http://www.cnblogs.com/artech/archive/2007/08/24/868956.html
In the first part , we discuss the APPLY and CTE two T-SQL Enhancement. APPLY realized the Table and TVF the Join, CTE by creating a "temporary View" way to simplify the problem. We now proceed to discuss two other important SQL Enhancement of the Items-T: PIVOT and Ranking .
Three, PIVOT Operator
PIVOT in Chinese means "pivot", such as for a 2 -dimensional coordinate, the abscissa becomes ordinate, the abscissa ordinate becomes. Reflected in a Relational Table on the means: to become a column, change as a line. I believe during the report design when we have encountered similar to this demand: Statistics 2002 the number of orders for the first quarter of the year a sales staff processed each month. In AdventureWorks Sample Databse in the Sales the Order is stored in SaleOrderHeader this table, the results of which are as follows:
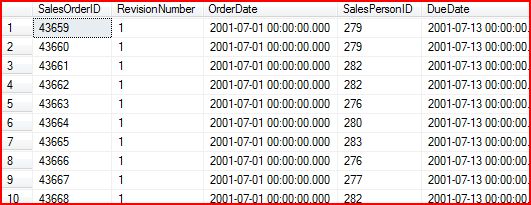
We generally by the following SQL achieve statistical functions we propose:
 SELECT
SalesPersonID,
SUM
(
CASE
DATEPART
(MM,OrderDate)
WHEN
1
THEN
1
ELSE
0
END
)
AS
JAN,
SUM
(
CASE
DATEPART
(MM,OrderDate)
WHEN
2
THEN
1
ELSE
0
END
)
AS
FEB,
SUM
(
CASE
DATEPART
(MM,OrderDate)
WHEN
3
THEN
1
ELSE
0
END
)
AS
MAR,
SUM
(
CASE
DATEPART
(MM,OrderDate)
WHEN
4
THEN
1
ELSE
0
END
)
AS
APR
FROM
Sales.SalesOrderHeader
WHERE
DATEPART
(yyyy,OrderDate)
=
2002
GROUP
BY
SalesPersonID
SELECT
SalesPersonID,
SUM
(
CASE
DATEPART
(MM,OrderDate)
WHEN
1
THEN
1
ELSE
0
END
)
AS
JAN,
SUM
(
CASE
DATEPART
(MM,OrderDate)
WHEN
2
THEN
1
ELSE
0
END
)
AS
FEB,
SUM
(
CASE
DATEPART
(MM,OrderDate)
WHEN
3
THEN
1
ELSE
0
END
)
AS
MAR,
SUM
(
CASE
DATEPART
(MM,OrderDate)
WHEN
4
THEN
1
ELSE
0
END
)
AS
APR
FROM
Sales.SalesOrderHeader
WHERE
DATEPART
(yyyy,OrderDate)
=
2002
GROUP
BY
SalesPersonID
So we got this statistics:
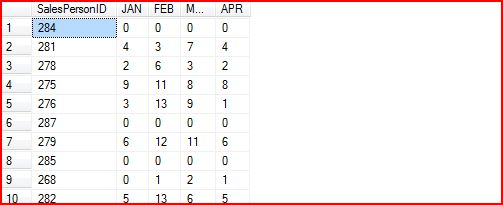
The results were compared in the structure of the original table and we finally obtained the data, we find that like the "spin" of 90 degrees, the original OrderDate is based on each line stored in the Order of an attribute (line), and now we want to Order Date according to statistics in different months, this column into a row.
Like this demand, we can can PIVOT to achieve this operator, the following is based PIVOT of SQL :
SELECT
SalesPersonID,
[
1
]
AS
JAN,
[
2
]
AS
FEB,
[
3
]
AS
MAR,
[
4
]
AS
APR
FROM
(
SELECT
SalesPersonID,
DATEPART
(MM,OrderDate)
AS
MON
FROM
Sales.SalesOrderHeader
WHERE
DATEPART
(yyyy,OrderDate)
=
2002
) SPIVOT (
COUNT
(MON)
FOR
MON
IN
(
[
1
]
,
[
2
]
,
[
3
]
,
[
4
]
))
AS
P
在上面的例子中,同过下面的SELECT语句筛选出来的是为经过PIVOT的数据。
SELECT
SalesPersonID,
DATEPART
(MM,OrderDate)
AS
MON
FROM
Sales.SalesOrderHeader
WHERE
DATEPART
(yyyy,OrderDate)
=
2002
通过下面的PIVOT(COUNT(MON)是我们需要统计的数据,FOR MON IN ([1],[2],[3],[4]是统计的范围)就成了我们最终输出的结构了。
PIVOT (
COUNT
(MON)
FOR
MON
IN
(
[
1
]
,
[
2
]
,
[
3
]
,
[
4
]
))
如果你第一次见到PIVOT,可以不能一下明白它的实现,但是只要你是使用了一两次,相信就会很容易地掌握它。与PIVOT对应的还以一个操作符UNPIVOT,它完成PIVOT的逆操作,在这里就不介绍了,如果有兴趣的话,可以参考SQL Server Books Online。
四、 Ranking
排序与排名是我们最为常用的统计方式,比如对班级的学生根据成员进行排名,或者按照成绩高低把学生划分成若干梯队:比如最好成绩的10名学生属于第一梯队,后10名又划分为第二梯队,以此类推。Ranking设计的Key Words包括:ROW_NUMBER(),RANK(),DENSE_RANK(),NTILE()。我们现在就来介绍一下他们的用法和相互之间的差异。
1. 1. ROW_NUMBER()
看到ROW_NUMBER(),我想绝大多数人会像想到Oracle的ROWNUM。他们的作用相似,都是表示某条记录所处的Index。ROW_NUMBER()比Oracle的ROWNUM更加强大的是,它可以通过OVER语句指定一个进行排序的Column,比如:ROW_NUMBER() OVER (ORDER BY CustomerID)。
我们来看一个例子:对Sales.SalesOrderHeader按照CustomerID进行排序,并显示每条记录的Row Number。
SELECT
SalesOrderID,CustomerID,ROW_NUMBER()
OVER
(
ORDER
BY
CustomerID)
AS
RowNum
FROM
Sales.SalesOrderHeader
下面是查询结果:
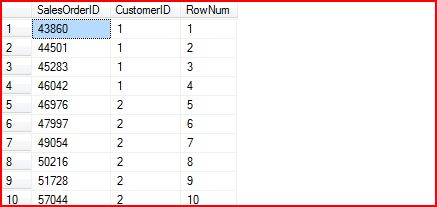
我们发现最终的结果按照CutomerID进行排序,RowNum从1开始以此递增,每条记录(不管是否具有相同的CustomerID)拥有不同的RowNum。
提到排序,我们就不得不提到Order BY,如果我们在后面加上ORDER BY,并指定不同的排序字段,会出现怎样的结果呢?
SELECT
SalesOrderID,CustomerID,ROW_NUMBER()
OVER
(
ORDER
BY
CustomerID)
AS
RowNum
FROM
Sales.SalesOrderHeader
ORDER
BY
SalesOrderID
查询获得的结果是:
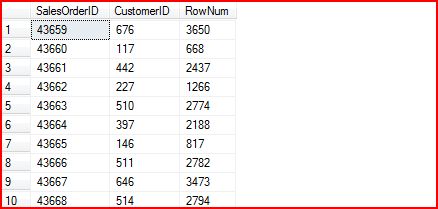
从上图中可以看到,最终的结果以ORDER BY中指定的SalesOrderID进行排序,但是ROW_NUMBER()体现的值却是基于CustmerID排序的。
由于ROW_NUMBER()体现是基于某个确定的字段进行排序后某个DataRow所处的位置,所以它不能直接使用到Aggregate的Column中。比如下面的SQL是不合法的:
SELECT
CustomerID,
COUNT
(
*
)
AS
OrderCount,ROW_NUMBER()
OVER
(
ORDER
BY
OrderCount)
FROM
Sales.SalesOrderHeader
GROUP
BY
CustomerID
要是想按照OrderCount,可以使用第一部分介绍的CTE:
WITH
CTE_Order(CustomerID,OrderCount)
AS
(
SELECT
CustomerID,
COUNT
(
*
)
AS
OrderCount
FROM
Sales.SalesOrderHeader
GROUP
BY
CustomerID)
SELECT
CustomerID,OrderCount,ROW_NUMBER()
OVER
(
ORDER
BY
OrderCount)
FROM
CTE_Order
2. RANK()
RANK()的使用和ROW_NUMBER()类似。不过它与ROW_NUMBER()所不同的是:对于被指定为排序的字段,具有相同值得Row对应的返回值相同。比如:
SELECT
SalesOrderID,CustomerID,RANK()
OVER
(
ORDER
BY
CustomerID)
AS
RowNum
FROM
Sales.SalesOrderHeader
下面是相应的查询结果:
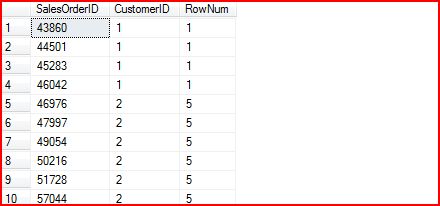
对于RANK(),还有一点需要说明的是,它的回返值不是连续的, 比如第五条记录的Row_Num是5而不是2。如果想实现这样需求,就需要用下面一个Function:DENSE_RANK()。
3. 3. DENSE_RANK()
DENSE_RANK()实现了一个连续的Ranking。比如下面的SQL:
SELECT
SalesOrderID,CustomerID,DENSE_RANK()
OVER
(
ORDER
BY
CustomerID)
AS
RowNum
FROM
Sales.SalesOrderHeader
就来产生如下的查询结果: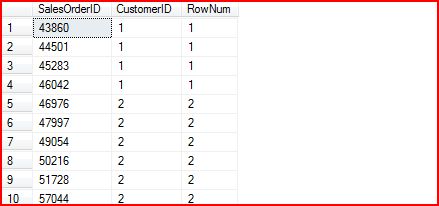
4. NTILE()
上面我们说到划分梯队的问题,这样的问题可以通过NTILE() Function来实现。比如我们现在按照CustomerID排序,把CustomerID为1和2的划分到3梯队中:
SELECT
SalesOrderID,CustomerID,NTILE(
3
)
OVER
(
ORDER
BY
CustomerID)
AS
RowNum
FROM
Sales.SalesOrderHeader
WHERE
CustomerID
<
3
其查询结果为:
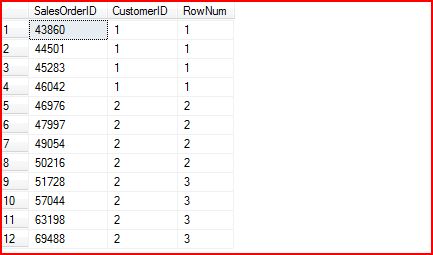
我们可以看到,一共12条记录,划分为3组,平均下来每组4条记录。
5. 5.PARTITION BY
上面提到的所有Ranking都是基于真个结果基的。而有的时候我们需要将真个结果集按照某个Column 进行分组,进行基于组的Ranking。这就需要PARTITION BY了。PARTITION BY置于OVER Clause中,和ORDER BY 平级。
比如下面的SQL将Order记录按照CustomerID进行分组,在每组中输出排名(安OrderDate排序):
SELECT
SalesOrderID,CustomerID,RANK()
OVER
(PARTITION
BY
CustomerID
ORDER
BY
OrderDate)
AS
RowNum
FROM
Sales.SalesOrderHeader
Corresponding query results: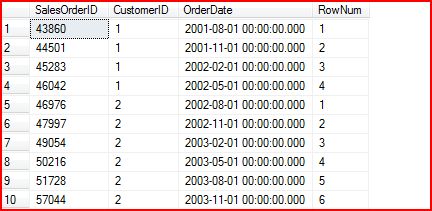
Reproduced in: https: //www.cnblogs.com/flysun0311/archive/2010/05/17/1737550.html