit}
\n
'''
print(good_content)
with open('jd.txt', 'a', encoding='utf-8') as f:
f.write(good_content)
num += 1
print('商品信息写入成功!')
# 找到下一页并点击
next_tag = driver.find_element_by_class_name('pn-next')
next_tag.click()
time.sleep(5)
# 递归调用函数本身
get_good(driver)
finally:
driver.close()
if __name__ == '__main__':
driver = webdriver.Chrome()
try:
driver.implicitly_wait(10)
# 往京东发送请求
driver.get('https://www.jd.com/')
# 往京东主页输入框输入墨菲定律,按回车键
input_tag = driver.find_element_by_id('key')
input_tag.send_keys('墨菲定律')
input_tag.send_keys(Keys.ENTER)
# 调用获取商品信息函数
get_good(driver)
finally:
driver.close()

bs4搜索文档树
find: 找第一个
find_all: 找所有
标签查找与属性查找:
name 属性匹配
name 标签名
attrs 属性查找匹配
text 文本匹配
标签:
- 字符串过滤器
字符串全局匹配
- 正则过滤器
re模块匹配
- 列表过滤器
列表内的数据匹配
- bool过滤器
True匹配
- 方法过滤器
用于一些要的属性以及不需要的属性查找。
属性:
- class_
- id
'''
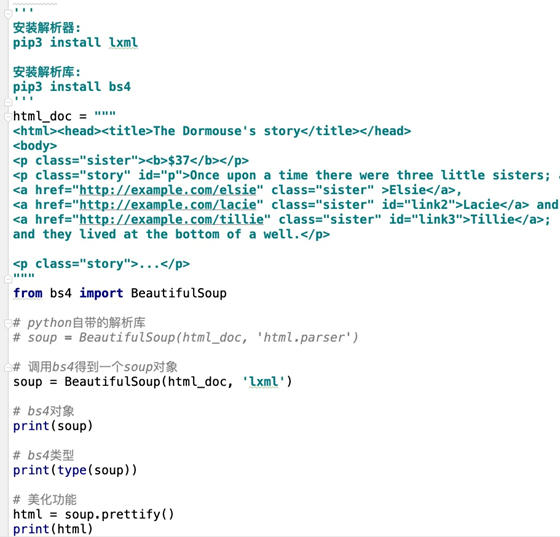
html_doc = """
<html><head><title>The Dormouse's story</title></head><body><p class="sister"><b>$37</b></p><p class="story" id="p">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class="sister" >Elsie</a><a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>and they lived at the bottom of a well.</p><p class="story">...</p>
"""
from bs4 import BeautifulSoup
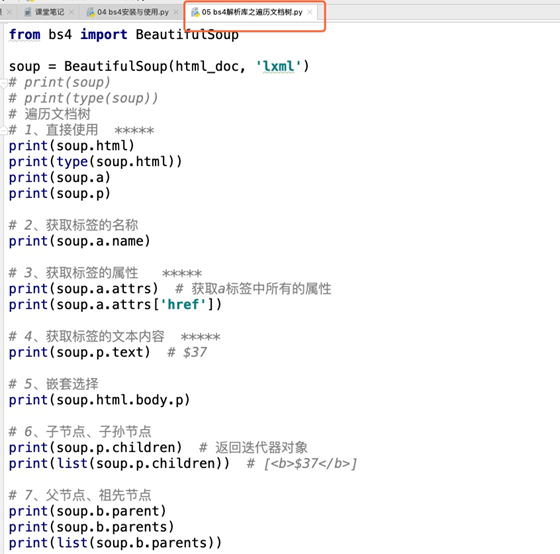
soup = BeautifulSoup(html_doc, 'lxml')
# name 标签名
# attrs 属性查找匹配
# text 文本匹配
# find与find_all搜索文档
'''
字符串过滤器
'''
p = soup.find(name='p')
p_s = soup.find_all(name='p')
print(p)
print(p_s)
# name + attrs
p = soup.find(name='p', attrs={"id": "p"})
print(p)
# name + text
tag = soup.find(name='title', text="The Dormouse's story")
print(tag)
# name + attrs + text
tag = soup.find(name='a', attrs={"class": "sister"}, text="Elsie")
print(tag)
'''
- 正则过滤器
re模块匹配
'''
import re
# name
# 根据re模块匹配带有a的节点
a = soup.find(name=re.compile('a'))
print(a)
a_s = soup.find_all(name=re.compile('a'))
print(a_s)
# attrs
a = soup.find(attrs={"id": re.compile('link')})
print(a)
# - 列表过滤器
# 列表内的数据匹配
print(soup.find(name=['a', 'p', 'html', re.compile('a')]))
print(soup.find_all(name=['a', 'p', 'html', re.compile('a')]))
# - bool过滤器
# True匹配
print(soup.find(name=True, attrs={"id": True}))
# - 方法过滤器
# 用于一些要的属性以及不需要的属性查找。
def have_id_not_class(tag):
# print(tag.name)
if tag.name == 'p' and tag.has_attr("id") and not tag.has_attr("class"):
return tag
# print(soup.find_all(name=函数对象))
print(soup.find_all(name=have_id_not_class))
# 补充知识点:
# id
a = soup.find(id='link2')
print(a)
# class
p = soup.find(class_='sister')
print(p)